泛型在整个PL中的地位可谓非常之高,
go目前最为诟病的一件事就是不支持泛型 (据说go 2.x会支持?) , 同样,不同于初学时期 , 再看泛型, 要尽可能多的串联其他语言和底层原理, 真正的理解透泛型的使用和意义.PS:关于源码中final的内容参考源码阅读之final ,
0x00.简介
A.历史
以常见语言为例, 泛型很早就从Java5 和 C# 2.0引入, 可称为当时版本最重要的特性之一 , 并且后续在各种源码和框架中大量活跃. 但是需要注意的是, 很多人不太熟悉的C++的模板其实才是泛型最早的开始, 从C++ 98 就引入了模板 (template) 这个概念.
首先, 泛型和模板之间, 表面看是有许多相似之处, 但是实现上差别甚多, 本质几乎完全不一样, 所以后面也会对比的来讲讲, 不同语言实现”泛型”这种效果的不同策略.
然后, 得知道 泛型编程 这个概念源自STL的引入. 当时C++为了让STL更加通用化和灵活, 就带入了模板, 泛型只不过在模板的基础上进行了简化或改进 , 所以学习泛型必须先比较好的了解模板.
最后, 模板完整看其实是挺复杂的.人们常说C++包括普通和元编程, 这里说的元编程其实就是模板编程了 —-通过少量的代码模板, 让代码自己生成大量代码..
B.基本规则
首先, 泛型有自己的读法, List<T> 读作list of T ,估计很多还不知道怎么读的hh~ (我以前就硬读尖括号..
然后,它有一些常见的规则, 在后面就不再单独解释:
- 类型参数字母是可以随便取的, 不一定非要是
T/E/K/V,但是大家习惯遵守基本的规范 (T代表Type, E代表Element,K-V键值对, 其他就看具体情况了) - 一般
?代表通配符, 在不确定或不需要关心实际类型的时候用, 常与权限限制 搭配来约束类型 , 特别注意?不同于Object,T前者代表未知类型, 后者是代表任意类型, 具体区别会体现在确定具体类型后的方法调用上. 但是在不少情况下, 二者是可以互换的. 所以特别注意不要滥用? - 这里不会过多举每个语言单独的语法实例, 那情况太多了. 只会举通用核心的, 然后其他给参考链接.
0x01.实例分析
了解了简单历史, 那我们跟着泛型的历史来结合三种语言看看不同的泛型实现的区别. 先看看祖师爷C++
1. C++案例
首先不妨来回顾一下简单的概念, C/C++中有一种很常见的语法—-define , 被称为宏. 宏能够在预编译期替换你想使用的代码, 等于把一段代码直接复制到了所需的地方, 从而节省方法调用的时间, 可以看成是空间换时间的一种做法(结合上次学习final的时候, 提到的内联, 是类似的概念), 比如这段代码:
1 |
|
那我们回忆完了宏 , 许多人为了简化理解, 把模板称为高级宏 , 也就是说它也有这样相似的动作—-“把抽象的参数自动替换为我们所需的类型“ , 比如在C++中定义一个Food模板类之后, 可以去声明不同类型的实现类 , 实现
1 | template<class T> class Food{ |
在编译之前,上面的模板会进行自动的展开,变成类似如下的自动填充 : (是不是宏的感觉?)
1 | class Food_Apple { |
这样你就明白简单说模板是一种更灵活的高级宏的由来了吧, 它帮你自动生成了不同类型的代码,如图:
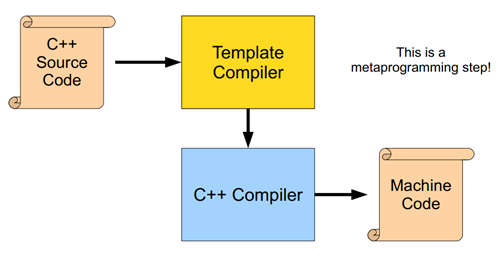
而模板还有一个学究的名称: 编译时多态技术 , 首先你会觉得奇怪怎么突然蹦出了多态这个名词, 其实也是因为泛型 本身也有个学究的名称: 显式参数多态 , 当然模板功能其实比泛型强大得多. 不过这种技术有一个很明显的代价,也就是宏的代价, 空间换时间后它可能会生成N份代码. 大量使用模板的C++代码,编译后的文件将非常大 (某些编译器可能会做优化处理? ) .
2. Java案例
为了解决C++时空互换带来的问题, 以及兼容低版本的代码(其实这是一个深坑) ,导致Java的泛型功能弱, 效率低, 反而有非常多的约束. 当然它把空间利用率提到了最高… 先看看核心步骤, 再看看具体例子.
编译泛型的三步骤:
- 检查 并获得泛型的实际类型, 然后存到class文件中
- 擦除原有类型 , 替换为限定类型(
T/E等无限定类型, 用Object替换) - 最后, 调用相关函数将结果强制转换为目标类型 (效率可见一斑)
1 | List<String> strList=new ArrayList<>(); |
上面代码输入结果为 true,可见通过运行时获取的类信息是完全一致的,泛型类型已经被同化了.
如何擦除:
当擦除泛型类型后,留下的就只有原始类型了,例如上面的代码,原始类型就是ArrayList。擦除类型变量,并替换为限定类型(T为无限定的类型变量,用Object替换),如下所示
擦除之前:
1 | //泛型类型 |
擦除之后:
1 | //原始类型 |
因为在Pair<T>中,T是一个无限定的类型变量,所以用Object替换。如果是Pair<T extends Number>,擦除后,类型变量用Number类型替换。
3. C#案例
C#结合了C++的宏式复制和Java的代码共享. 首先在编译时,c#会将泛型编译成元数据,即生成.net的IL Assembly代码。并在CLR运行时,通过JIT(即时编译), 将IL代码即时编译成相应类型的特化代码。
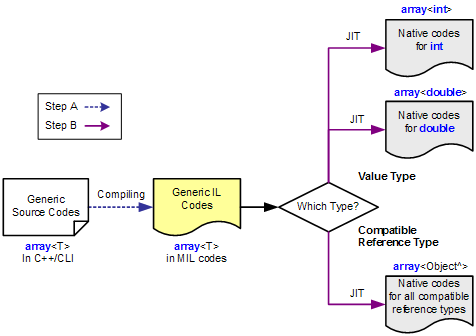
这样的好处是既不会像c++那样生成多份代码,又不会像java那样,丢失了泛型的类型。基本做到了两全其美。 (那你回想, Java为什么不这么做? 主要是因为兼容考虑)
0x02.底层原理
这里先引入几个观点:
- Java的泛型实现本质是靠
类型擦除,牺牲运行速度; C++的模板则是靠静态实例化, 代码体积增大, 速度快很多.- C#在泛型比Java实现更好, Java应该算是
伪泛型(语法糖) ,C#才称得上是真泛型. (Java需要向下兼容)
对比来说, C#和Java的泛型才更像是一个类, C++的泛型(模板)其实更像一个宏 ,然后 C++与C# 泛型实现最大的区别
C++
C++泛型跟虚函数的运行时多态机制不同,泛型支持的静态多态,当类型信息可得的时候,利用编译期多态能够获得最大的效率和灵活性。当具体的类型信息不可得,就必须诉诸运行期多态了,即虚函数支持的动态多态。
对于C++泛型,每个实际类型都已被指明的泛型都会有独立的编码产生,也就是说list<int>和list<string>生成的是不同的代码,编译程序会在此时确保类型安全性。由于知道对象确切的类型,所以编译器进行代码生成的时候就不用运用RTTI,这使得泛型效率跟手动编码一样高。
显然这样的做法增加了代码空间,相比运行时多态,是以空间换时间。
C#
C#泛型类在编译时,先生成中间代码IL,通用类型T只是一个占位符。在实例化类时,根据用户指定的数据类型代替T并由即时编译器(JIT)生成本地代码,这个本地代码中已经使用了实际的数据类型,等同于用实际类型写的类,所以不同的封闭类的本地代码是不一样的。其可以在运行时通过反射获得泛型信息,而且C#的泛型大大提高了代码的执行效率。
Java
当编译器对带有泛型的 Java 代码进行编译时,它会去执行类型检查和类型推断,然后生成普通的不带泛型的字节码,这种字节码可以被一般的 Java 虚拟机接收并执行,这种技术被称为擦除(erasure).可见,编译器可以在对源程序(带有泛型的 Java 代码)进行编译时使用泛型类型信息保证类型安全,同时在生成的字节码当中,将这些类型信息清除掉。
如在代码中定义的List<object>和List<String>等类型,在编译后都会编程List。JVM看到的只是List,而由泛型附加的类型信息对JVM来说是不可见的。Java编译器会在编译时尽可能的发现可能出错的地方,但是仍然无法避免在运行时刻出现类型转换异常的情况。
擦除的原则:
- 所有参数化容器类都被擦除成非参数化的(raw type);如
List<E>、List<List<E>>都被擦除成List - 原生类型(int,String还有wrapper类)都擦除成他们的自身
- 参数类型E,被擦除成Object
- 所有约束参数如
<? Extends E>、<X extends E>都被擦除成E - 如果有多个约束,擦除成第一个,如
<T extends Object & E>,则擦除成Object 所有参数化数组都被擦除成非参数化的数组;如(话说支持输出写法么?)List<E>[],被擦除成List[]
来看个例子:
1 | public class Pair<T> { |
擦除后变为:
1 | public class Pair { |
再看一个例子, 擦除前后:
1 | //泛型时--擦除前 |
那么,进行类型擦除后,在调用时怎么知道其真实类型,放心吧,编译器帮我们做好了一切,以后上面的Pair为例:
原代码为:
1 | Pair<String> pair = new Pair<>("", ""); |
反编译后为:
1 | Pair pair = new Pair("", ""); |
可以看到,编译器帮我们做了自动类型转换。
对于泛型,我们可以利用Java单根继承特性实现类似效果,但是因为此时编译器并不做类型检查,这种检查是在运行时进行的,推迟了发现程序中错误的时间。
而利用泛型机制,编译器承担了全部的类型检查工作,确保类型的安全性。以List<Object>和List<String>为例来具体分析:
1 | public void test() { |
这里,声明为List的集合中却被添加了一个Integer类型的对象。这显然是违反类型安全的原则的,在某个时候肯定会抛出ClassCastException。因此,编译器禁止这样的行为。编译器会尽可能的检查可能存在的类型安全问题。对于确定是违反相关原则的地方,会给出编译错误。当编译器无法判断类型的使用是否正确的时候,会给出警告信息。此种机制有利于尽早地发现并改正错误。
让我再来看一个问题:
1 | public class QmiV<T> { |
擦除后:
1 | public class QmiV<Object> { |
1 | //子类 |
擦除后:
1 | public class QmiVD extends QmiV<Person> { |
可以看到,对于setValue方法,父类的类型是Object,而子类的类型是Person,参数类型不一样,所以这里实现的不是重写,而是重载。
实际中,是利用桥方法解决这个问题的。
桥方法就是生成一个中间层,其参数类型都是Object,也就是说,子类中真正覆盖父类两个方法的就是两个我们看不到的桥方法。桥方法的内部再去调用我们自己重写的那两个方法。
0x03.总结
所以总结一下几种泛型设计。c++的泛型在编译时完全展开,类型精度高,共享代码差。java的泛型使用类型擦出,仅在编译时做类型检查,在运行时擦出,共享代码好,但是类型精度不行。c#的泛型使用混合实现方式,在运行时展开,类型精度高,代码共享不错
首先,Java 语言中的泛型不能接受基本类型作为类型参数――它只能接受引用类型。这意味着可以定义 List<Integer>,但是不可以定义 List<int>。那么为什么Java的泛型不能使用基本类型? 再知道根本的原因了么?
因为Java中的泛型是通过编译时的类型擦除来完成的,当泛型被类型擦除后都变成Object类型。但是Object类型不能指代像int,double这样的基本类型只能指代Integer,Double这样的引用类型.
C#和C++的泛型最大的区别是在于**类型检查的时间** & 如何实例化 ,
- 所谓类型检查也就是说比如
List<T>,在C#中会提前检查T调用的方法是不是必须存在的, 而不能随便调用方法, 而C++的模板可以说是无/弱类型检查的, 你可以在T上任意操作, 但是实例化的时候就可能会报错, 而且报错信息很模糊. - 所谓何时实例化, C#是在运行时才实例化 ,C++大部分是典型的编译时/链接时 ,也就是说在程序运行之前就实例化结束了. 这个是根本的区别, 所以C#才能在尽可能保证泛型功能情况下, 还尽可能的减少
代码膨胀问题.
而Java和C++/C#泛型最大的区别在于**效率和功能**:
- Java的泛型为了考虑兼容VM, 本质是个语法糖, 不仅不会获得效率提升, 反而还可能有些降低, 这是头号问题.
- Java的泛型依赖类型擦除, 无法在运行时获得编译时一样的内容, 自然也不支持反射中使用泛型或者基本类型的泛型, 功能上弱化了许多.
这是补充内容, 之后单独抽取出. 9.30
编译相关问题
编程语言从来没有编译型和解释型之分,只能说一门编程语言的常见执行方式为编译器编译成新代码(交给解释器或者机器码执行),或者解释器解释执行。
- 编译=第一次执行前花费大量时间预处理,之后执行速度大幅上升
- 解释=每一次执行速度一样,但(普遍)比编译后的速度慢
两者基本上是同一条坐标轴的两极,所以你只能选择在两者之间的位置,但不可能同时拥有两极的特点
0x00.首先,什么是编译器?
编译器,简单的说,就是一个程序,它的输入是一种A语言的源代码,输出是一种B语言的源代码。
当然,一般来说,A语言和B语言是不同的(但也有相同的情况,一般用于代码优化或者代码混淆……),比如C++编译器,将C++源代码编译成为汇编代码。
C++:
1 | int foo(int a,int b,int c){ |
汇编:
1 | mov eax, dword ptr [esp + 8] |
当然,有些人会说:“为什么VS点”编译”就直接生成一个可执行文件(.exe)了?难道(.exe)是汇编的文本流?” 这当然是否定的,因为其实那个叫做”build”而非单纯的编译,包括了链接(link)的步骤,在链接的时候(这里拿静态链接举例)把你经过编译得来的汇编代码,中间的地址重定向为操作系统分配的地址,还有外部C++标准库之类的,把对应的指令的地址重定向到相应的地址等等,让这个纯粹的类似宏汇编代码能够真正变成可被操作系统装入内存的机器码。
编译过程中,并没有要求编译器表现出任何关于源代码定义的行为,它是生成了一个能表现输入源代码行为的新的代码。
0x01.那么,解释器呢?
解析器,其实就是一个程序,它的输入是一种语言的源代码,但是它直接执行了源代码(意思是这个程序对外表现了这个源代码定义的行为),比如Python的解析器,只要给定一个输入,foo.py,那么运行这个程序(带上这个输入),它的执行行为就表现为那个foo.py的行为。
foo.py的内容:
1 | print "hello world!" |
python解释器执行:
1 | xx:Python xx$ python foo.py |
其实,解释器就是一个大黑箱,你就算不知道里面究竟是什么,但是你知道你的输入的源代码会被完整的执行出来。常见的,解释器内部的实现也就是一个编译器外加一个虚拟机,编译器用来讲输入的源代码生成中间代码,而虚拟机将中间代码一条条执行(这个执行一般指的是使用C写的执行引擎程序来执行)
0x02.虚拟机
虽然这个玩意我不太懂(别打我……),但是一个虚拟机一般是由定义了的中间代码语法,以及一个执行引擎组成,比如JVM和Java字节码,Zend Engine和Opcode。之所以不采用真实的物理机,一是因为物理机的指令集多,各种新架构新增的指令直接写太困难,可移植苦难。俗话说的好
计算机领域只要多分几层,没有解决不了的问题
比如对于一门动态语言,直接做一个编译器讲这门语言和汇编链接到一起,难度太大(尤其是词法分析上),这个时候可以采取间接的定义一套中间码,讲源代码编译成为中间码,中间码通过另一个程序(执行引擎,一般是C/C++写的)执行这个中间码,这样效率不会损失太多但大大加快了开发效率。
Java:
1 | int a = 0; |
Java字节码:
1 | 0: iconst_0 |
其实虚拟机执行引擎怎么执行传来的中间码,这也是一个编译/解释的区别,前者就是直接将中间码再次编译为更底层(汇编级别,机器码),并且保存到外存中,比如.NET的CLR;后者就是直接把这个中间码按照一条条的指令直接执行(执行也就是用C的等价代码来实现它),不会将新的代码保存在外存中。这也是一个最大的区别吧。
0x03.总结一下
现如今,其实语言本身没有任何要求你是采取编译的方式生成二进制文件手动执行,还是解析的方式直接执行,但是一门语言的设计很可能会影响这个过程,因为你想要一个想让Ruby做一个纯粹的编译器编译成汇编,这个难度不是也太大了嘛……还不如直接把Ruby解释器封装一下(Ruby解释器是用C写的)
扯淡阶段:其实所谓编译型和解释型递归到最后,都是编译型,因为你无论如何都是把代码转换为二进制数嘛,而最后的执行,其实就是一个二进制数的第几位所对应ALU的第几号地址引脚的电平高低的变化而已,所以就没有”解释”这个过程,所以所有的东西都是编译型(逃……)
参考资料:
- zhihu-R大, 以及不少前辈, 之后慢慢补一下链接..
- 编程的逻辑–全面理解泛型35~37 (关于Java实际例子推荐参考这个系列, 说的很清楚了)
注: 有些一两句话的参考没单独列出, 文章主要是依赖自前辈的参考和访谈, 然后我做了一些自己的理解和精简整合. 再次表示感谢