之前已经通过入门系列了解了Hugegraph的全貌和性能测试, 从这里开始源码分析系列, 首先是
Hugegraph-Loader项目的源码分析, 首先对整体结构进行梳理, 然后沿着常用的导入一条线来进行分析, 最后选择其中特别的地方单独学习.5/8月更新: Loader在0.9/1.0版做了大量的重构, 后续单独再开一篇讲这两版的主要变动.
0x00. 整体结构
首先 ,可以看到项目整体的结构分为6个核心模块 , 入口是最下方的HugegraphLoader类 :
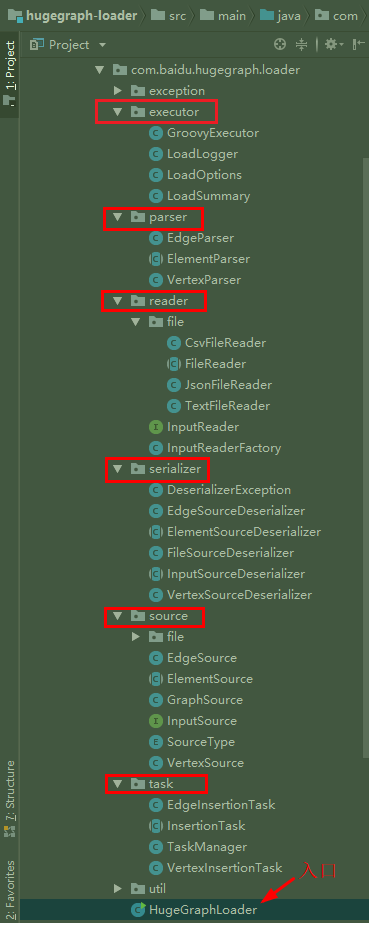
看代码之前, 回顾一下之前使用的步骤, 先估计一下大概的流程 :
- 从HugeGraphLoader启动导入程序
- 通过executor的
LoadOptions解析命令行下输入的各种参数 - 读取两个配置文件
- 通过GroovyExecutor读取
schema.groovy, 然后调用HugeGraphClient的API创建Schema - 通过JsonFileReader读取
mapping.json, 但不确定在哪做的映射(source?)
- 通过GroovyExecutor读取
- 通过reader的不同实现, 读取数据文件 ** ,然后转为source**中的输入?
- 调用task包,开始启动导入任务, 并发的执行第六步
- 启动任务的时候, 开始调用对应的parser 和 executor 的日志/统计
- 如果导入完成, 跳回HugeGraphLoader, 显示汇总信息结束
这里面serializer 和 source 没太想明白, 为什么有图的反序列化? 之后再沿着导入脉络确认是做什么的..
0x01. 导入脉络
整体围绕最开始说的HugeGraphLoader类进行, 那就从这开始看代码, 首先构造方法里初始化了三个final的对象
1 | private HugeGraphLoader(String[] args) { |
然后实现命令行下读取和解析参数主要是依赖的JCommander 这个库 , 通过注解映射对应的参数, 还是比较小巧灵活的 ,使用参考github . 然后就进入核心的load() 了
1 | private void load() { |
可以看到整体是很清晰的5步, 一步步来看.
1. 创建Schema
这里核心是调用的Groovy 的类库去解析Schema
首先初始化了一个HugeClient对象
初始化一个
GroovyExecutor对象, 封装了bind() 和 execute() 两个方法通过bind()方法绑定schema和client.schema() [K-V]
读取
schema.groovy文件转为字符串, 然后把字符串和HugeClient对象传给execute()方法. 这里引用一下代码:1
2
3
4
5
6GroovyShell shell = new GroovyShell(getClass().getClassLoader(),this.binding, config);
// Groovy invoke java through the delegating script.
DelegatingScript script = (DelegatingScript) shell.parse(groovyScript);
script.setDelegate(client);
script.run();
然后内部应该跟开始预测的一样, run()的时候实际就是去调用Client的API了, 那部分之后再看. 第一步创建Schema就结束了
2. 加载顶点
这是之前我们定义映射的文件, 我简单截图以便后续步骤对应: (注意已经支持文件夹读取了, 目前是一个个文件去遍历)
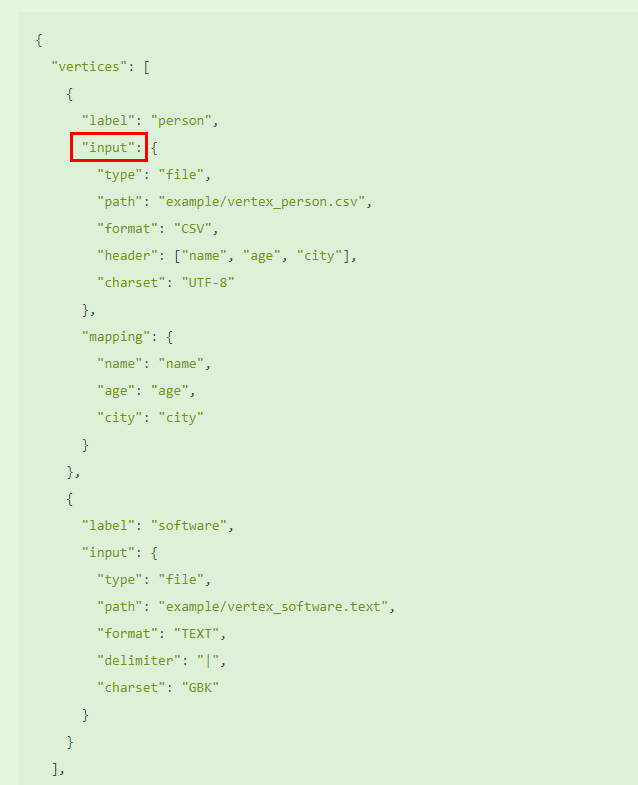
loadVertices() 方法就是导点的汇总, 简要说它有以下步骤:
记录开始时间, 并初始化
VertexSource集合 (这个实际就是映射json里vertices的各种参数值)遍历VertexSource集合, 通过
InputReaderFactory这个解析工厂具体读input(相当于依次遍历上面映射文件里的每个VertexLabel)- 首先是根据
type参数确定是本地文件还是其他(比如HDFS) - 然后初始化一个
VertexParser对象, 此时会同时初始化一个ElementParser,获得了一个特定文件解析对象fileReader - 再把其他的参数传入, 并检查ID策略 (目前只允许主键模式ID/自定义ID)
- 首先是根据
读取设置的
batchSize数值, 然后用它初始化一个Vertex集合 ,然后开始一行行解析顶点数据文件这里主要就是两步, 一读取&过滤K-V , 二解析返回
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17Map<String, Object> keyValues = reader().next();
return parse(filterFields(keyValues)); //Vertex or Edge
//filterFields()这里处理ignoredFields, nullValues.截取处理可空字段
//从处理方式可以看出,映射文件里的可空字段应尽量少写,否则会对全部属性遍历判断一次.
if (!nullableKeys.isEmpty() && !nullValues.isEmpty()) {
Iterator<Map.Entry<String, Object>> itor = keyValues.entrySet()
.iterator();
itor.forEachRemaining(entry -> {
String key = entry.getKey();
Object val = entry.getValue();
if (nullableKeys.contains(key) && nullValues.contains(val)) {
itor.remove();
}
});
}
解析实际调用的
VertexParser,主要两步 :1. 设置ID 2. 附着属性 (这个简单)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30/* 根据不同的ID策略进行校验和设置,主键模式这里麻烦一些(因为可能是联合主键)
* 1.要注意ID长度以字节长判断,而不是字符长,所以中文等编码可能几十个就超了
* 2.联合主键的时候顶点ID设置考虑
*/
id.getBytes().length <= 128
/*设置主键ID核心 (TODO:这里用stream可能有更好的效率和可读性),下面是一些ID转换例子
* 第一列是原始主键值, 第二列是中间处理值, 第三列是最后vertexID值
* 1. jin --> jin! --> 1:jin
* 2. ji:n --> ji`:n! --> 1:ji`:n
* 3. jin + HK --> jin!HK! --> 1:jin!HK (联合主键,比如姓名+城市)
* 备注: 需要注意的是,在边的id解析的时候,`和> 两个字符会作为分隔符标识, 容易有冲突, 需要千万注意
*/
protected String spliceVertexId(VertexLabel vertexLabel, Object[] primaryValues) {
StringBuilder vertexKeysId = new StringBuilder();
String[] searchList = new String[]{":", "!"};
String[] replaceList = new String[]{"`:", "`!"}; //替换前缀加一个`号,这样做看起来似乎有些奇怪
for (Object value : primaryValues) {
String pkValue = String.valueOf(value);
pkValue = StringUtils.replaceEach(pkValue, searchList, replaceList);
vertexKeysId.append(pkValue);
vertexKeysId.append("!"); //联合主键的时候分隔符
}
StringBuilder vertexId = new StringBuilder();
vertexId.append(vertexLabel.id()).append(":").append(vertexKeysId);
vertexId.deleteCharAt(vertexId.length() - 1);
return vertexId.toString();
}然后一条条这样读取, 直到达到设定的提交阈值(默认500) ,触发一次
taskManager.submitVertexBatch()提交, 然后重置
需要注意的是提交的时候是有两种模式的(正常&错误) , 在解析错误的时候, 会转而尝试单条写入(
Semaphore类后续待研究)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32this.ensurePoolAvailable();
this.batchSemaphore.acquire();
InsertionTask<Vertex> task = new VertexInsertionTask(batch, this.options);//batch是传入的List<Vertex>
ListenableFuture<Integer> future = this.batchService.submit(task);
Futures.addCallback(future, new FutureCallback<Integer>() {
//回调call(): --> this.client().graph().addVertices(this.batch());
public void onSuccess(Integer size) {
successNum.add(size); //一次加500 (LongAdder)
batchSemaphore.release();
printProgress("Edges", BATCH_PRINT_FREQUENCY, size);
}
public void onFailure(Throwable t) {
submitVerticesInSingleMode(batch);
batchSemaphore.release();
}
})
//下面是SingleMode的核心.复写call()
this.submitInSingleMode(() -> {
for (Vertex vertex : vertices) {
try {
graph.addVertex(vertex);
successNum.add(1); //单条
} catch (Exception e) {
failureNum.add(1);
LOG_VERTEX_INSERT.error(new InsertException(vertex,e.getMessage()));
}}}}
记录结束时间, 并更新
LoadSummary类中的相关信息. 然后重置计数器.
3. 加载边
边和顶点是一套模式, 大部分相似, 主要不同的地方就在边ID处理这里, 因为边由出入顶点ID组合而成 , 这里需要分别设置, 等于把之前顶点设置ID的步骤再走一次, 但是Loader里并不负责拼接边ID, 这里给一下批量执行的时候, 重试机制:
1 |
|
4. 统计信息 & 结束
统计信息的话是把之前顶点和边中更新过的LoadSummary 对象进行格式化输出, 只是一个汇总不单独说了.
但结束这里还是有些文章的, 比如: 如何更优雅, 更合适的结束. 但时间原因这部分先搁浅一下, 后面有空研究补充.
0x02. 关键点
1. HTTP请求写入
因为Huge的模块拆分比较独立, 所以可以看到HugeLoader里的导入本质是调用的HugeClient模块里的点/边create() 方法. 这里来看看具体实现:
在上面批量导入的时候, 最后调用到了addVertices() 和addEdges() , 二者几乎相同, 先看看添加顶点:
1 | public List<Vertex> addVertices(List<Vertex> vertices) { |
然后相比点, 批量写边主要是create()方法有一个可选的对应点检查(是否存在) , post() 的详细实现等后续看common库再说了.
1 | Map<String, Object> params = ImmutableMap.of("check_vertex", checkVertex); |
2. 反序列化包(*)
上面的导入整体流程中, 我们还是没有看到最初分析包结构的时候出现的serializer包, 看完了导入整体脉络. 再单独看看它的作用和实现吧.
首先Loader里使用的是国外经典的Jackson 序列化框架, 然后至于为什么是反序列化而不是序列化… 一是因为它是在JsonUtil 里被调用的, 本身作用就只是在解析json 数据文件和我们的映射json文件, 二是序列化成Json/GraphSon的工作应该是在server库里实现的 ,那搞清楚了原因和作用, 接着来简单看看如何引入Jackson (可跳)
- 自带的一系列注解, 最常用的
@JsonProperty, 用于把属性名序列化为json对应的名称. - 通过原生提供的树形模型(
tree model) ,通过操作JsonNode来进行读写. - 通过模块注册的方式, 把自定义的类加载进去
1 | public abstract class InputSourceDeserializer<E> extends JsonDeserializer<E> { |
其他也属于Jackson 的细节了, 在这就不深究了.
0x03. 存疑点
因为项目里比较多的使用了Guava和一些外部库, 有些一时可能没时间细看实现原理和源码, 先记录一下, 之后可以慢慢补 (重点是要补Guava)
1. 工具类 & 数据结构 & 并发 & 异步相关 (待查)
1 | /*Guava相关*/ |
2. huge-common 库中关于HTTP发送接收的实现, 比如上面批量写点/边的post() .
待补…
3. 关于任务调度和结束机制
待补…
4.动态刷新实现
这里主要是学习一下\b的用法, 之前没有注意这个转义符还能这么用..
1 | String backward(long word) { |
5. POST请求对应Server端接口
在Server的api模块的com.baidu.hugegraph.api.graph包中, 有VertexAPI, EdgeAPI, 可以看到一个@Path注解为**”batch”**的路径
URL前缀为 : graphs/{graph}/graph/vertices , 下面以edges为例:
1 |
|
TODO:
- 导入开始前完整检测一下映射文件 (目前是挨个检查, 不太友好)
- Loader后续经历了两次大改版, 针对最新一次的改版需要重新分析一下.
后续待补