上一篇文章介绍了Hugegraph(HG)的整体结构和存储结构. 以及整个安装和使用过程, 不涉及具体的源码. 这篇文章结合源码来进一步探究图系统设计的一些关键点, 和对比Janus的差异具体如何实现的.
0x00.准备
分别下载好所有的模块和包, 然后确保分支是在master 上, 因为更新频率较快, release版本和master之间差别也有不少了(最新已经到0.9.1) ,然后配置一下debug所需的修改, 因为HG的测试覆盖了大部分方法调用, 所以建议直接复用它的hugegraph-test 模块, 并新建一个分支, 避免之后拉取和master冲突.
1. 代码风格(必须)
在IDEA设置里配置这几项, 以免后续出现大量不必要变动 : (可直接导入我提供的配置文件)
修改自动换行为80, 并设置虚拟线80 (搜
Right margin), 设置项目换行为LF取消自动导包 (Auto import下) . 禁止使用
import *(在Code Style–>Java –> Imports), 但保留自动删除无用包(Optimize imports on the fly)调整包导入排序, 否则默认和官方会有许多不一致. (详见xml文件)
对齐比较难受, 我现在还没去细管如何设置一个规则, 先给以下参考…让它符合官方要求的对齐, 手动对齐就千万别用全局代码格式化了.
在
Code Style里的Wrapping and Braces, 勾上Ensure right margin is not exceeded.(关键)调整
Extends/Implements,Throws list,Method declaration parameters,Method call arguments,Chained method calls,Binary expressions,Assignment statement,Ternary operation,Array initializer,Assert statement,Parameter annotation,Annotation parameters,以上所有的wrap选项为
Wrap if long,并勾上Align when multiline,调整
if/for/while/do-while/try-with-resources statement的Force braces为When multiline,或Wrap if long,设置
Enum constants为Wrap always
上面这一大堆我想没人愿意去调, 为了方便大家我把调好的配置命名为hugegraph-style , 然后推到了社区github上, 有需要的同学可以自行下载导入, 有好的改动可以直接在社区提交 PR 修改.
2. PR须知(可选)
关于版本控制和代码规范参考:
3. 本地调试(可选, 建议)
a. Server端
因为目前版本的mvn编译时候有一些脚本都是Unix 风格的, 所以Win上不能直接使用mvn编译, 那每次上传到远端调试太麻烦了, 在作者提醒下, 才想起可以用手动的方式在Win本地起Server, 这样许多测试就方便太多了. 直接说步骤: (Mac是一样, 只不过不用特殊处理path)
首先copy一份配置文件到你本地一个目录 (e.g:
hugegraph/hugegraph-dist/src/assembly/static/conf) , 假设本地是D:\conf, 在IDEA的Run/Debug configurations里新建一个Application, 然后先选中Use classpath of module为hugegraph-dist, 再设置Main class为InitStore根据初始化脚本, 我们需要手动传入
gremlin-server.yaml文件, 这里写D:\conf\gremlin-server.yaml, 然后保存把
gremlin-server.yaml文件里的graphs配置值用双引号括起来写绝对路径, 不然会一直提示找不到文件. 然后单机运行的话, 建议修改hugegraph.properties的backend为Mysql(自行安装). 然后保存后, 运行InitSotre, 不用rocksdb是因为在win安装很麻烦(Mac可直接用)1
2
3
4
5
6
7
8
9graphs: {
hugegraph: "D:\\conf\\hugegraph.properties"
}
# 最新的Server更新了Tinkerpop版本,你需要用新的模板替代
# 从dist复制groovy脚本, 并修改scriptEngines的最后选项
org.apache.tinkerpop.gremlin.jsr223.ScriptFileGremlinPlugin: {
files: ["D:\\conf\\scripts\\empty-sample.groovy"]
}提示初始化成功后, 再修改刚才配置的
Main class为HugeGraphServer,然后加一个配置文件如D:\conf\rest-server.properties,这里注意不能加双引号, 也要写绝对路径.1
2#得这样写...反斜杠最好别省
graphs=[hugegraph:D:\\conf\\hugegraph.properties]最新版已经加入了License校验, Win下要注意路径匹配规则不一样. 需要复制秘钥后这样配置:
1
2
3
4//前面的四选项不用改变, 如果你想改变第四个选项,会比较麻烦...
{
"license_path": "D:\\conf\\hugegraph-evaluation.license"
}
- 再就可以在各种测试里愉快的对代码进行调教了, 然后JVM观察也会方便许多
- 注意, 如果你发现更新了
Master代码之后运行Server失败, 那么很可能是以下两种原因:- 配置文件更新改了, 和原先的冲突 (你需要查看最新的配置文件, 然后适配一下)
- 后端的数据结构改变了, 导致初始化失败 (你需要清空/或删除本地DB, 然后重新初始化图)
b. loader端
loader端主要是新版在Win下可能有个很蛋疼的配置文件插件bug问题, 导致无法生成测试用的profile.properties文件, 解决办法参考Stackoverflow后如下:
1 | <plugin> |
持续更新ing…(最新更新于19.9.19)
0x01. RocksDB/Hbase存储格式
3.21更新: hbase里有一张单独的schema_si 表, 专门用于给系统属性做二级索引, 所以总共有18张表… 注意别忽视了.
上一篇文章已经很详细的介绍了在Cassandra/Mysql中采用的Text序列化器写入的存储格式 ,由于RocksDB和Hbase自身存储的是字节流, 加上与Cassandra稍有不同的是, 它的RowKey也不是Primary Key 指定多个字段的方式, 而是直接拼凑在了一起存储, 那具体区别有多大呢? 这里来具体看看
先简单看看大致的存储结构对比Cassandra的区别, 大致我们把表分为三块 : Schema(元信息4张) + 数据表(顶点+边+索引共5张) + 系统表(8张) , 字母是Cassandra中对应全称的缩写 (比如vl –> vertexLabel), 大家自行脑补一下哈哈~
顶点和边和索引和属性的Lable表:
基本和Cassandra是一样的, 一行对应多个Column+Value, 索引Label表就不单独截了.
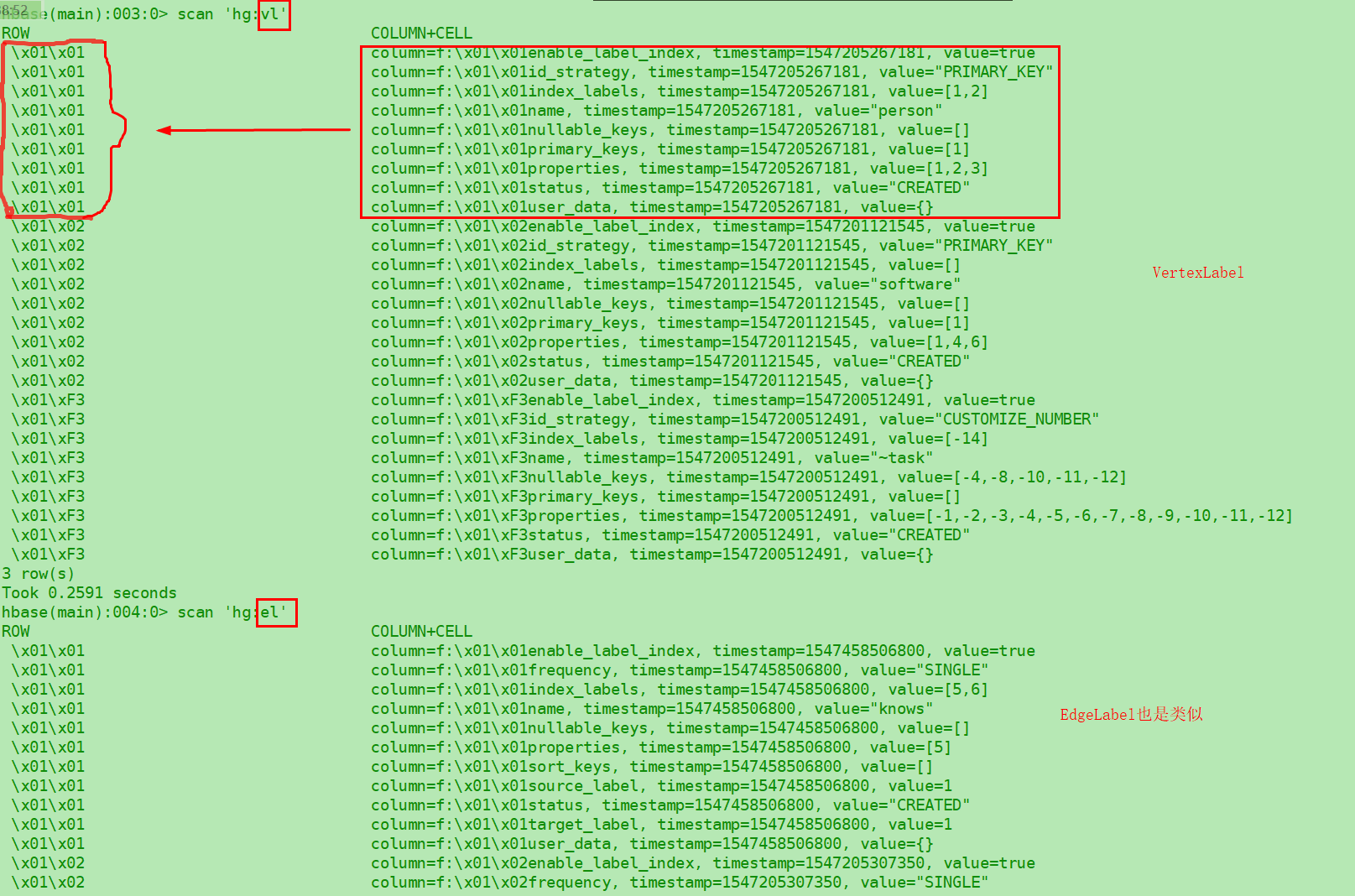
数据表这里,分顶点+边 和 索引表来看:
顶点和边的数据表:
这里属性值在Cassandra中是map的, 都被拆成了多个Column-Value ,也好理解 ,稍微不同的是二进制序列化的方式, 在Hbase里直接查看可能不太一样…后续需要一个小工具来反查一下…

索引数据表:
这里是稍微特殊一些的, value是空, 把ElementID的值放到了ColumnName里, 但是不清楚f: 这个前缀是哪的, 之后对着代码检查一下.
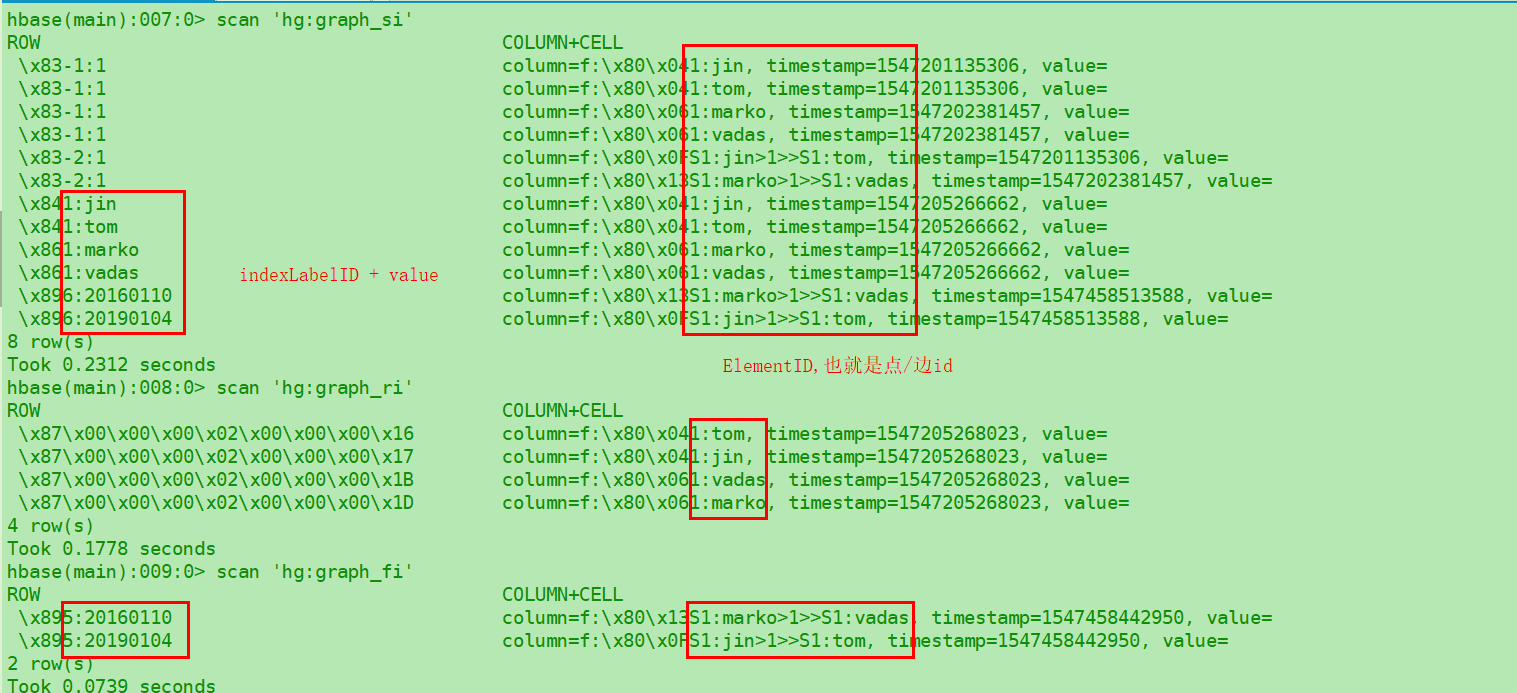
从上篇文章我们已经知道了核心是对应的BinarySerializer ,这里是Rocksdb和Hbase读写操作的通用表示, 有上千行代码, 所以分两类来看看:
Schema写入

数据写入
写边数据的rowkey:
1 | protected byte[] formatEdgeName(HugeEdge edge) { //注意rowKey != edgeID ,去掉了direction才是 |
写索引数据, 核心也是RowKey :
1 | public static Id formatIndexId(HugeType type, Id indexLabel,Object fieldValues) { |

0x02. 插件特性
定制化的确挺重要, 之前Janus最大的问题就是不好定制化, 做什么改动多需要改动源码或更侵入的改动Tinkerpop , 那么HG在这里对外提供了一种Plugin 的机制, 等于开了一些口子方便用户不修改源码的基础上, 进行几个维度的定制化:
- 自定义/扩展对接后端 (不修改源码)
- 自定义/扩展全文检索所用的分词器 (不修改源码)
- 自定义/扩展序列化(写入)方式
- 自定义配置项 (比如Hbase的连接配置?)
从总体看, 以上4点还是挺关键的, 那接下来看看具体实现机制:
- HugeGraph提供插件接口HugeGraphPlugin,通过Java SPI机制支持插件化
- HugeGraph提供了4个扩展项注册函数:
registerOptions()、registerBackend()、registerSerializer()、registerAnalyzer()- 插件实现者实现相应的Options、Backend、Serializer或Analyzer的接口
- 插件实现者实现HugeGraphPlugin接口的
register()方法,在该方法中注册上述第3点所列的具体实现类,并打成jar包- 插件使用者将jar包放在HugeGraph Server安装目录的
plugins目录下,修改相关配置项为插件自定义值,重启即可生效
补充: HTTP访问也可以自定义/扩展权限认证, 参考
0x0n. 几个问题
1. Hugegraph更新属性的只需要按需取操作, Janus需要读写?
这里意思是说Janus存取Blob数据的方式, 不管读写多少数据, 都需要拉取出一整行的许多数据, 而可见的DB可以直接按需进行属性更新, 效率肯定更高…
2. Hugegraph封装的Hugeserver里对Tinkerpop的封装是什么样的?
图待补充… 目前来看, Gremlin的部分,是做了原生的转发, 没有做单独的改动, 自主实现是直接跟Server通信.
分两种情况, 一种是同步的, 在api包下的GremlinAPI 类中, 主要是针对GET/POST方式做了原生的Request & Response封装转发到gremlin-server中.
另一种是异步执行的任务, 在job包下GremlinAPI 类的GremlinJob 中可以看到:
1 |
|
3.如果对Cassandra使用了二级索引, hbase上是怎么复用的?
先说结论 : Hbase上没有复用暂时, 如果自己的hbase版本支持了二级索引, 自己实现. 查询是通用的
先说一下HG的序列化设计, 首先它试图依靠SerializerFactory 来统一管理 (但是目前只是管理了binary和text),读取你配置文件中设置的serializer 选项,映射到不同的序列化器, 比如:
- binary/rocksdb/hbase: 对应
BinarySerializer, hbase继承实现为HbaseSerializer,但是并没有专门写内容 (最新参考) - text: 对应
TextSerializer - Cassandra 和 Mysql : 对应
TableSerializer, 然后在各自的驱动模块继承后实现为Cassandra/MysqlSerializer.
比如在源码TableSerializer 写入点Label表的时候, 调用了writeVertexLabel(), 这里往表里写入是否开启LabelIndex的字段
1 | //需要注意的是,Cassandra关闭二级索引可能仍然是生效的...? |
4. Hugegraph的ID为什么怎么实现自动去重? (使用属性组合模式)
因为这种方式ID本身由唯一的属性组合确定, 所以不管是读写顶点还是边, 本身就是唯一的, 也就不需要去查一次了.
5. 利用表自身方式建立的模糊/全文索引,查询的时候是如何使用的?
首先自有分词器. 模糊查询的部分 ,前缀索引依靠DB自身对ID的前缀查询实现, 范围查询限定数字类型, 也是类似道理.
全文查询依赖开源分词器(比如结巴,IKA分词器等), 目前其实已经实现了, 参考issue#258 , issue#294 ,具体的代码后续跟进确认一下.
6. 目前API扩展里提供了一个Shard 和Range的用法 , 应用场景是?
这个想了很一会, 暂时还不太清晰, 以Cassandra为例, 对应的代码是Shard 和 CassandraShard , 目前想有一个可能的应用场景是: 图计算的时候 ,可以方便的从整个图分成的N个Shard去各自取数据执行, 不过这样只能用于全图的计算…
更新: issue#270 提到了一个shard_index 概念, 不知道是否相关…先记一下
7. 创建边的时候不能指定方向, 那么是默认双向边?
例如Person--likes>Person这个关系, 用HG的语法:
schema.edgeLabel("likes").sourceLabel("person").targetLabel("person").ifNotExist().create() 这样可以定义, 那此时A –likes–> B 的时候, 默认B –likes> A 了, 这是不符合许多业务场景的, 而且边表里有direction 这个属性, 那应该是可以指定才对
再确认两个问题:
创建Vertex A – > Vertex A 是否是默认双向?
答: 目前来看, 不是, 并且HG目前没有双向边的说法, 要么就是手动建立两条单向边, 如果是指向自己的边, 那目前的状况就是只能是单向, 你写入两条数据就相当于双向了…不能写1条数据自动双向
创建 Vertex A –> Vertex B 是否默认单向, 如果单向是否还需要单独创建 Vertex B –> Vertex A 且设定同名?
答: 参考上面, 需要. 至于说是否允许同名反向的边, 这个还不确定… 但是可以参考Tigergraph之前的设计觉得挺不错, 使用了
reverse_edge(详见Tigergraph文章)
8. 写入K-V的属性到顶点和边数据表的时候, 是否使用的Json序列化器
如果是, 那读取和更新性能不会挺低么? 需要代码确认见下:
1 | private String formatPropertyValue(HugeProperty<?> prop) { |
更新1: 暂时看Cassandra和Mysql中采用的都是一样采用JSON序列化方式, 但是Hbase/RocksDB不是 , 所以之后需要补充实际的测试数据, 看看在不同的backend 上的读写速度.
更新2: 在Hbase里又不太一样, 顶点的属性是分拆开的, 因为顶点属性可能经常需要单独查询或者更新, 而边的属性是合在一起的, 作者考虑到边属性更新频率比点要少许多, 且很多时候需要全查.
9. HG对一共使用了几个端口, 之间的关联是什么情况?
差不多算三个. 关联情况就是
- GremlinServer(单独端口) –> HugeServer (8080)
- Studio (8088) –> HugeServer (8080)
10. 如果使用了master分支的server, 出现Stuidio连接不上怎么办?
根本原因应该是因为目前的Studio 发送请求依赖的是1.6.4的Client
- 启动Stuidio后 ,先尝试连接一次, 让JVM加载版本检查的class.
- 然后动态修改
VersionUtil.java中的check().注释其内容, 编译重新动态加载新的class文件进去. 重新在前端连接, 就OK了~ 需要注意这个类是在common模块下的. - (可选) 修改
ClientVersion.java,注释其中的check()方法, 这也是common模块下的 (不必要)
参考资料:
- HG-扩展和插件机制
official authors' reply, thanks again