今年年底来看, 图这方面最大的两个新闻, 一个是Tigergraph的单机开发者版免费放出, 已经正式登录国内 ; 另一个就是baidu的Hugegraph的开源, 它参考Titan/JanusGraph, 整体重写了全部代码, 大幅完善了不少图周边的生态. 最后还有个比较陌生的开源图
HgraphDB,阿里云目前有在Hbase里当做一个插件使用, 也就顺带简单看看吧…
0x00.目标
最早从NOSQL漫谈的这篇文章我们就可以知道, 当前JanusGraph存在以下几个核心改进点:
- 拆分表结构, 把原来的顶点&边混在一起改为各自单独存储. (甚至于进一步拆开系统和非系统图)
- 针对全序列化兼容后端这一块, 去掉不必要的序列化.
- 针对后端的Hbase/Cassandra, 利用它们自身的特性做定制和优化. 可以很大改善IO的效率.
但是因为华为并没有继续讲他们是如何做这些优化点的, 但是目前来看有两个比较好的参照实现: Hugegraph(主)和HgraphDB(次). 接下来文章后面主要关注HgraphDB的整体结构, 与JanusGraph的区别 ,其次简单梳理一下阿里云使用的相关情况, 最后部署测试一下看看实际效果.
0x01.存储结构
HgraphDB的全称是Hbase graph DB….(略冗长), 它实现相对简单不少, 只能基于Hbase去使用, 最初源于一个国外作者公司需要, 一个人开发的, 先来看看它. (它也实现了Tinkerpop, 支持Gremlin语法)
HgraphDB采用宽表模式 ,每张表都是key-column模式, 核心是以下几张表: (然后我给出一个demo的数据实例)
表结构按照Schema表和Data表分类:
Schema表(3个)
1.Label元信息表: 主要用于data check
存储的都是ID Type和PK Type
| Row Key [label, element type] | ID [type] | CreatedAt | UpdateAt | Property1 key [type] | Property2 key [type] | … |
|---|---|---|---|---|---|---|
| person/Vertex | Long | NA | NA | String | Short | … |
| likes/Edge | String | NA | NA | String | Date |
2.Label关联表: (点边关系)
| Row Key [from vertex label, edge label, to vertex label] | CreatedAt | UpdateAt |
|---|---|---|
| person/likes/dog | NA | NA |
3.索引元信息表:
rowkey结构: [label, property key, element type]
isUnique字段指定索引value是否唯一,决定了索引数据表中value的存储位置
state表示索引状态,可用于索引修改、更新
| Row Key | CreatedAt | UpdateAt | isUnique | State |
|---|---|---|---|---|
| person/name/Vertex | NA | NA | true | ACTIVE |
| likes/time/Edge | NA | NA | true | ACTIVE |
Data表(4个)
Vertex表和Edge表中多个property都是按column分开存储,便于更新
1.Vertex表:
| Row Key(vid) | (v)Label | CreatedAt | UpdateAt | PropertyKey1(e.g. name) | PropertyKey2(e.g. age) | ….. |
|---|---|---|---|---|---|---|
| 101 | person | NA | NA | Jin | 22 | ….. |
| 201 | dog | NA | NA | Dove | 3 |
2.Edge表:
| Row Key(eid) | (e)Label | fromVertex | toVertex | CreatedAt | UpdateAt | PropertyKey1(e.g relation) | PropertyKey2(e.g time) | …… |
|---|---|---|---|---|---|---|---|---|
| 4 | likes | 101 | 201 | NA | NA | master | 2018 |
3.Vertex索引表:
rowkey结构: [vertex label, isUnique, property key, property value, vertex ID (if not unique)]
若isUnique = false, 多个vertexID会分别拼接到rowkey的最后,利用HBase的scan去做查询
| Row Key(复合) | createdAt | UpdateAt | VertexID |
|---|---|---|---|
| person/true/name,age/Jin | NA | NA | 101 |
4.Edge索引表:
rowkey结构: [vertex1 ID, direction, isUnique, property key, edge label, property value, vertex2 ID (if not unique), edge ID (if not unique)]
备注:vertex2 ID和edge ID同样拼接到row key 的最后
| Row Key | CreatedAt | UpdateAt | VertexID | EdgeID |
|---|---|---|---|---|
| 101/方向/true/likes/relation,time/master,2018 | NA | NA | 201 | 4 |
0x02. 实际上手
因为hgraphDB项目比较冷门, 所以除了github的README ,几乎没有任何文档, 也没有打包好的包测试环境(类似Janus那样), 只能通过自己新建一个项目去手动启动然后加载到gremlin中.简单两步骤如下:
IDEA中新建一个maven项目, 然后在
pom.xml里添加如下:1
2
3
4
5
6
7
8
9<dependencies>
<dependency>
<groupId>io.hgraphdb</groupId>
<artifactId>hgraphdb</artifactId>
<version>2.0.1</version>
</dependency>
</dependencies>
<!--然后由于引入了大量的hbase库,有不少日志和guava版本的重复引用,如果熟悉引用建议去掉(当然不管它可能也没什么)-->接下来新建一个
init包, 并新建一个GraphInit类去生成一个实例, 并写一些插入和查询语句. 这是我简单写的例子.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105package init;
import io.hgraphdb.*;
import io.hgraphdb.HBaseGraphConfiguration.InstanceType;
import org.apache.commons.configuration.Configuration;
import org.apache.tinkerpop.gremlin.structure.T;
import org.apache.tinkerpop.gremlin.structure.Vertex;
import org.apache.tinkerpop.gremlin.structure.util.GraphFactory;
import java.time.LocalDate;
import java.util.Iterator;
/**
* 测试HgraphDB的初始化类
* 注意 : Hbase2.x上测试是有一些奇怪的报错的, 比如清空表失败..如非必要还是在hbase1.4上测吧
* */
public class GraphInit {
public static void main(String[] args) {
//配置连接Hbase,启动实例
HBaseGraph graph = (HBaseGraph) GraphFactory.open(configGraph()); //在Hbase配置类里还有其他许多参数,请注意自行设置
//清空方法
clearGraph(graph);
//初始化方法
creatSchema(graph);
//查询操作
query(graph);
}
static Configuration configGraph() {
Configuration config = new HBaseGraphConfiguration()
.setUseSchema(true)
.setInstanceType(InstanceType.DISTRIBUTED)
.setGraphNamespace("graph_jin") //自己的db-name
.setCreateTables(true)
.setRegionCount(3) //最少是3个,否则会终止
.set("hbase.zookeeper.quorum", "10.xx.xx.xx,10.xx.xx.xx")
.set("zookeeper.znode.parent", "/hbase"); //这里配置的'/hbase',需要与hbase的配置文件中的"zookeeper.znode.parent"参数配置保持一致
return config;
}
static void query(HBaseGraph graph) {
// 获得名字是John的点
Iterator<Vertex> it = graph.verticesByLabel("person", "name", "John");
// get persons first known by John between 2007-01-01 (inclusive) and 2008-01-01 (exclusive)
/*Iterator<Edge> it2 = v1.edges(Direction.OUT, "knows", "since", LocalDate.parse("2018-01-01"), LocalDate.parse
("2019-01-01"));*/
System.out.println("检查数据");
/*分页功能
* */
//获得第一页的persons (注意: null is passed as start key)
final int pageSize = 20;
Iterator<Vertex> it3 = graph.verticesWithLimit("person", "name", null, pageSize);
int i = 1;
while (it3.hasNext()) System.out.println("顶点"+i+it3.next()); //hbase2下暂时无输出
//用第一页的最后一个人作为start-key获取第二页内容
it = graph.verticesWithLimit("person", "name", "John", pageSize + 1);
//获取John最近认识的人的第一页(相当于limit)
//Iterator<Edge> it4 = v1.edgesWithLimit(Direction.OUT, "knows", "since", null, pageSize, /* reversed */ true);
}
static void creatSchema(HBaseGraph graph) {
//直接插入数据, 可自定义ID
graph.createLabel(ElementType.VERTEX, "person", ValueType.LONG, "name", ValueType.STRING);
graph.createLabel(ElementType.EDGE, "knows", ValueType.STRING, "since", ValueType.DATE);
graph.connectLabels("person", "knows", "person");
final Vertex v1 = graph.addVertex(T.id, 1L, T.label, "person", "name", "John");
final Vertex v2 = graph.addVertex(T.id, 2L, T.label, "person", "name", "Sally");
v1.addEdge("knows", v2, T.id, "edge1", "since", LocalDate.now());
//用Schema模式来创建点/边,边必须单独连接起来
graph.createLabel(ElementType.VERTEX, "author", ValueType.STRING, "age", ValueType.INT);
graph.createLabel(ElementType.VERTEX, "book", ValueType.STRING, "publisher", ValueType.STRING);
graph.createLabel(ElementType.EDGE, "writes", ValueType.STRING, "since", ValueType.DATE);
graph.connectLabels("author", "writes", "book");
//开启Schema模式后,还支持一个计数(类型)功能,通过新增属性的方式加入
graph.updateLabel(ElementType.VERTEX, "person", "personCount", ValueType.COUNTER);
HBaseVertex cv1 = (HBaseVertex) graph.addVertex(T.id, 1L, T.label, "person");
cv1.incrementProperty("personCount", 1L);
graph.createLabel(ElementType.VERTEX, "author", ValueType.STRING, "bookCount", ValueType.COUNTER);
HBaseVertex cv2 = (HBaseVertex) graph.addVertex(T.id, "Kierkegaard", T.label, "author");
cv2.incrementProperty("bookCount", 1L);
//支持顶点和边两种索引
graph.createIndex(ElementType.VERTEX, "person", "name");
graph.createIndex(ElementType.EDGE, "knows", "since");
System.out.println("Schema创建完成");
graph.close();
}
//clear or drop graph (maybe drop namespace?)
static void clearGraph(HBaseGraph graph) {
graph.drop(); //实际底层操作是检查表是否存在-->存在就先disable-->再truncate(情况数据) --> 最后enable打开.
System.err.println("清空表成功");
graph.close();
}
}
0x03. 核心点探查
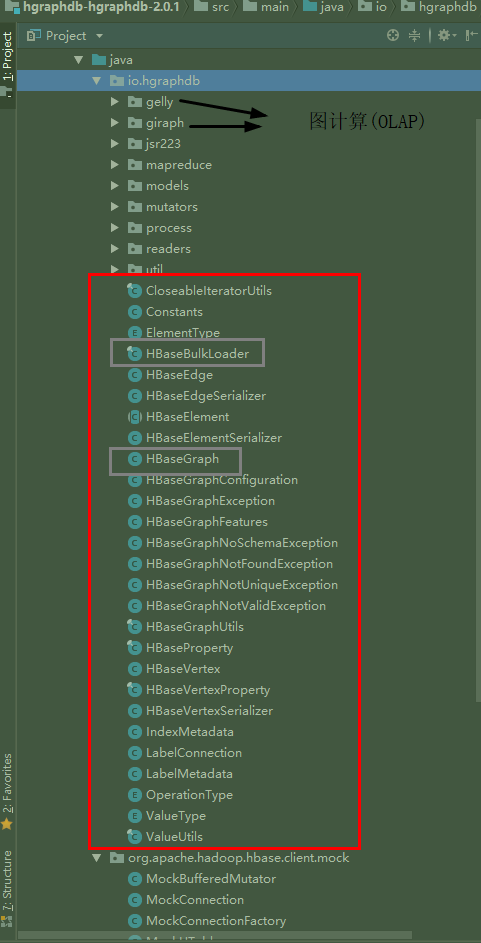
零. 代码结构
这是HgraphDB的整体代码结构图 ,如果看过之前Tinkerpop自己作者实现的Tinkergraph , 会发现这二者的结构是非常类似的, 首先只要是实现了Tinkerpop 的图,都必须遵循它得图数据结构定义, 实现Element ,Vertex, Edge ,Property ,VertexProperty ,Graph 这些必要的接口. 然后
一. 两种写入
HgraphDB提供两种方式进行写入, 一种是上面例子里的原生方式, 另一种是批量导入, 具体的差别和底层是什么呢? 具体看看代码
它自带有个HbaseBulkLoader类, 这个类简单封装了Hbase-client 的BufferedMutate接口的mutate方法, 与上面的常规插入点边对比: 本质是Hbase单条PUT和批量写的区别, 核心代码如下:
1 | /*1.这是直接写入的底层实际调用,省略异常*/ |
从上面自带的两种写入方式来看, 可以简单理解为就是:
- Hbase单条写(比如从hbase的命令行里插入数据) , 和N条数据一起写插入数据的区别,
- 批量写入的时候不会检查ID是否存在,节省了一次查的时间.
二. 写入工具
因为官方的HbaseBulkLoader实际就提供了一个口子, 现在让你导入10亿的顶点, 那怎么导呢? 怎么读数据, 中途失败了怎么办, 导了多少怎么看…
这实际就是之前原生JanusGraph 中也存在的问题, 缺乏一个批量导入的Loader工具 ,而因为HgraphDB是个人项目, 作者也没有管这个事, 直到偶然看到12月的一次分享里有阿里云的人分享了一次, 于是我本着一探究竟的精神, 就看看到底是什么回事….
虽然感觉是悄悄上线的, 不过找了半天….还是通过蛛丝马迹找到了阿里云自己写的一个导入工具 地址, 这里就来简单体验一下, 并看看有没有做什么进一步的优化 (功能 / 性能上). 首先来看看整体的代码结构和如何使用 :
(1). 使用
批量导入的准备工作:
- 准备图的schema文件
- 准备vertex文件
- 准备edge文件
最后使用hgraph-loader执行命令, 通过
main()传入参数执行相关的方法.
先看看给的数据格式参考:
1 | //这是schema.json文件,定义图的Schema结构,主要是围绕顶点/边 + 属性 + 属性索引 |
个人觉得这个schema的表示方式的确还是有点容易出问题….虽然json比较好懂..
从启动脚本里可以知道, generator.GraphBench.java 和importer.BatchImport.java 和schema.SchemaLoader.java 是三个启动入口, 功能也比较独立:
- 快速生成不同规模的测试数据集
- 加载Schema (通过读取JSON文件)
- 批量导入数据
但是这里发现好像直接复制了IBM的JanusGraph-Utils项目的大部分脚本和代码结构 …. (但是没有署名引用, 却把License直接改成阿里的了,貌似这样不太合适吧…)
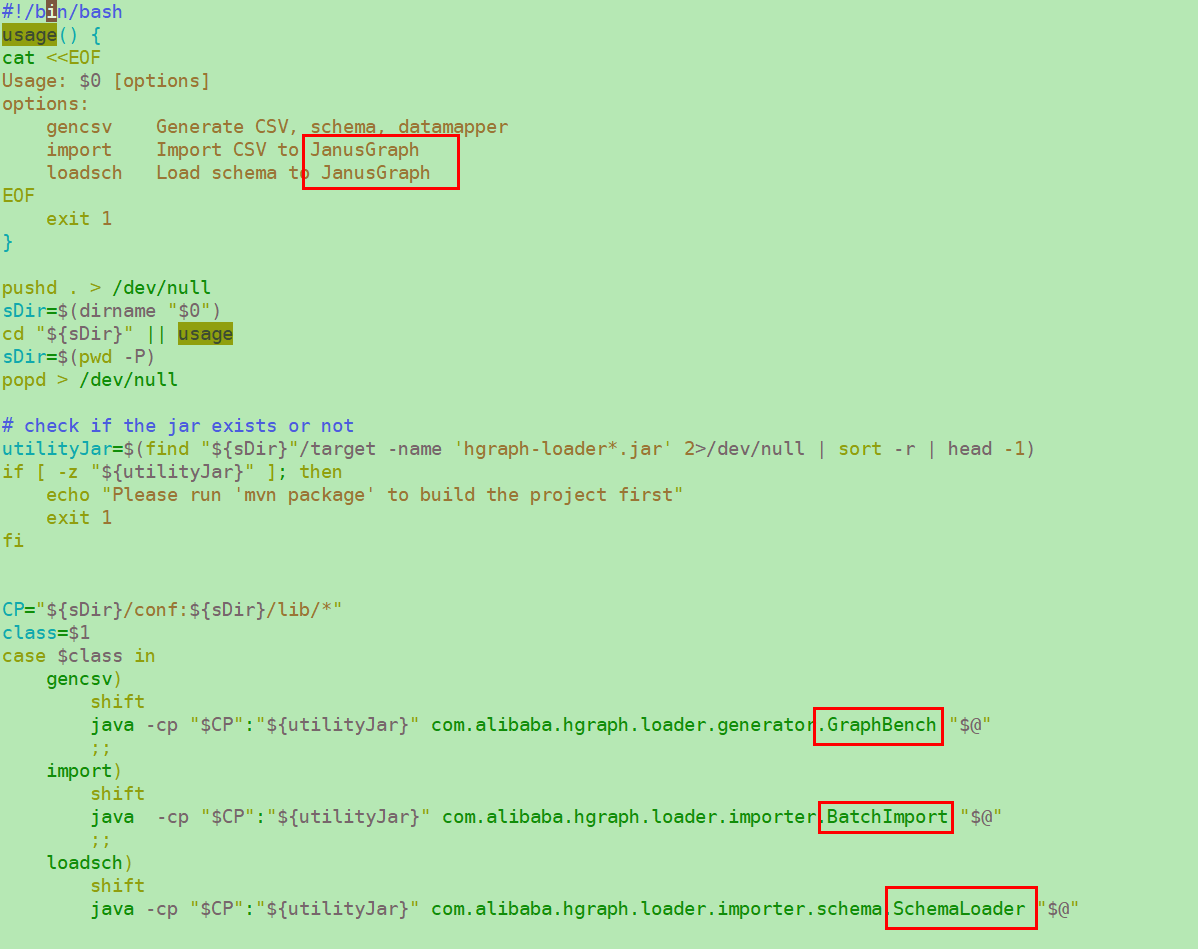
从shell和源码内传参顺序可以得知, 运行脚本方式:
1 | #生成数据,传入模板,和输出地址即可 |
接下来主要看看代码部分
(2). 代码结构
更新: 这里发现代码结构也大量复制的IBM的JanusGraph-Utils项目, 只是改了一下适用于HgraphDB…. 这是IBM项目的结构和代码..(见下图对比)但是同样没有看到任何声明和许可, 作为公开的使用/宣讲的项目(个人觉得应该予以说明吧…, 虽然貌似目前国内大家也都互相抄抄改改习惯了….)
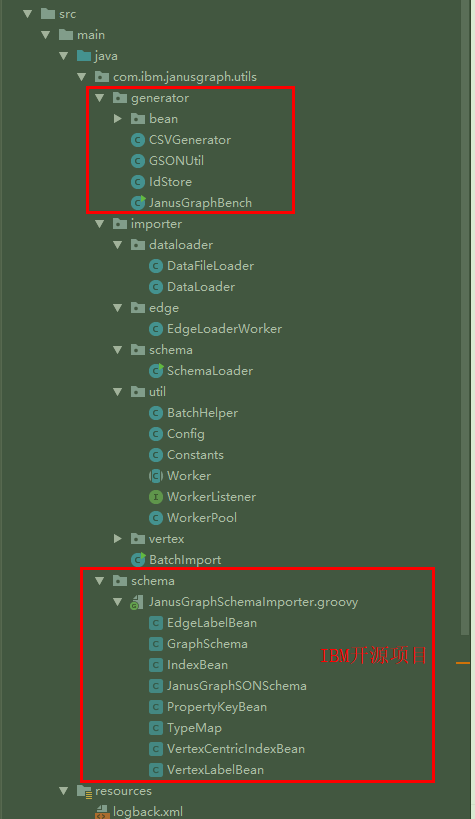
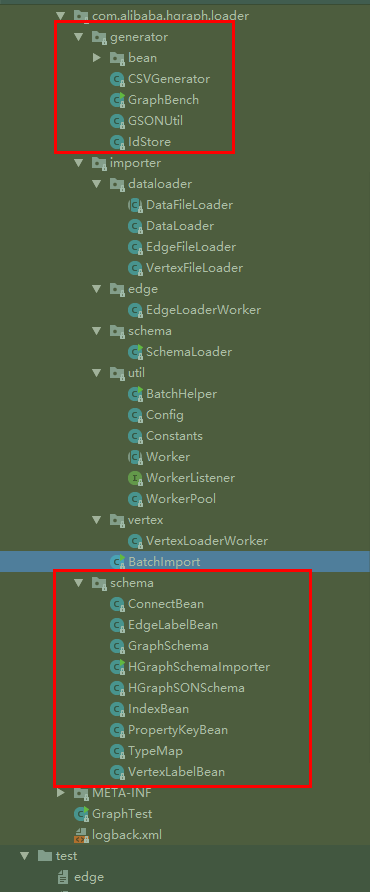
抛开这个, 先来看看代码本身吧,
代码分析未完待续….
1.19更新: 单纯HgraphDB的代码因为毕竟简单, 个人觉得可以先看看TinkerGraph 源码分析, 其实很多地方沿用了Tinkerpop 已有的读写实现, 而且不少功能也没有很好实现, 特别一点的在下面有单独说明 ,但是看完发现也没啥… 其他地方应该不是很需要单独源码分析了.
3.读取
这里主要列出与JanusGraph区别的地方 :
(1) label查询
HgraphDB的索引只针对属性(property)建立,如果要命中索引,
对于vertex,至少需要label、PK两个参数;
对于edge,至少需要Vid1、direction、 label、PK(默认是create_At)
若只传入参数label, 则会scan全表
1 | //举例:Iterator<Vertex> it = graph.verticesByLabel("a"); |
(2) 索引查询
定值查询(value):
1 | //简化代码如下 |
区间查询(range):主要用于int, date等类型的查询,本质利用HBase的Bytes.compareTo()方法实现
limit查询:利用HBase的compareFilter实现, 这里可以设置reverse
(3) 计数功能(COUNTER)
这个功能实际只是利用了HBase的计数器,在valueType中定义了COUNTER,作为一个属性存储
1 | //举例 |
(4) gremlin接口
TinkerPop提供了一个公共静态接口Graph.Features,用于表示Graph实现的gremlin功能。默认情况下,所有功能方法都会返回true`,也可以禁用不支持的功能,在使用TinkerPop的各种功能之前需要检查。
HGraphDB只是支持了比较基本的gremlin语句查询,包括查点、查边、查属性,对于Computer(path、pagerank等)和Transaction则没有提供支持。
附一些基本的查询语句:
1 | graph.createIndex(ElementType.VERTEX, "a", "key1"); |
4.图计算
HgraphDB虽然在存储端做的事不多, 但是整合了多个图计算的框架, 有如下:
- Spark Graph框架 ,使用示例 (可以理解为是GraphX的一个兼容性更好的发行版 ,可以完美兼GraphX数据)
- Flink Gelly框架 (运行在Flink上)
- Giraph (运行在MR上)
0x04.性能测试
采用的是文中提到了导入工具, 因为HgraphDB的读取测试几乎没法进行, 太多功能不支持. 主要是给一下写入测试参考: (3台Hbase节点,配置同Hugegraph测试一文.)
整体来看:
写入速度良好, 平均插入点15万/秒,插入边9万/秒. 但不支持事务, 基本的CURD支持很弱,很难满足常用业务需求 .
1 | --------------------dns------------------------- |
Server端资源消耗
- CPU: 1427% (us 39.6%)
- MEM:7.3%
- 网络:112M/s
注意: 与Hugegraph相比, HgraphDB的写入点边的速度是相反的, 这里后续会进一步研究具体原因. 以及Hugegraph为什么一条数据写两条边比顶点还要快许多.
附:A graph transaction supports
- Creating vertices, properties and edges
- Creating types
- Index-based retrieval of vertices
- Querying edges and vertices (批量点/边查)
- Aborting and committing transaction
0x05. 小结
1. 区别
以下是HgraphDB的不同于JanusGraph的特点:
- 拆分了点、边的表结构,属性分开存储(不拼接到一个value里)
- 允许用户自定义点/边ID(数字/字符串)
- 利用Hbase原生特性实现了范围查询和limit查询
- 利用Hbse实现了计数器的功能(目前看意义不大)
- 无序列化
HgraphDB的结构比较简单, 与Hbase可以深度集成, 如果需要是可以在这基础上做一些更深的定制开发. 配合导入工具后, 导入过程应该还算简单清晰。
2. 思考
目前可以想到的优缺点大致列一下:
优点:
- 结构简单清晰
- 表结构的设计与janusgraph相比确实合理很多
- 类似的提供
schema.json的文件方式(简化)给业务直接使用去新增/修改Schema, 而不是直接让他们用SDK去写Java程序.
缺点:
- gremlin支持的功能接口较少 (更新: 是很少, 会严重影响生产环境使用级别.)
- 周边工具很少.
- 没有完整的测试.
- 对于图计算的支持程度还需要进一步确认…
1.27更新: 实际的性能测试已经更新, 后续可能还会更新一下导入工具的相关对比分析… (其他估计不会更新了)