大家常说的
图服务 = 图计算+ 图存储. 其中图计算是发展更快, 门槛更高的一块, 因为存储的发展是受到许多制约, 基本很难有质的改变. 计算涉及的各种算法和模型相比存储还是多不少, 而且和业务关联更紧密, 所以也至关重要.Tinkerpop(简称TP)是一个相对单独的部分, 目前做的主要是提供了一个图的查询语言(侧重OLTP), 只不过它想做的事太多, 既想定义存储又试图定义计算, 还想自己模拟实现一个类似MR的图计算引擎…. 所以我觉得在TP的这个大饼没有画好之前, 先不多关注它了, 就当一个查询引擎来看就行..
0x00. 图の发展史
需求产生
说发展史首先要说TP到底是做什么的,我们为什么需要它或类似的图计算引擎. 回到需求: 因为我们需要图数据库, 那么看看一般数据库的设计和实现的步骤:
- 如果是需要做一个APP,我可以定义对应的几个包和接口, 然后对应去实现功能相关的类. 思路很清晰. 那现在我要做一个图数据库,首先也应该是确定图DB的结构 (包括数据结构+模块/包结构) ,这就是Tinkerpop最核心作用之一 —- “抽象“
- 如果结构有了,下一步是提供标准化的功能规范(接口). 并且,图这里不同于普通db有个很重要的地方是它有很多相关的算法模型. 需要能提供计算这个功能. (实时还是离线另说)
- 然后数据库就肯定需要关乎到存储, 但这里很特别的是,图是一个完全不同于关系模型或普通NOSQL对象/文档模型的数据结构, 我们怎么存呢? 直接把一个图存起来么? 它本身结构极其松散,怎么统一模型呢? 这是个大难题, 所以当前大家的做法是把图的结构拆为几个部分用Nosql(列存储的DB居多)来存,其中上次接触gremlin用的TinkerGraph就直接存在内存中了,所以退出就没数据了~)
- 然后数据库的查询需要一种DSL,传统DB的SQL很难对应图的结构,所以就单独使用了Gremlin这种函数式/流式的语法来做CURD. 并且类似ODBC/JDBC一样,提供对应的连接驱动. 这都是
Tinkerpop的作用. - 最后就是类似
Cassandra/Hbase和各种传统数据库, 都会提供一个命令行方式去访问,这个就对应着TP的gremlin.sh(也就是入门TP的时候的控制台) . 并且这里它也提供了HTTP/Websocket的方式访问, 也就是在JanusGraph中经常启动的gremlin-server.sh
当前现状
A. 图计算
分布式图计算引擎大多基于Google的
Pregel白皮书/文章, 它讲述了Google如何使用图计算来进行PR的计算*(有点似曾相识?),* 然后老样子衍生出了单机的Cassovary和分布式的Giraph图计算引擎.而Tinkerpop3比较特殊, 准确来说它应该属于图计算和图存储的连接层/语言层. 并非计算底层实现
优点:
- 多是多核心并行计算
- 可以充分利用顺序读取
- 可以进行全局的分析
缺点:
- 基本不支持并发
- 全局分析速度很慢,最后退化为
limit.. - 基本无法实时计算.(时延太长, 所以等同于离线)
B. 图存储
图的存储说起来应该是从学术界(RDF)转向工业界(
Property Graph)的, 关于RDF和属性图的区别和定义, 建议参考这篇Neo4j的文章和对应的在线presentation (推荐) , 我简要的概括可以说: RDF是非属性图, 而现有的图数据库一般存储的是属性图(更接近真实的图结构) , 现有的图数据库归纳来来看, 优先以下6种适合供研究参考 :
Neo4j(单机-Java) .RedisGraph(单机- C) [第一代图]JanusGraph(存储分布式+计算单机-Java) ,HugeGraph(重构Janus的改进版),Dgraph(分布式-Go), [第二代图]Tigergraph(分布式-闭源-C++) [第三代图?]顺便解释一下我的对”原生“和”并行“图的理解:
- 原生图: 主要是对比实际把数据存在K-V或传统数据库上的图, 本质只是在内存中组织为图的数据结构, 而不是以图的方式存储在磁盘上,
Neo4J和TigerGraph是原生把图存在磁盘上, 这样做的好处不言而喻… 问题是实现太复杂了, Neo4J单机设计之后也很难演变到分布式版本取切分.- 并行图: 这个说通俗一点就是, 分布式计算的图, 对比目前
JanusGraph/Huge/Neo4J单点计算, 做到多个节点并行计算, 所以我推断为什么TigerGraph这么快, 因为它是目前极少做到磁盘原生图存储, 并能均匀切分到多台机器, 然后稳定的在内存做分布式计算的….发展趋势 : RDF(199x) – >原生单机属性图(2010) – > K-V分布式属性图(2013) – > 原生并行图(2017)
优点:
- 可以适应高并发,扩展性好
- 以顶点为起点(中心)局部遍历快 (相较ER-DB)
- 结构松散,可塑性极强
缺点:
- 目前的图在磁盘存储方式大多很低效, 实际转为了
K-V存储, 并非原生的图存储. - 超级顶点问题还很难解决
- 图模型无法通用 (计算/前端都需要单独造轮)
- 有各种单独的DSL
- 分布式事务 (强ACID)实现问题很多
0x01.整体结构
看看这张TP的结构图…我的理解是,最上面的阿黄是数据输入/输出(json/cvs).. 中间是gremlin和用户的一些特有策略,使用者还可以特定的TraversalStrategy优化策略,允许底层图系统在执行Gremlin查询时对其进行性能上的优化(如: 多种索引查询, 特定算法优化, 遍历步骤重排)
真正核心的函数也是下面的Core API ,这里包含了图计算接口 , 它定义了消息和遍历器的多节点分发模型和内存中的数据结构 , 最后往下是OLAP和OLTP 的实现层, 已经无关TP本身. (这两个到底是什么, 和图计算的关系是? 参考后文)
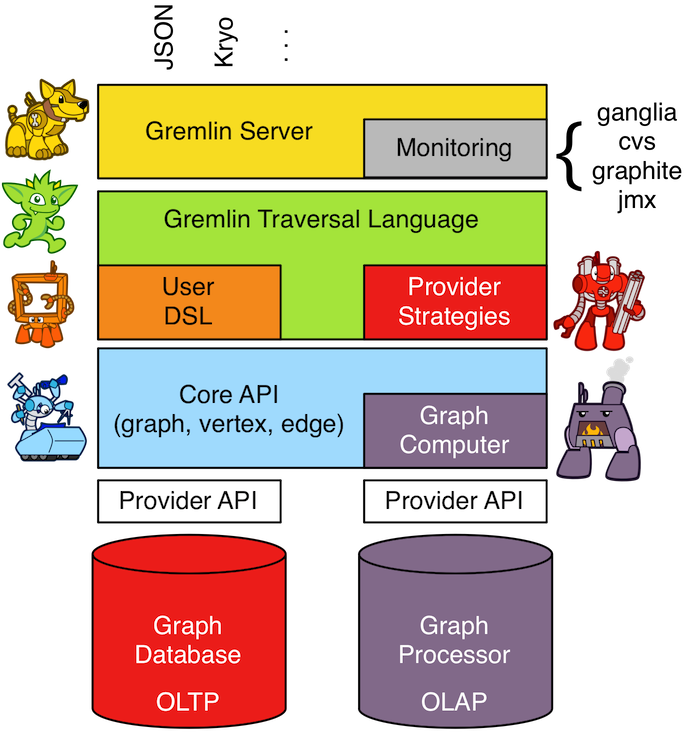
0x02.代码结构
类似JanusGraph一样,
Tinkerpop的代码结构也算分module很细. 大致有如下7个模块 :
0.gremlin-console(上图第一层)
就是我们访问gremlin.sh的时候显示的控制台交互逻辑,从代码中可以看到基本是groovy实现的.
1. gremlin-groovy(上图第二层)
实现Gremlin的代码, 以及在gremlin中支持groovy/其它DSL的写法, 最后是些可定制策略, 目前来看不太重要, 而且内容很杂多…
2. gremlin-core (重点-上图第三层)
这里定义图模型结构 , OLTP和OLAP接口? (具体实现是单独的)
图的数据结构 (Vertex,VertexProperty,Edge,Property,Element,Transaction)
实现了以上所有的接口的图系统, 我们就可以说它实现了图的OLTP , 比如JanusGraph/TinkerGraph.而实现后就可以使用Gremlin语法.
数据的导入&导出
特殊功能的图实现 (比如做缓存图)
图的OLAP也需要单独实现, 比如和spark的结合已有的graphX或giraph…
3. spark-gremlin(OLAP)
貌似是一个tinkerpop基于spark的OLAP实现, 还有hadoop-gremlin
4. giraph-gremlin(OLAP)
Giraph 源自Google在2010年发表的Pregel计算框架, 是它的开源版本,运行在hadoop之上,是一种仅有Map的MR作业….
当然本质上, 是类似GraphX/GraphLab的图计算框架, 分清楚各种名词是梳理整个图服务脉络的前提.
5. tinkergraph-gremlin (推荐)
TP自带的内存图数据库, 带有OLAP+OLTP 的最简实现 ,上手测试用. 细节实现以后可以看看,毕竟小巧.
6.benchmark和driver
跑性能测试,和各种连接语言所用的DB-driver测试之类的…也不太重要
0x03.与JanusGraph结合
再结合最早Janus的那张官方结构图来看, TP到底在中间是什么位置, 到底TP做了什么,Janus做了什么呢?
其实目前简单来看, Janus做的是一个**”承上启下“** 的中间层作用.它即不负责前端调用和图算法的基本定义 , 也不负责实际的存储, 而是一个中间层来解耦这两块, 并实现图引擎的OLTP和OLAP接口, 然后连接Hbase/Cassandra/ES等存储端. (对比Neo4J就耦合度高不少)
但是实际来看, 这样做并不太好, 解耦过了, 就会带来严重的性能和维护代价 , 理论你需要同时维护至少4个组件 (Tinkerpop+ Janus + Hbase/Csd + ES) , 而且任一出了问题, 其实都会直接严重影响Janus的可用性和性能.
然后补充一下Tinkerpop的核心结构和定义, 具体的实现可以参考TinkerGraph源码阅读:
1.存储结构 (Interface)
- Vertex : 记录
from/to边 , 继承Element接口 - Edge : 记录from/to 顶点, 继承Element接口
- Property
: 定义通过key映射V的属性 - VertexProperty
: 同上, 但此时V可以是多个 Property<T>,并继承Property<V>, Element接口 - Element : 抽象的元素接口, 定义公用的属性(例如id)和元素类型
- Graph : 集合所有元素(顶点,边属性等..) ,事务+CURD的定义.
2.计算结构
- Traversal<S,E> : 处理遍历中的数据, 比如将S —加工—> E
- TraversalSource : 遍历启动器, 同时定义一些DSL.
- GraphComputer : 默认的遍历是单核OLTP方式, 这定义多核OLAP方式并行遍历
- VertexProgram : 在所有顶点上并行的执行的代码, 使用消息分发的通信机制. (OLAP用的多)
- MapReduce : OLAP的一种实现, 并行的聚合&计算.
0x04.再说图计算
12.13更新: 觉得可以先很简单的一句话去理解:
- OLTP 就类似传统数据库(如mysql)的增删改查 ,
- OLAP 就类似迭代计算,数据分析.(如PageRank)
因为初接触, 首先说一下OLTP 和OLAP这两个名词的背景和我的理解
1.OLTP (online transaction processing)
这里说的实时事务处理比较拗口, 其实本质就是CURD… (也就是数据库最常见的增删改查操作).只不过这里通常会强调事务 这个一致性概念. 其实图和很多Nosql中根本就不支持或者很弱的支持事务, 如果从事务来说, 他们都不属于OLTP了. 觉得这个词实际已经被滥用了… 原本可能是主要指事务性数据库 –> 银行/金融这些业务,例如:
- 查询银行中余额大于5千万的用户账号
- 查询某个银行账号的用户详细信息…
但是现在已经比较泛指基本的数据库操作了, 并没有强调原意中的事务.
2.OLAP (online analytical processing)
这个最早是数据库之父E.FCodd 1993年提出的, 并不是什么新名词,只不过以前没什么人用起来… 其实从名字就知道了, 就是 在线分析
当然它对实时性的要求没有CURD高(那肯定咯,因为单纯的增删改查就影响几条,几十条数据. 而一次数据分析/聚类可能首先就要获取百万,千万的数据…) 所以OLAP可能多使用内存去加载处理数据了, 不然速度可能低的发指 (也应该会大量使用缓存和分区/并发等技术.) 例如:
- 查询银行最近7天的总存款增长比率和每日平均存/取款额.
- 查询某个人的Wechat号所在的群组的其他人之间的关联度(是否好友,聊天频率等)
而这其实就是图计算的真正含义 ,而非简单的遍历/新增/修改一下图的某个顶点, 以及它有哪些邻居(这其实是OLTP范畴)… 所以再回看0x01中的图底,发现二者是一个颜色的…关系是provide api .那么TP这里可能就是提供各种算法模型的接口, 等其它(比如Janus)去实现.
需要注意的是,OLTP和OLAP其实都是图系统很重要的一块, 所以如果都让中间层去实现,未免难度过大, 业界自研的图计算引擎, 一般是把OLAP部分在上层就已经实现了,是一个单独的模块, 中间层只需要做传递连接底层数据的工作. 当然TigerGraph/ Neo4J这种是存储计算一体的, 在某些场景下就省去了不少数据转换的代价, 从而有更好的查询性能.
3. Graph Computing
说完了前身的OLTP+OLAP, 再绕回图计算的本体, 图计算这块东西太大, 我也算不上多熟, 所以先还是抛砖一下, 列一些可供参考的文章. 以后再补:
0x05.图计算的理论(待拆分)
这一块其实是很大的一类研究… 图的各种模型/算法—>图论也都是图计算的基础. 所以目前只能大致先说一下整体. 先来说说为什么需要图计算? 以Tinkerpop作者Marko提出的*GTM(Gremlin Traversal Machine)*对比一下冯诺依曼的计算机体系结构 :
| 传统计算机 | 遍历机 |
|---|---|
| 指令集 | 步库(step library) |
| 代码 | 遍历(traversal) |
| 计数器 | 遍历子(traverser) |
| 内存 | 图(graph) |
这里的遍历机的概念,可能还非常陌生, 得后面一一查看,论文参考. 大体是希望遍历机发展为像**X86/ARM这样的通用物理计算架构**的软件版,
1.基本结构
GTM(gremlin遍历机)由三部分组成 : G(图) , 遍历(这个符号..) 和T (遍历子) ,分别对应数据,指令和读写头. 下面论文一堆符号,还没看明白…之后再补
2.程序语言
设计之初Gremlin就想类似计算机的指令集一样, 有一个公用的底层步骤库 (30个左右), 目的就是让人能简单的定义遍历 , 然后让遍历机接收到指令后,让遍历子去执行这次遍历. Gremlin的步骤库大致分为5类:
- map : 对遍历中的单个对象进行转换 (一对一映射)
- flatmap : 对遍历中的多个对象进行处理 (N对N映射?)
- filter : 对遍历中的对象进行筛选 (过滤)
- sideEffect : 对遍历中的对象进行统计 (计算)
- branch : 这个待补充..
这里也不说人话…待补充, 主要是都是符号术语…. (这点不太好:)
3.遍历
待补…
0x0n.后记
这篇文章也需要不断的更新和补充, 有些地方和TinkerGraph中是重合的 (比如数据结构定义)
未完待续….
参考资料:
- M. Rodriguez, The Gremlin Graph Traversal Machine and Language, Proceedings of the ACM Database Programming Languages Conference, 2015
- W. Zaremba, I. Sutskever, Reinforcement Learning Neural Turing Machines, arxiv preprint, 2015
- J.M. Hernández-Lobato, R.P. Adams, Probabilistic Backpropagation for Scalable Learning of Bayesian Neural Networks,arxiv preprint, 2014
- Rdf-triple-store-vs-labeled-property-graph-difference (recommend)
- (待更新)TinkerPop与JanusGraph的整合