上一篇介绍了基于Hbase实现的HgraphDB的实现结构和目前阿里使用的导入数据方式原理, 但是感觉既不能胜任大规模的生产环境, 也过于冷门, 作为Hbase的一个插件是不错的, 但是跟完整的图系统还是有比较明显的差别.
今天来看看18年图开源项目里, 最值得关注的项目之一—–Hugegraph (from baidu-safety)
0x00.简介
首先Hugegraph 是目前开源图里生态上做的最完整的(暂时没有之一), 参考官方文档 ,整个模块包括**6个部分**:
- HugeGraph-Server : HugeGraph-Server是HugeGraph项目的核心部分,包含Core、Backend、API等子模块;
Core:图引擎实现,向下连接Backend模块,向上支持API模块
Backend:实现将图数据存储到后端,支持的后端包括:Memory、Cassandra、ScyllaDB、RocksDB、HBase及MySQL,用户根据实际情况选择一种即可
API:内置REST Server,向用户提供RESTful API,同时完全兼容Gremlin查询
- HugeGraph-Client:HugeGraph-Client提供了RESTful API的客户端,用于连接HugeGraph-Server,目前仅实现Java版,其他语言用户可自行实现;
- HugeGraph-Loader:HugeGraph-Loader是基于HugeGraph-Client的数据导入工具,将普通文本数据转化为图形的顶点和边并插入图形数据库中;
- HugeGraph-Spark:HugeGraph-Spark能在图上做并行计算,例如PageRank算法等 (**更新:**已下线)
- HugeGraph-Studio:HugeGraph-Studio是HugeGraph的Web可视化工具,可用于执行Gremlin语句及展示图
- HugeGraph-Tools:HugeGraph-Tools是HugeGraph的部署和管理工具,包括管理图、备份/恢复、Gremlin执行等功能
其中Server模块类似JanusGraph 本体, Client+Loader 模块类似一个 导入工具+Schema管理工具, Studio 是一个通用的Schema+Gremlin 展示的可视化界面, Spark端是帮助快速访问GraphX 的接口进行OLAP, 最后Tools是一个工具包, 帮助用户更快的上手和管理数据. 整体形成了一个比较好的图闭环 , 很有参考的价值,
0x01.整体结构
同样, 这里文档写的也比较完善 , 下面是官方给的模块结构图:
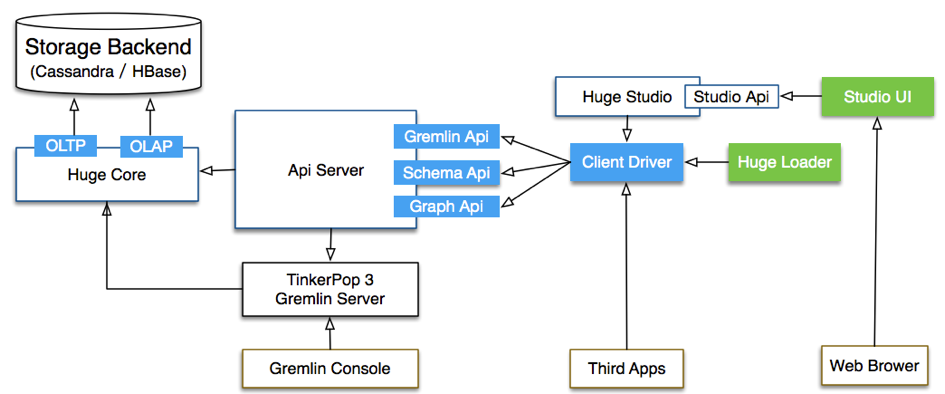
需要注意的是:
图中你可以看到, 它是同时支持两种方式去访问Core 的, 一种是我们熟悉的gremlin-server 的方式, 另一种是自己封装的RESTful ,而对用户/业务来说, 是只能通过中间层的RESTful-server访问, 不能直接访问gremlin-server的, 这个后面实际也会看到
这是补充说明后端的具体实现整体结构图: (参考自官方)
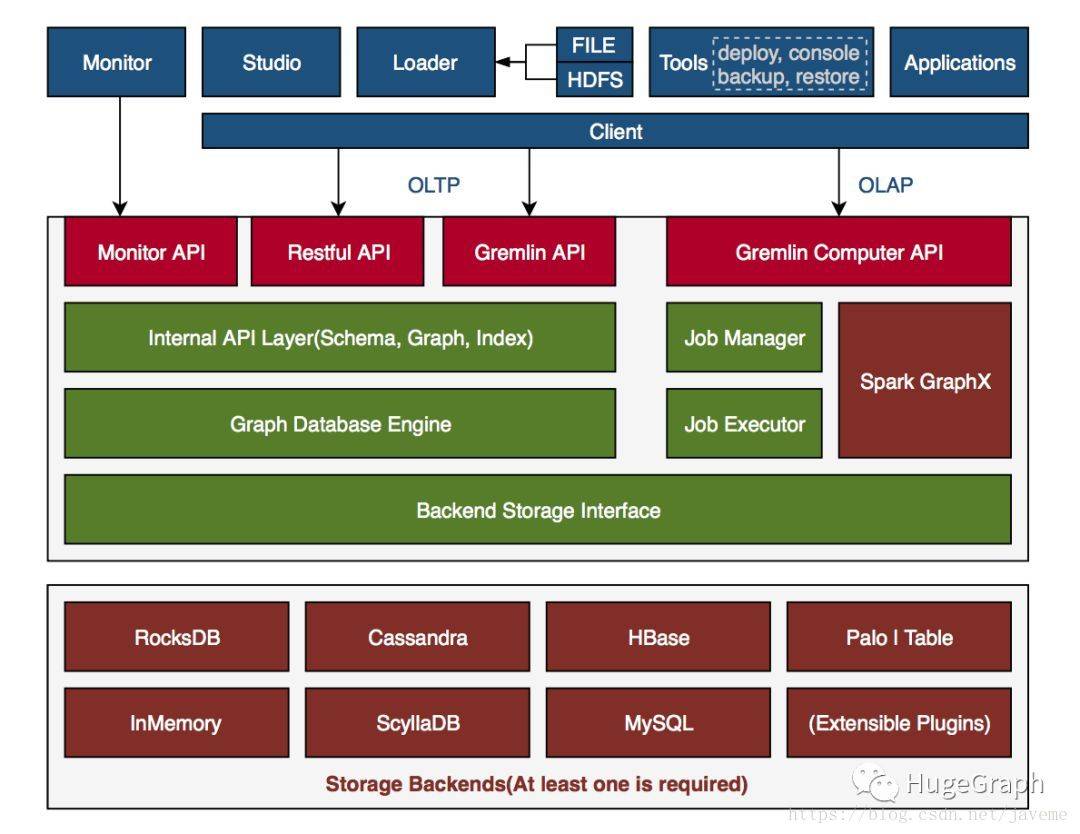
这里Index里的ES部分暂时没有实现, 思路应该是先不考虑ES引入的复杂性问题, 从后面来看这里采用的方式是用Cassandra/Hbase自己加表实现模糊查询的需求.
0x02.安装上手
因为结构类似JanusGraph, 就不多叙述了, 还是看看具体的改进点, 直接开始上手吧 ~ ( 后续版本若有更新,自行替换版本号)
A. 下载配置
这里Hugegraph提供了一键下载+安装的脚本和工具hugegraph-tools, 鉴于以后也要用这个来进行备份和其他测试, 所以统一用它管理吧
4.21更新: 以下下载地址都建议换为新版本.
1 | #(可选)如果是单机测试,rocksDB需要gcc环境 |
快速部署后, 默认启动的后端是调用的是配置文件内的rocksDB, 如果不是先终止修改一下, 并且修改一下默认的rest-server 地址, 详细配置可参考配置文档及配置项.
按照顺序, 可以先看看gremlin的配置文件, 但是里面没有需要修改的, 因为这里不同于JanusGraph的是, hugegraph单独提供了一个rest-server(见模块结构图) ,所以先修改一下server/conf/rest-server.properties , 下面都是必须修改的地方, 其他请参考文档:
1 | #改为主机实际地址,外网访问 |
主要核心是修改server/comf/hugegraph.properties , 也就是之前Janus对应的janus-cassandra-es.properties , 数据压缩参考 ,同样只列必须改动点:
1 | #根据自己需要修改为hbase/cassandra/scylladb,不同的配置会有其他影响 |
最后修改一下Studio 的配置文件, 在fe/conf/hugegraph-studio.properties , 同样只修改必须的, 其他细节设置参考
1 | studio.server.host=machineIP |
B. 启动服务
修改完成后, 手动启动一下server, 稳妥起见可以使用三部曲 : bin/stop-hugegraph.sh –> bin/init-store.sh –> bin/start-hugegraph.sh ,
1 | #再执行完init-store.sh后,如果是首次执行,会先提示hugegraph这个keyspace没存在,创建好后提示完成. 同时CSD中可以看到整个表结构 |
注意, 再强调一下, 不同于JanusGraph直接暴露gremlin-server的接口, Hugegraph访问的方式是先发请求到huge-restserver ,然后rest-server判断出这属于gremlin语句, 再转发到gremlin-server, 外部是不能直接访问gremlin-server的. 这样的好处是可以在自己的server做不少封装和改动, 且不需要改动gremlin的源码.
然后去studio的目录下, nohup bin/hugegraph-studio.sh & 后台启动前端, 成功后可以通过默认的ip:8088 访问页面, 并且jps 也会有一个进程(Java+React写的)
C. 添加测试数据
如果是第一次运行, 没有数据, 后续很多查询可能是空, 也不方面我们查看存储结构, 推荐使用自带测试的groovy脚本(./scripts/example.groovy) 去导入一些数据, 也可以使用web界面通过gremlin添加进去, 两个方法这里都会尝试, 先说直观的web方式
C1 . 前端创建图
这里参考官方的写法, 创建一个简单的人物关系图 . 在前端面板里复制下面语句, 创建 属性 -->顶点 --> 边 ,
1 | //等下顶点和边要使用的属性,先创建一下,本质是groovy语法 |
这是插入第一个属性后的数据库表变化.(原本就有13行数据/属性) ,这里值开头带有~ 的都是Tinkerpop定义的隐藏属性标志,详见 Hidden.hide() 方法.
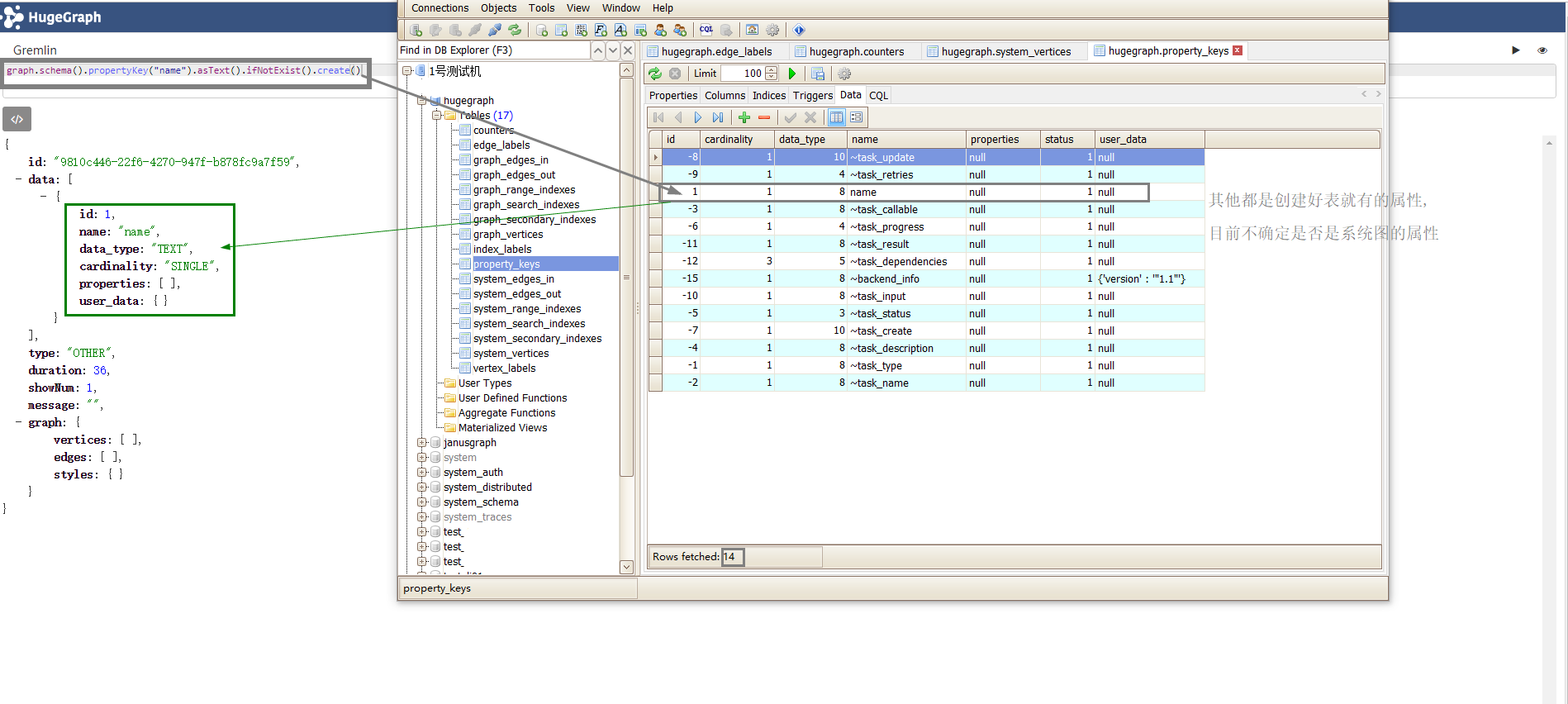
插入了第一个带属性的顶点之后的表变化情况: (注意观察每个项的值, 后面存储结构里再详细说)

插入一个边Lable后, 表变化
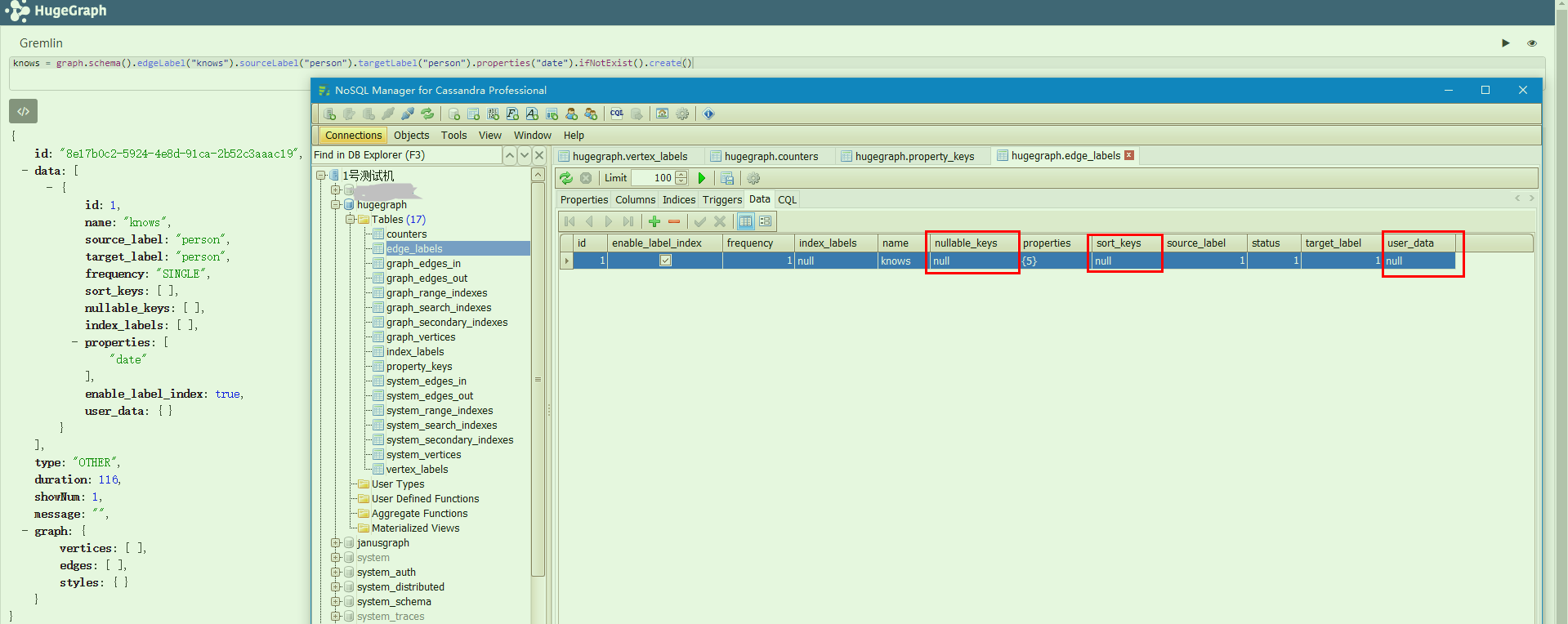
插入实际的边数据之后:

最后再导入一些示例数据, 看看完整的可视化展示图: (可以拖动 + 显示详情), 注意此时所有system 表都是空的,没有数据.

总体来说, 体验应该算挺不错了, 输入gremlin语句有自动的关键词提示, 然后能比较好的展示实际数据结构, 显示的信息也比较完善, 用户也可以比较方便自定义化展示方式, 如果要在这上面做封装也会比较方便.
C2 . 批量导入工具
使用Hugegraph-Loader 来进行数据+Schema的批量导入, 那这时候我假定整个DB都是空的, 包括Schema和数据我们都用导入工具去导入/修改 ,那显然至少得准备:
- 图模型Schema文件 (groovy)
- 点 & 边的数据文件 (csv/text/json , 建议按不同点/边分文件夹放置)
- Schema和数据的映射文件 [也就是(1)和(2)的映射] (json)
具体的数据因为篇幅问题就不单独列出了, 这里说一下批量导入的时候, 实际生产上各参数的配置和相关问题:
- 首先目前看暂不支持匹配通配符
*,所以文件需要一一映射, 而不能匹配多个文件, 后续可能优化或自实现PR - 最好是不要使用
mapping字段, 它是作别名使用, 但是容易与header的内容有理解错误.. - 参数的优化这个还得实际测测…
1 | #合理么? 需要修改多线程么? 为什么修改batch_size会卡主或特别慢? |
0x03. 基本操作
上面完成了整个部署安装, 如果已有
Hbase/Cassandra环境. 参考上面的文档大概10分钟内可以完成环境搭建, 还是非常方便的, 那接着来看看具体的一些CURD请求
HugeGraphServer(后面简称HGserver)封装的REST-API提供了多种资源访问方式, 常见的5种: (建议postman内测试)
graph: 查询vertices、edges(e.g. :IP:8080/graphs/hugegraph/graph/vertices)schema: 查询vertexlabels、propertykeys、edgelabels、indexlabels(e.g. :IP:8080/graphs/hugegraph/schema/vertexlabels)gremlin: 执行gremlin语句 , 可以同步或者异步执行 (e.g. :g.V())traverser包含各种高级查询,包括最短路径、交叉点、N步可达邻居等task包含异步任务的查询和删除
前面几个是常见的CURD操作和显示一些帮助信息, 这里重点关注gremlin, traverser 和task, 特别是异步任务.
A. Gremlin(同步+异步)
这可能是最常用的操作之一, 就是把之前Janus中的gremlin-server 嵌了进来, 支持bingdings/aliases 参数为gremlin查询使用.
1 | //1,同步方式 |
当然稍有不同, 如果直接传入之前的g.V(vid) 语句是会报错的,这里是直接使用的图实例对象, 获取了它的遍历器之后再去做查询,不过参考官方:
可以通过
"aliases": {"graph": "hugegraph", "g": "__g_hugegraph"}为图和遍历器添加别名后使用别名操作。其中,hugegraph是原生存在的变量,__g_hugegraph是HugeGraphServer额外添加的变量, 每个图都会存在一个对应的这样格式(_g${graph})的遍历器对象。此时, 响应体的结构与其他 Vertex 或 Edge 的 Restful API的结构有区别,用户可能需要自行解析。
B. Task(异步)
因为Gremlin 默认的同步方式去执行任务, 很多计算量稍大的任务就会超时或者严重影响使用, 比如g.V().count() 这种操作, HG这里提供了一个异步的方式去执行任务, 并提供了相应的任务信息接口.
1 | //1.查看所有task |
C. Traverser
这里其实就是封装了之前Gremlin 支持不友好的图算法, 比如PageRank, K-out, K步邻居, 最短路径, 全路径查询, 社群发现, 批量查询等.. 效果接近TigerGraph的函数封装, 传入相应的参数就能直接获得所需返回值, 避免自己去拼凑冗长的gremlin语句, 通过这种方式可以针对业务层做许多常用查询的封装, 能极大提高使用体验和效率..
下面列举几个典型代表:
1 | //1.最短路径. (返回的一条最短路径) |
相关代码实现见HugeTraverser.java . 后续补充
0x04.存储结构
1.12更新: 在Hbase中表名是稍有不同的, 都缩写了(不知道为什么), 阅读起来很不方便… 然后把Cassandra里的多个字段组成的主键换为了拼在一个RowKey 中, 所以字段数目也是不一样的 (详细的代码实现在BinarySerializer 中 ) 这个要注意, 至于其他区别我继续看ing
先看看整体上与JanusGraph的表结构对比, Janus把所有点边属性存在一个edgestore表中, 而HG把他们拆的很开, 类似传统ER结构, 很好理解, 每个表各司其职. 其次各个表格拆开多到了17个表例如:graph_vertices,graph_edges_in,graph_edges_out,Xxx_labels 以及单独的counters, 并且把系统需要存储的特别信息(比如jobs)也单独拆开了.. 当然核心的表还是非system表, 如图所示:

对比可以看看, 这是之前JanusGraph的表结构.
顶点Label表 :

几个问题:
这里字段的
primary_keys是什么意思? 什么作用答: 只有当ID策略是
PrimaryKey的时候才会有值, 此时ID由一个或多个属性组成, 它不能和nullable_keys(可空属性)有交集.开启
label_index是什么意思, 在哪存储的?答: 关闭的时候, 类似
g.V().hasLabel('person')这样的查询无法使用, 不过打开此项会降低插入速度 & 增大存储, 如果确定不需要可以关闭, 至于labels的索引存在了哪里, 简单说是存在了二级索引里, 详见索引专栏..user_data是做什么的 ? (其他表同理)答: 可以理解为一个备注/约束信息, 常用方式是通过
HTTP的PUT请求, 支持append(增加) 和eliminate(删除) 的方式和效果参考下图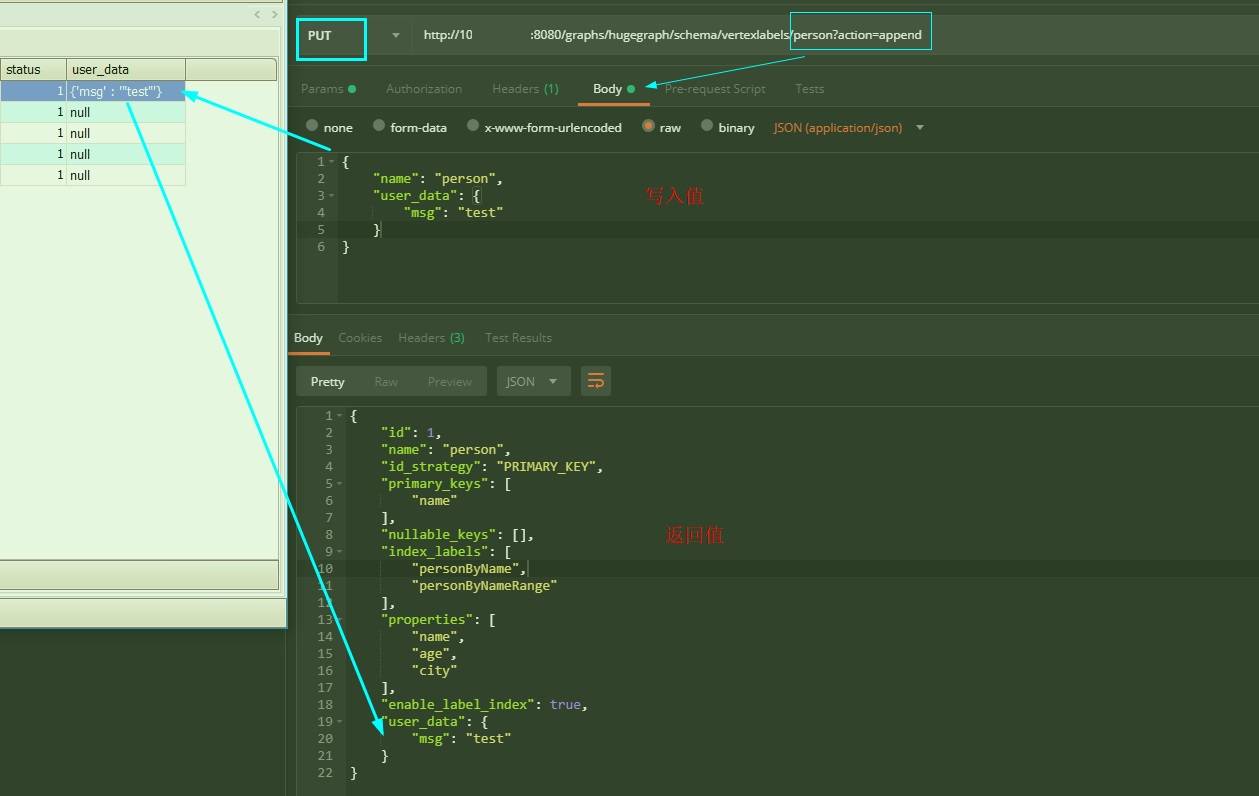
顶点数据表 :
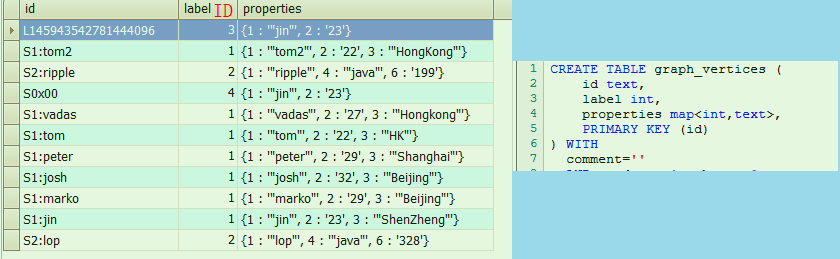
这里properties存储的是map<int,text>类型, 前者是属性的labelID, 后者是属性值, 中间的是顶点LabelID, 关联顶点Label表.
边Label表 :

疑问:
frequency字段是什么含义, 有哪些选择, 什么约束? 答: 表示两点间同名边是否唯一, 类似Janus中边的multiplicity属性, 做了简化, 只有one/many.- 两点之间的多条同名边如何区分? 答: 可以使用不同
sort_keys的方式 ? 还有么?
出/入边数据表:
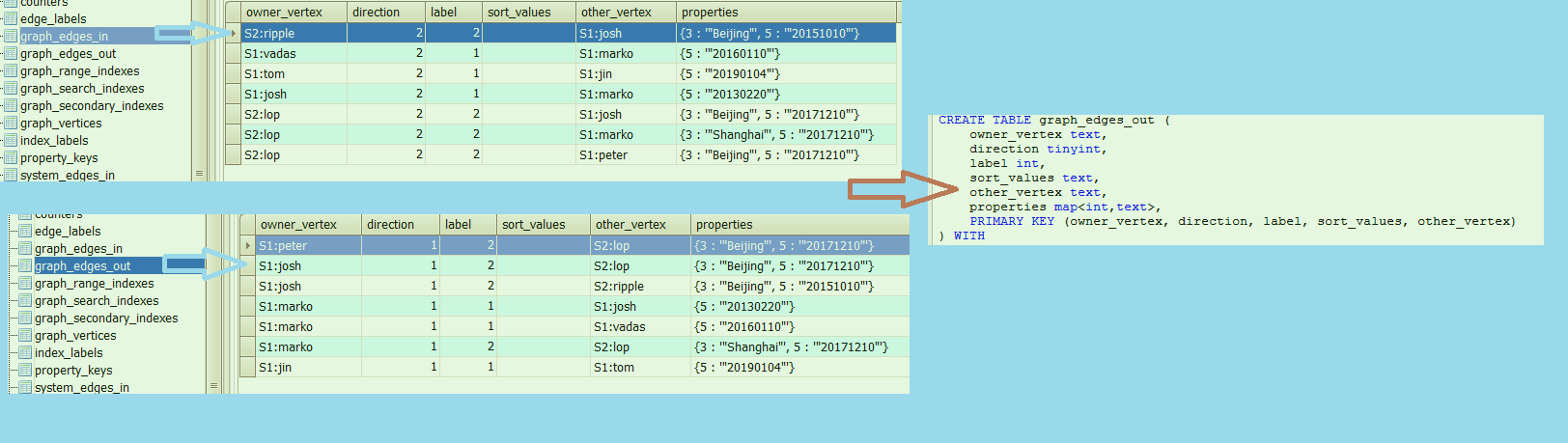
两表结构是完全一致的, 并且不会实际存储边ID , 并且依靠sort_values 来解决一些关键问题 , 类似的思路, 还能有一些相关的优化点么?
属性表:
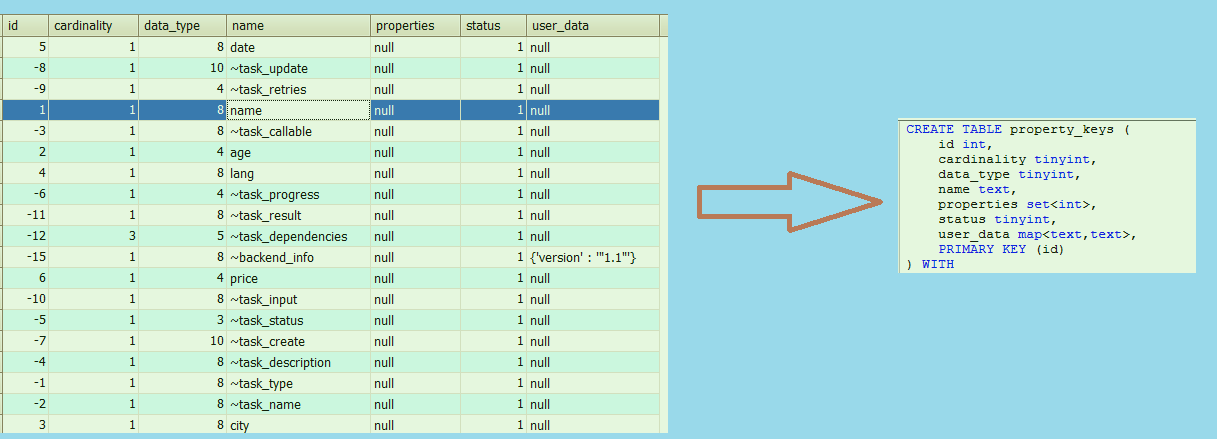
问题:
- 这里
properties字段表示什么意思? 答 : 从源码看还没有支持, 可能是嵌套属性的功能. Cardinality是什么意思? 答: 和JanusGraph中一样, 这其实是最早Tinkerpop就定义过的一个枚举, 比如允许属性值为Single/ List /Set.
索引Label表:

这里注意index_type 对应的是三种索引类型, base_type 和base_value 是指的点/边Label的数据, 前者代表VertexLabel 或 EdgeLabel, 后者是对应的LabelID ,详情可见源码IndexLabel.java .
索引数据表:
这里有前缀 & 范围 & 全文 三种索引数据, 根据实际需求建立一个/多个索引, 同样表结构是近乎相同的. (range的顺序颠倒了一下, 这会影响主键匹配的优先级 ,待代码确认)
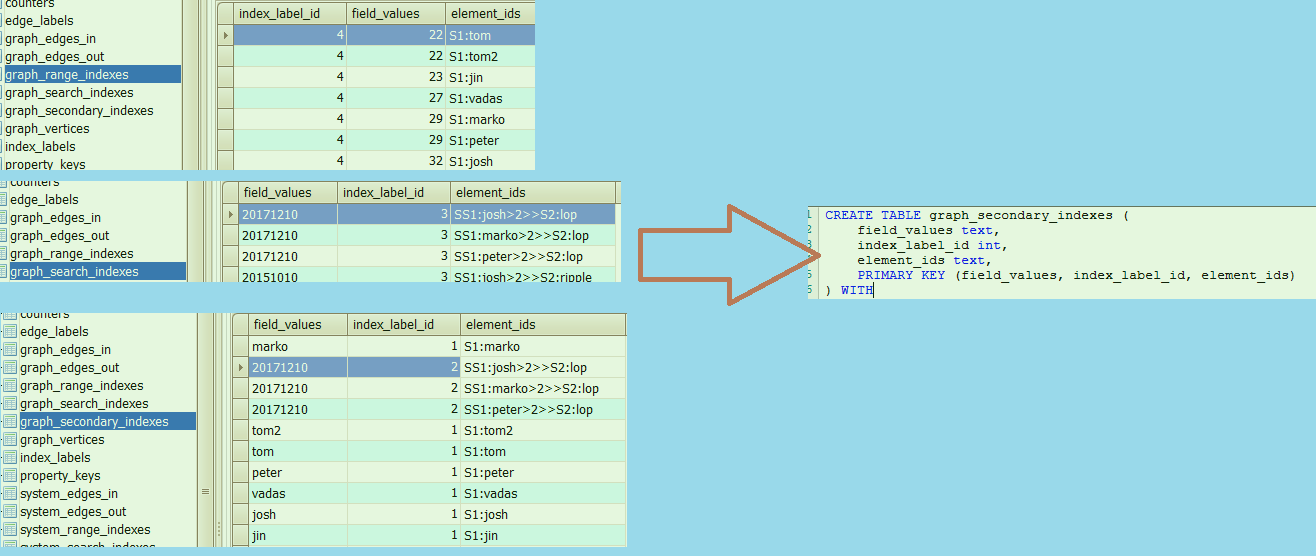
这里提几个问题:
Q1: 为什么前缀索引和全文索引的结构都是value+labelId+elementId ?
A1: 因为考虑到后端Rowkey尽可能的打散, labelId绝大部分都是相同的.
Q2: 那为什么范围索引又把labelId放在最前面? 还有为何只支持数值类型呢?(理论上a~z的字母序也是可以的吧)
A2: 第一个问题可能得想下, 范围查询在后端写条件的时候怎么写(startkey+endkey), 假设要查年纪>22的labelId是4的点, 如果第一个值是value, 那大于22要扫多少startKey.. 但如果第一个是labelId, 就可以确定只扫4的前缀, 然后再扫比22大的部分. 第二个询问作者反馈是因为用字母范围的查询还很少见.. 暂时没支持.
这里通过这三个字段可以保证索引数据的唯一性, 至于具体模糊索引的时候怎么使用它们的, 在[索引篇](#0x06. 索引相关)具体说明.
最后是Counters表 :
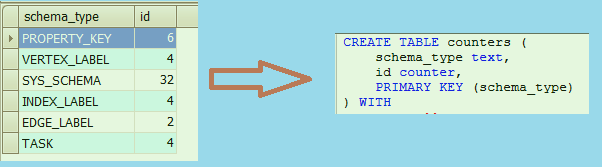
这里目前只记录和核心的系统属性的数目, 后续应该可以把每个顶点/边/属性的数目也使用某种方式记录一下, 但是如果是写入的时候原子的自增, 那应该会有不少速度上的影响 ? 对应源码参考LocalCounter.java .
系统表的结构和和数据表是完全一致的, 目前还不太清楚为什么要单独分开存放, 以及它的索引表是否也需要三张?… 这里就不重复列举, 后续理解了具体设计含义再说.
0x05. ID策略(简略)
A.顶点ID策略
Janus中ID是一个很重,耗时,且缺乏自定义的设计, 这里HugeGraph(后续简称HG)做了不少改动 , 核心类VertexLabelBuilder. 简单说它有三种生成策略:
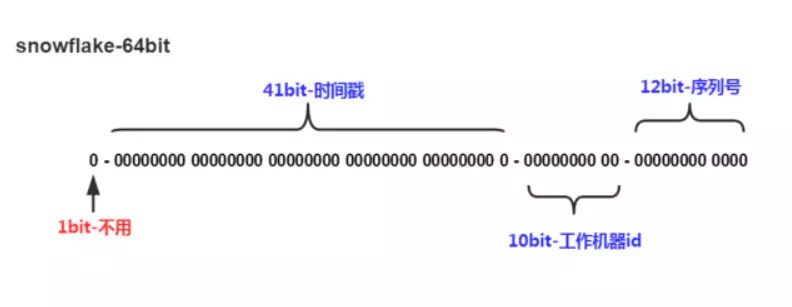
(默认)自生成 : 通过推特开源的Snowflake算法生成全局唯一的Long类型id, 对应源码是
SnowflakeIdGenerator.javasnowflake(雪花)是分布式ID生成算法. 核心思想是:使用41bit作为毫秒数,10bit作为机器ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0 , 总共也是64位.
如图所示, 这个算法单机每秒内理论上最多可以生成1000*(2^12^),也就是410万ID/s , 通过添加时间戳校验可以优化此算法
主键方式: 这是通过组合
顶点Label+主键的键值对组合生成String的ID , 这里顶点Label取的是labelID比如假设Person顶点的VertexLabel 的ID是1, 那么通过主键组合生成的顶点实际ID就是
1+Jin) , 这有个很大的优势在于此时RowKey就带有属性值, 如果属性查询则可以不额外创建单独的索引直接查到相关顶点值, 最后, 重复值自动覆盖.自定义ID: 支持String和Long类型, 这与HgraphDB思路一致, 需要业务自己去维护ID唯一性, 并保证ID不能过于长 (<128B?)
B. 边ID策略
HugeGraph的EdgeId是由fromVID+edgeLabel+sortKey+toVID四部分组合而成, 也就是说在边表中是不会单独存储edgeID 这个字段的, 边的ID是完全拼接组合得来的, 比如: 1+likes+date+2 ,date是边的某个属性. 详见源码EdgeID.java 部分 (后续补充)
其中sortKey不仅用于排序, 还是作为Edge的唯一标识, 原因有二:
- 如果两个顶点之间存在多条相同Label的边可通过
sortKey来区分 - 对于超级节点,可以通过
sortKey来排序截断 . 最新版已经支持通过sortKey在某个指定范围查询
由于EdgeId是由srcVertexId+edgeLabel+sortKey+tgtVertexId四部分组合,多次插入相同的Edge时HugeGraph会自动覆盖以实现去重。 (如果批量插入Edge的属性也会被覆盖
另外由于HugeGraph的EdgeId采用自动去重策略,对于self-loop(一个顶点存在一条指向自身的边)的情况下HugeGraph认为仅有一条边,对于采用AUTOMATIC策略的图数据库(例如Janus)则会认为该图存在两条边。
0x06. 索引相关
A. 普通索引
目前HG支持三种索引类型, 对应源码core包中的IndexType, DB中对应三张同结构不同名的表, 分别是:
- secondary (前缀索引) : 支持索引按前缀搜索 , 并且支持多个属性的联合索引
- range (范围查询) : 主持数字的范围查询 (可以考虑IP?)
- search (全文检索): 最新支持, 可能还不够完善
所有索引表都是三列: filed_values - index_label_id - element_ids , 主键是三者的联合 (共同确定唯一性?)
1 | //创建顶点的前缀属性索引 + 顶点的范围索引 |
创建了以上单个属性之后, 你会发现system_secondary_index 表也添加了两条数据, index_label_id = -14 , 这里参考源码TaskScheduler 的initSchema() .不过这里还不知道System表们具体作用是什么.. 但是你建完四条索引后, 可以发现system_vertices 中多出了四条task顶点数据

补充: (TODO)
range_index 表的主键顺序跟其他两个稍有不同, 需结合代码确认一下数值的范围到底是怎么查的, 具体代码参考RangeIndex ,以及范围查询的解析地方(?)
B. 二级索引
少部分顶点/ 边 /属性的自有索引, 是采用的DB自身支持的二级索引的方式实现, 以Cassandra为例, 开启了表内的label_index选择后, 会自动创建对应的二级索引, 这个要在DB的system_schema 这个keyspace里才能看到, 至于二级索引具体怎么存取的, 就不再这细说了… 反正直接查看是看不到实际的索引数据的. 至于hbase2中是否有支持, 待后续代码里确认更新.
创建二级索引调用的是通用的createIndex()方法, 位于CassandraTable.java 中.
0x07.对比JanusGraph (初步)
优点:
- HugeGraph代码结构清晰, 去掉了许多Janus中实现麻烦且有很多坑且使用率很低的功能 (
e.g:TTL功能, Thrift接口, ES部分, 序列化, 复杂的ID生成, 大量Check) - HugeGraph接口更为友好, 方便自己修改代码并实现特定功能.(包括HugegraphServer等于是多了一层非侵入的代理)
- HugeGraph拥有较完善的工具组件: 目前有HugeApi + HugeGraph-Client , HugeGraph-Loader(导入数据) , HugeGraph-Studio(可视化)等的工具组件, 形成了一个完整的闭环.
- HugeGraph可以充分利用后端存储系统的特点来实现数据高效存取,而Janus用统一的K-V结构封装了一层黑盒, 无视后端的差异性。
- HugeGraph的VertexId和EdgeId都可以自定义,可实现自动去重,读写性能更好。Janus的所有Id均是自动生成, 属性查询都需经索引, 且对业务无意义
- Hugegraph在边上通过设计清晰的
Sortkey,并支持通过区间直接取值, 可以大幅改善超级顶点的查询问题. - 有单独的Counter表, 后续想好方案, 可能支持每个顶点和边和属性的个数单独统计.(不过不清楚效率? )
1.19更新: 优点这缺失了一些, 详情见作者文章 .后续我整合一下.
不足:
- 稳定性可能还待考证, 去掉的大量检查虽然可以提高不少读写效率, 但是高并发大数据量的环境不知是否可靠 (另外社区参与活跃度?….)
- 目前Server仍对接了多种DB, 应对不同的需求场景, 还能再做减法, 砍到只剩
Cassandra / Hbase2(集群) + Mysql(单机). - 目前主要对Cassandra的优化/定制化比较多, 对Hbase还缺乏定制.
内容已拆分, 后续的核心问题和代码分析见后续文章.. (Hugegraph的一些问题解析和代码阅读 + 性能测试)