之前简单了解过云计算(云服务器+云存储),容器云(Docker+K8S),以及简单的理解数据分析和炼金术(AI). 但是真正落到分布式,特别是文件存储上. 它们到底是什么关系呢? 很多的概念名词,hadoop,hive,hdfs,spark,strom,es,cd都涌上来了. 急需一篇梳理一下大体关系的笔记.
于是这篇就开始起航了… 更新: 07-04大量补充
0x00.云计算
1.早期历史
这个之前已经介绍的比较多了,个人觉得最易懂的解释就是以前自家门口”挖井取水” –> “水厂集中供水”,我们不需要关心水是从哪来,资源够不够之类的问题. 其实是一种分散式变成了集中式的转变. 注意分布式跟分散式是显然不一样的. 其它就不多说了..
云计算名词(cloud computing)源自google在2006年提出… 但最早提供云服务产品的是Amazon,这也可以理解为什么AWS是现在最大的云服务厂商. 然后google是现在开源界云计算最大的技术巨头?(个人猜测)然后引用一张比较好的图对比从物理机–>虚拟化–>云计算机的差别:
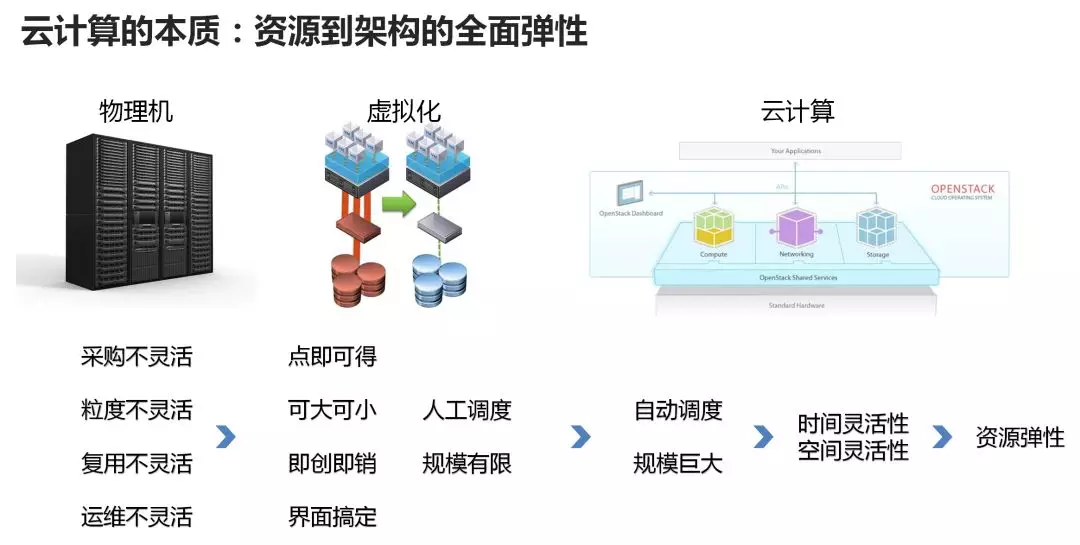
这里有个观点比较有意思:
仅凭虚拟化软件所能管理的物理机的集群规模都不是特别大,一般在十几台、几十台、最多百台这么一个规模,这只能叫虚拟化;
有一个调度中心,几千台机器都在一个池子里面,无论用户需要多少CPU、内存、硬盘的虚拟电脑,调度中心会自动在大池子里面找一个能够满足用户需求的地方,把虚拟机启动起来做好配置,用户就直接能用了。这个阶段我们称为池化或者云化。这个阶段,才可以称为云计算 (www)
AWS因为CEO的远见利用开源的KVM/Xen虚拟化技术加上自建闭源的云平台,很快成为了云计算市场的老大,闷声发大财…. 但是老二 Rackspace 就不开心了,赚不到上面钱的rs,受到刺激后做出了一个非常重要的决定,和NAS一起创办了开源的OpenStack 云平台. 这个也就是后来各大IT公司开启云计算的基础.
云计算提出的时候,有三层圣经一般的结构(在docker里也提过) : SaaS,PaaS,IaaS. 这里不再单说…也无需死记. 然后部署方式根据公网 / 内网 /混合也有三个对应的名词 –> 公有云/私有云/混合云. (我的观点是提名词可以,炒概念就没意思了..)
2.拥抱服务(容器)
上面说到的早期云平台其实重点关注的一直是各种资源的分配, 某个人需要一台xxx配置的机器. 但是这样其实还是会浪费大量资源, 可能一台50G存储,8G内存,2核的CPU就是单纯跑了一个nginx前端页面.(:
但是我们也许更倾向花更少的价钱,换来一个够用就行的的资源,就像大家在北上广买不起别墅,就只能买房,买不起整间房,就考虑到胶囊公寓的形式. 有一张很形象的图,代表了从虚拟机到容器的迁移:
物理机时期:

虚拟机时期:

容器时期:

如果能很好地理解上面三张图,关于云计算的面向服务化发展我相信就能有很好的认识了. 除了资源的粒度进一步细分外,它还能帮助解决一个弹性的问题. 如图:
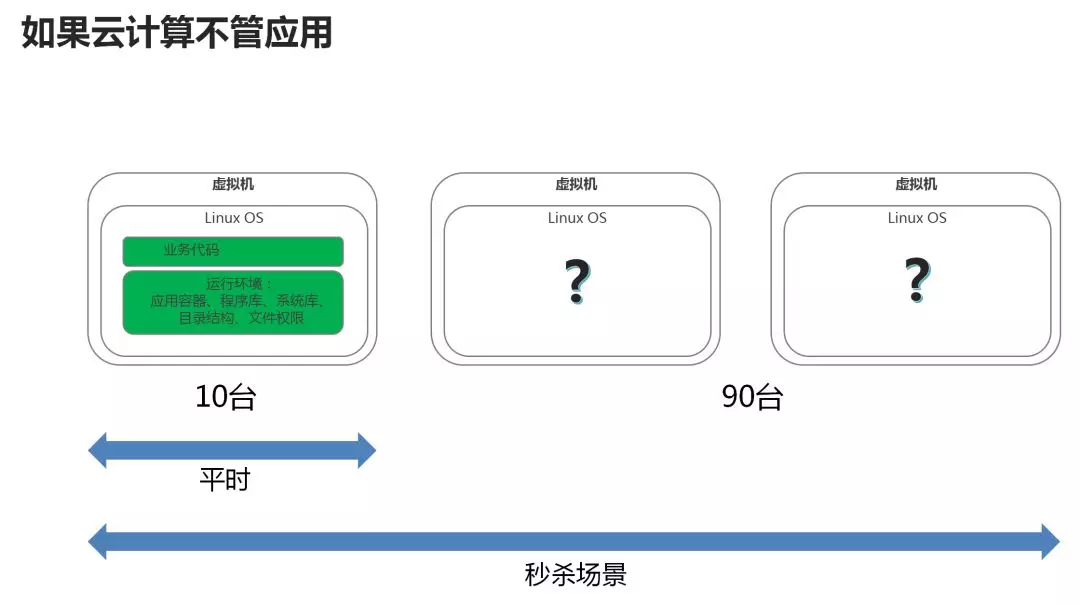
以上的描述, 我们可以简单理解为云计算就是尽可能高效简单的提供计算能力,好比我们小学的时候很羡慕的Casio高级计算器…那么它具体在计算什么呢? 目前来看,本质是算数据(包括不限于数据分析,挖矿,炼金,各种大数据并发系统等等..).特别是海量的,复杂的数据,也就是下面要说的大数据.
0x01.X数据
不知从什么时候开始,我不太喜欢
大数据这个词了… (可能是因为某些砖家? ) 觉得说出AI,大数据,云计算,AR之类的就显得自己很高x上,其实什么也不懂. 反而让技术本身变了味. (这是前言吐槽,无关~)
那接着上面说正题,以前学数据库(db)的时候可能大家都觉得很low,因为最传统的关系型就是建表,连接到后端,然后写sql语句…. 数据这个概念其实很模糊,可能简单理解就是db中的一行吧..
随着人人都会上网了,数据量并发从万级别到亿级别,存储量从亿可能到了万亿..(甚至更多)的时候,传统存储系统就很难存储,查找,分析了. 大数据的特点就是 : 海量数据,类型复杂 ,并且需要快速实时的处理.那么这里还要说一个概念 : 结构化/非结构化数据
- 结构化数据 : C语言中的结构体(?),字符流,各种基本类型等. 有固定可描述的结构(Json,XML其实也算)
- 非结构化数据 : 视频/音频/文件 等二进制字节流.没有特定结构
然后说完这,现在海量的数据里结构与非结构化混杂,我们并不需要海量的垃圾数据. 而且是要根据有用数据. 怎么分辨有用数据? 怎么使用有用数据 ? 这就是数据挖掘/数据分析了.
A.数据分析
DA很重要…主要是商业价值的确很高,它主要分几个方面:
- 可视化分析 (用图表或者大屏幕让人觉得很酷炫…当然也很直观)
- 数据挖掘(如何挖掘有用数据,主要是算法研究)
- 行为预测 (有用户数据怎么使用?)
- 炼金术(也就是AI,把数据挖掘找到的有用数据加以训练优化. 使之后挖掘更高效.本质也是算法)
总之这一块其实本质是用户心理学和算法 (个人意见),所以不擅长的时候暂时不多提了.点到为止
B.分布式计算
本来是想把分布式单独出来说,后来想了一下如果没有海量数据,其实也不需要什么分布式…毕竟单机就能做得又快又好的事,也没人会折腾到分布式. (因为分布式也有几个大难题). 分布式核心来说是两个方面: 计算 & 存储 .然后息息相关,这里先说计算.
计算核心分两种 : 集中式分布式. 集中式很好理解就是把资源集中在一个东西上面.比如某台集中式服务器一台就几千核心.. 分布式是想法很美好的理念,把一个任务(海量数据)先打散拆为n份,分发到n个机器上,然后每台机器可能只用算 1/n 的数据量,最后再利用分布式系统把它们汇聚起来整合. 举几个形象例子,方便理解:
- 孙悟空号召地球上所有人出力,然后聚集起了元气弹 (这到底是集中式还是分布式呢? 我倾向分布式)
- CTF比赛有20道题,有神奇小子这种顶级hacker一个人做所有… 也有常见的几个人组队分组做题然后汇总. (集中式 与分布式…唔,集中了IQ)
- 以前X青们喜欢说的….国人一人一口水,就淹了xx国. (分布式)
那么可以看出来,分布式的想法是很美好的…毕竟神奇小子也好,孙悟空也好
(如果真能轻易像聚集元气弹那样). 但是很多的问题/难题. 包括不限于性能损失/文件打散/汇聚完整性/一致性等等.. 由此提出了经典的CAP原则只能取其二的概念.(之后会说)
C.分布式存储
待填坑。。。可以先参考一下之前的云存储的部分,因为云存储基本多是分布式的.
8.23更新: 以下文章也很值得分布式学习参考, 并且写的很精炼
0x02.AI
由于目前的炼金术(AI)个人觉得离化学还有点远, 因为本质上还是通过数据去不断的模仿训练,就好比计预测第二天的天气一样… 并没有什么过多特别的点,纯因为之前计算力不足,数据不够. 所以20年前就炒的差不多的东西现在又重新焕发了生机….
当然不可否认,时势造英雄. 但是本质来看就是拟合函数的炼金术, 觉得还需要静待它的沉淀和升华.(神经/脑学科真正突破)
0x0n.补充知识点
大数据的技术基础:MapReduce、Google File System和BigTable
2003年到2004年间,Google发表了MapReduce、GFS(Google File System)和BigTable三篇技术论文,提出了一套全新的分布式计算理论。 (后来被称为分布式三驾马车)
MapReduce是分布式计算框架,GFS(Google File System)是分布式文件系统,BigTable是基于Google File System的数据存储系统,这三大组件组成了Google的分布式计算模型。
Google的分布式计算模型相比于传统的分布式计算模型有三大优势:首先,它简化了传统的分布式计算理论,降低了技术实现的难度,可以进行实际的应用。其次,它可以应用在廉价的计算设备上,只需增加计算设备的数量就可以提升整体的计算能力,应用成本十分低廉。最后,它被Google应用在Google的计算中心,取得了很好的效果,有了实际应用的证明。
后来,各家互联网公司开始利用Google的分布式计算模型搭建自己的分布式计算系统,Google的这三篇论文也就成为了大数据时代的技术核心。
主流的三大分布式计算系统:Hadoop,Spark和Storm
由于Google没有开源Google分布式计算模型的技术实现,所以其他互联网公司只能根据Google三篇技术论文中的相关原理,搭建自己的分布式计算系统。
Yahoo的工程师Doug Cutting和Mike Cafarella在2005年合作开发了分布式计算系统Hadoop。后来,Hadoop被贡献给了Apache基金会,成为了Apache基金会的开源项目。Doug Cutting也成为Apache基金会的主席,主持Hadoop的开发工作。
Hadoop采用MapReduce分布式计算框架,并根据GFS开发了HDFS分布式文件系统,根据BigTable开发了HBase数据存储系统。尽管和Google内部使用的分布式计算系统原理相同,但是Hadoop在运算速度上依然达不到Google论文中的标准。
不过,Hadoop的开源特性使其成为分布式计算系统的事实上的国际标准。Yahoo,Facebook,Amazon以及国内的百度,阿里巴巴等众多互联网公司都以Hadoop为基础搭建自己的分布式计算系统。
Spark也是Apache基金会的开源项目,它由加州大学伯克利分校的实验室开发,是另外一种重要的分布式计算系统。它在Hadoop的基础上进行了一些架构上的改良。Spark与Hadoop最大的不同点在于,Hadoop使用硬盘来存储数据,而Spark使用内存来存储数据,因此Spark可以提供超过Hadoop100倍的运算速度。但是,由于内存断电后会丢失数据,Spark不能用于处理需要长期保存的数据。
Storm是Twitter主推的分布式计算系统,它由BackType团队开发,是Apache基金会的孵化项目。它在Hadoop的基础上提供了实时运算的特性,可以实时的处理大数据流。不同于Hadoop和Spark,Storm不进行数据的收集和存储工作,它直接通过网络实时的接受数据并且实时的处理数据,然后直接通过网络实时的传回结果。
Hadoop,Spark和Storm是目前最重要的三大分布式计算系统,Hadoop常用于离线的复杂的大数据处理,Spark常用于离线的快速的大数据处理,而Storm常用于在线的实时的大数据处理。
更新: 最新Apache Flink 打算统一在线和离线计算 …