先丢这慢慢补充之后,部署的文档在JanusGraph+Elasticsearch+Cassandra的文章里面. 这个也可以看做是列式/BigTable存储的一个入门, 并且严格来说BigTable/LSM 并不等于列式存储. 初学会觉得似是而非
0x00.前言
分布式的名词概念挺多,但是慢慢梳理之后其实也就几类,所以我们需要反复的对比,以加深巩固基本的印象,免得上来就被一堆名词搞得晕头转向.
并且列出cd的竞争对手或改进产品. 比如ScyllaDB(Scylla读音接近:sila~) ,然后比较亲切的是csd(cassandra)使用的是CQL这种DSL查询语言, 很类似SQL。 但是要注意的是底层实现原理是完全不一样的 ,后续会补充说.
0x01.Schema结构
这里schema结构是一个类似mysql中表+事务+存储过程+…的组合,schema的上层是database了。 了解清楚csd的结构会对理解后续有很大裨益。 至于它跟janus对接的图我在Janus-Schema已经说过,可以查看, 这里补充说说容易误解的地方.
我们可以把Cassandra/Hbase的数据记录方式也想成K-V 的结构, 只不过这个Value, 还要进一步划分为C-V. 以及一个自带的时间戳参数. 给个表: (注意1001和1002是id, 他们跨行拥有两个V. 因为md的表格没法合并)
| K | V(竖着看) | |
|---|---|---|
| 1001 | column=name ,value= jin,timestamp=17xxxxxxxx01 | |
| column=age,value= 22,timestamp=17xxxxxxxx13 | ||
| 1002 | column=name ,value= xiao,timestamp=17xxxxxxxx03 | |
| column=age,value= 18,timestamp=17xxxxxxxx15 |
这里name 和age 就是两个列(column), 只不过这个列里不只有一个值, 而是多元组, 我们把这个映射到表中就是这样的:
| key | name | age |
|---|---|---|
| 1001 | jin,17xxxxxxxx01 | 22,17xxxxxxxx13 |
| 1002 | xiao,17xxxxxxxx03 | 18,17xxxxxxxx15 |
0x02.上手
之前Cassandra这一块一直处于看结构状态,始终不得要领,因为没有实际操作,总是感觉差了很多感觉,今天趁着机会来补一下..首先,它的cql语句很类似sql,那么自然是显然看看keyspace(db)结构之类的.
1 | #cqlsh工具位于 path/to/Cassandra/bin下 |
所以我觉得这个时候狂敲命令真的是不太合理,那么找一下类似Navicat的可视化界面吧.然后发现它 .下载NoSQL Manager for Cassandra. 然后启动后先选30天试用. (后面后期crack一下).
过期后的Crack (可选)
1 | #无限使用30天,也就是过30天执行以下两步. |
7.31更新: 捕获了一下这个破解的过程, 本质大体是
- 从注册表读取安装信息值,包含第一次启动时的日期. (如果能知道注册表加密方式,并修改为一个2100年的日期就等于永久试用了)
- 读取本地配置文件
appConfig.xml中的<FirstRun>元素确定是否超过30天试用期 (这个时间会与注册表信息比较,所以你单纯修改FirstRun元素值是没有用的, 因为每次会check更新) - 其他配置和连接信息也存在
appConfig.xml中 , 注意尾部</ROOT>后还有一个加密串, 有点像二次Check机制, 所以重新生成后建议保留新的加密串 .(删前备份好ROOT元素内的信息. 之后crack完复制到ROOT中间就可以恢复了).
(*) 网上还有一种crack方法是使用RunAsDate指定时间(100年后?). 不知道具体如何实施, 就没有单独尝试
打开简单连接一下,就能看到很类似老款mysql图形工具的感觉,瞬间觉得亲切多了…建议修改配置:
- 主题改为
Caramel. - 取消
Show start page at startup - 勾上
User F5 key to query
0x03.什么是列DB
我们知道Cassandra和Hbase是最常见的列数据库, 并且也属于NoSQL数据库范畴, 那么这里不同于K-V型或Json /其他文档型的DB很好看出区别, 列DB和关系型DB乍一看还是很有点相似的, 这里先说一下根本上的区别, 方便快速理解. 关键就是理解行/列DB的区别, 以及K-C-V 的概念.
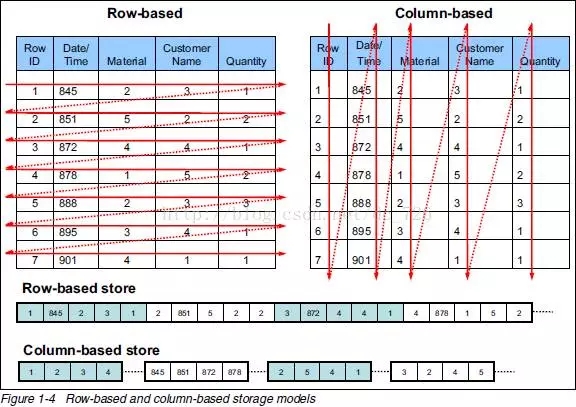
在Mysql这种传统行数据库中, 一张表比如
student,它除了有一个主键key, 其他的列都是属性字段, 然后数据的值都像数组一样紧挨着, 串起来以行为单位存储(比如id1 --> sex1 --> name1 / id2-->sex2 -->name2 / ....这样 )而列数据库假设同样有这三个字段, 他们的存储是竖着的, 也就是说
id1 --> id2 --> id3.. / sex1--> sex2 --> sex3 .../ name1--> name2 -->name3 ->...可以发现明显的区别了吧, 就好比横着切和竖着切的区别. 这个理解了之后你就会想, 横着一串代表一个学生不挺好的么, 为什么要竖着切反而不好理解了? 这就是由于关键的问题——**海量数据**的出现.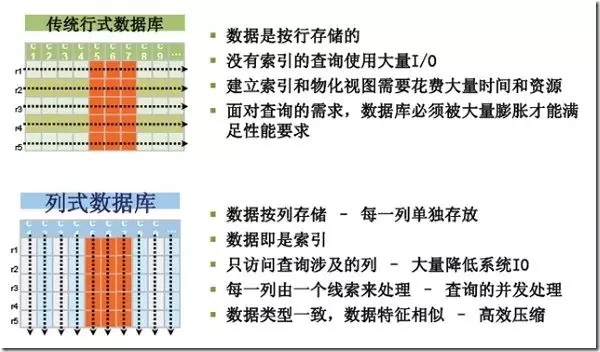
你可以简单想一下, 一个数组中的元素如果都是同一类型, 和存储了各种类型(等同于一个结构体) ,在大量数据需压缩存储的时候, 它的压缩难度/效率能一样么?大数据量写入的时候也是一样的道理. 注意想想列DB中的data is index 是什么意思? 以及为什么列查询能大幅降低系统I/O ?(要知道海量数据操作的时候, IO一般都是性能最大的瓶颈之一.)
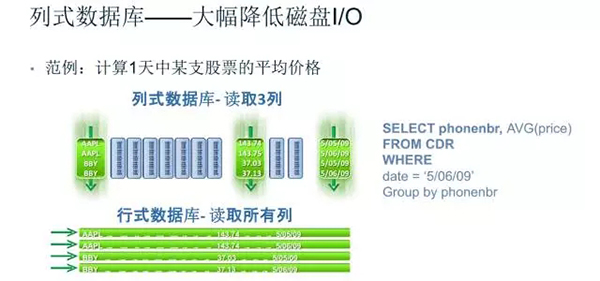
举个例子, 我们现在要做数据分析, 统计所有股票中某只股票24h内的平均价格.
- 对行DB, 因为股票价格每秒都在变化,在行数据库中写下如图的
SQL语句查询, 就需要读取stock表24h内的所有数据, 然后找到我们需要的price字段. 你试想一下. 如果是查365天内的平均价格呢? 简直是不可想象的, 当然以前的做法就是我每天的算存到一个新字段stock_price_day, 需要月统计/年统计的话可能还要单独抽成一张新表…你就会发现一旦需求新增, 如果想获得比较好的性能, 需要不断的改DB的结构, 这个隐患和代价其实是很大的… - 但是对列DB而言, 取某几列数据从逻辑上就会优很多.而且你会发现常见的列DB对插入的数据会自动写一个时间戳信息 ,以便更快的查找. 而且
- 再从
OS的角度来看, 数据存储的基本单元为页(page) , 以常见DB中每个page = 8k为例, 一个4行4列的表, 就占了2个page, 然后填充数据, 那么对行存储来说, 加载了全部数据后, page之间其实是跳跃的读取(因为需要的列并非连续的) , 也就是类似随机读取 (4k); 而列存储显然是读取page后在连续读取 (seq), 用过SSD/HDD性能测试工具的同学就知道, Seq 和 4K的速度相差是非常大的, 所以如果是分析操作, 列DB不仅能大幅减少IO次数 ,还能根本上把随机读改为**连续读 **. 从而达到巨大的提升.
当然, 行列各有自己的优势, 一般认为行DB更适合OLTP操作(随机CURD), 列DB更适合OLAP操作(聚合分析,数据挖掘), 这也是为什么常说列DB适合做数据仓库, 想想仓库的特点. Oracle12也推出了双数据存储模式(就是允许以列的方式存储), 业界一般也认为这是DB发展的趋势之一.
0x04.在Janus中
因为Janus存在Cassandra中的所有表,所有列的类型都是blob(binary large object),也就是二进制对象.所有直接看都是奇怪的字节码. 那么我们如何测试Janus创建Schema是否成功,是否正确,数据解析是否OK呢?
我建议先从小数据测试开始,完整性看行数. 但是,我们如何查看具体的数据呢? 难道序列化之后的数据只能反序列化在Janus才能查看么? 可以通过RowID先简单看看.
这里我用一个画的完整的图来从多个角度看JanusGraph和Cassandra的结合, 原图也开放在processOn上, 欢迎更新或fork (地址待更新)
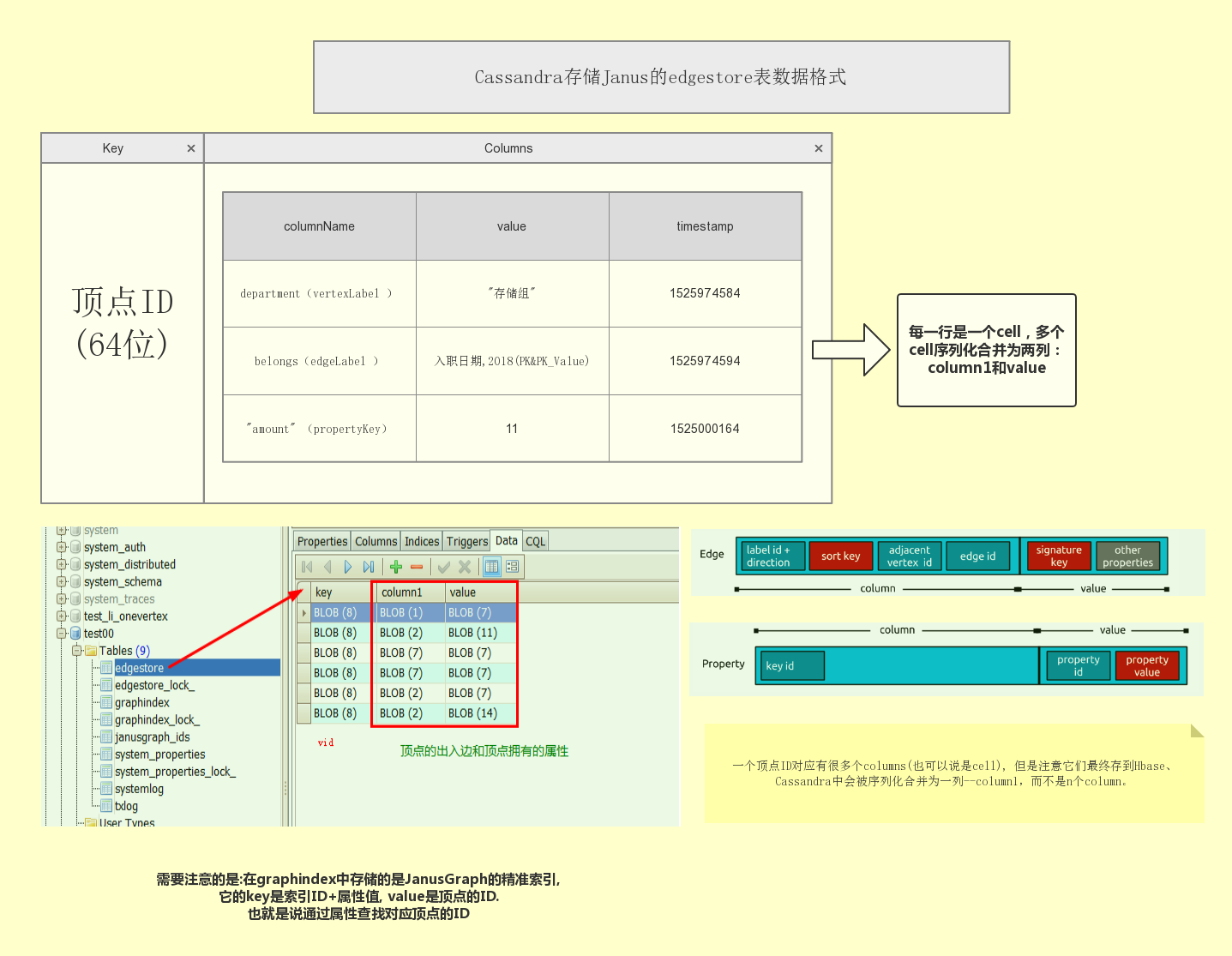
问题:
而且用CQL的count(*)函数 去统计图是显然不可取的,默认20s就超时, 如果是上百亿的数据可能要统计…..N小时? 那如何确定数据的总量都是一个大问题…
推荐资料: