实际开发中, 当项目模块众多, 依赖复杂的时候, 源码的编译部署依靠人工运维效率显然是很低的, 于是早些年就出现了
DevOps的概念.那么, 接下来就以Hugegraph讲一下如何在实际多模块项目里如何快速的集成CI+CD的环境, 然后内部开发如何单独维护一套版本, 在方便维护的前提下, 尽可能易于跟官方合并, 让社区的用户都能有更好的开发体验~
0x00. 主人公
业界已有的CICD +私有仓库的方案不在少数, 但侧重快速实用, 适用面最广的可能还是之前在Docker+K8s实现CICD系统里提到的Jenkins ,而且我们这次使用的JFrog 的Artifact作为私有包仓库也在对Jenkins 有单独的支持, 后续更易于整合, 关于这次的两个主人公就介绍完了(其他看官方文档), 下面说一下我们这次要实现的主线脉络: (引用两张图)
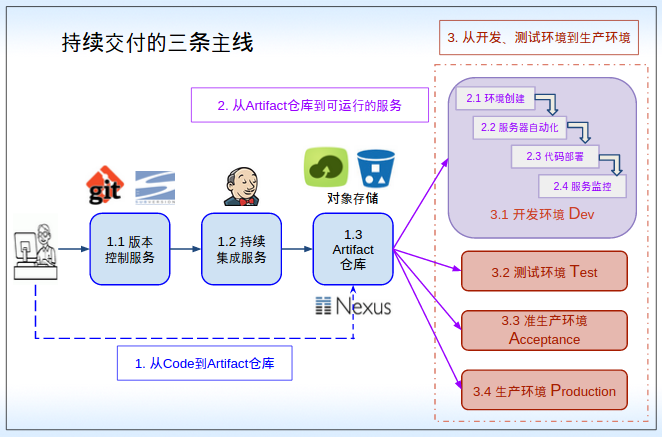
上图就清晰简单的说明了我们要实现的效果, 后续就大致沿着这个脉络去实现. 这里图中右侧的几个环境还不够直观, 那可以看看下面的对照:
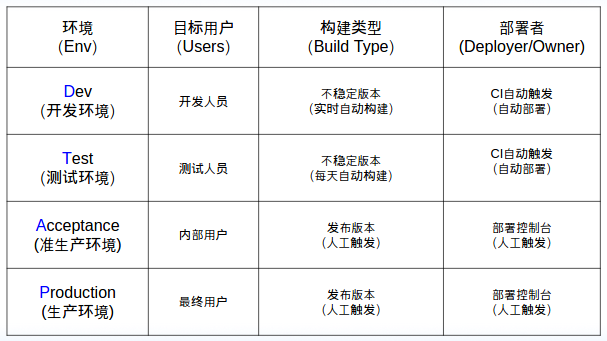
其中测试环境我们这次就和开发合在一起了, 准生产和生产也合并一下, 所以其实就 “开发 + 生产” 两个环境即可. 开始动手. 顺便在后文会着重讲一下”版本管理 + 官方同步“的问题, 也许那些会更刚需一些….
0x01. 实战
关于Jenkins 和 JFrog 的安装启动官方已经封的很简单了, 文档也非常详细, 建议直接参考上面给的官方链接, 由于Docker 单独使用会增加不确定性和运维成本, 所以并不建议上手采用Docker模式运行 (Jenkins建议用RPM包方式安装配置, 利弊自查).现在假设我们已经搭好了”Jfrog+Jenkins”的环境, 重点说说如何使用和整合.
1. JFrog使用
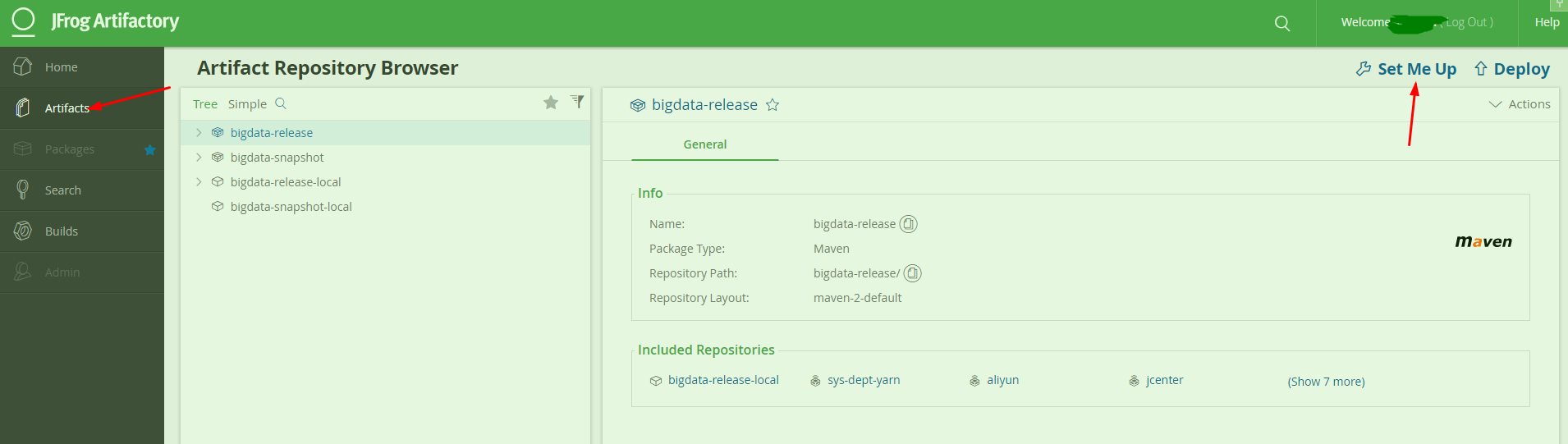
JFrog有非常多的功能, 但我们都不用管:) 直接来看它包管理仓库的使用, 如图我们建立了几个不同的仓库, 开发测试用snapshot , 正式发布用release 区分一下, 然后点Set me Up 可以获取相应的配置参数, 点Deploy 可以手动上传本地包.
首先这里需要搞清楚mvn的几个概念, 你在某个项目的pom.xml 里写了一个项目依赖, mvn做了哪几步事:
- 首先在本地的
~/.m2/repository里去找本地是否有这个包, 如果有就直接使用. - 如果本地没有, 那再读取一个配置文件(
setting.xml)去找远端的仓库地址, 然后再从远端仓库里去找. (默认的仓库地址应该是通过的, 下载速度比较慢) - 如果你配置了一个本地的mvn仓库地址, 比如(Nexus或JFog的). 那有两种方式让项目读取本地仓库包:
- 一是修改maven上面全局的配置文件, 让所有项目都先去从你本地mvn仓库找. (推荐)
- 二是在当前项目的
pom.xml里通过配置<repositories>项, 手动指定本项目使用的仓库地址.
综上大部分时候我们肯定是采用修改全局配置的方式, 这样引入依赖和发布包都方便许多, 也不需要到处改pom.xml 文件, 那这里需要注意的是, 在win上, 你可能发现并没有看到~/.m2/settings.xml 这个文件存在, 主要可能是因为你IDEA使用的是自带的maven ,并且没有勾上Override User setting file 选项, 当然得清楚, 本质上这个文件是从你maven的安装目录比如maven3.x/conf/settings.xml 来的, 所以直接修改它是一样可以的, 文件里有一大堆注释, 我们先重点关注servers就行.
然后 , 需要注意的是Jfrog 里的仓库也有几个分类:
- Local-repo : 本地仓库, 内部使用, 仓库内容不会向外部同步
- Remote-repo : 远程仓库, 最常用. 不能往里面上传私有组件. (但是可以通过包含本地仓库, 达到一个复用关系)
- Virtual-repo : 虚拟仓库, 它管理本地和远程库.
然后简单点, 从JFrog 界面点了Set Me Up 之后, 再点击Generate Maven Settings –> Generate Settings 就能看到可以直接覆盖默认settings.xml的文件了, 例如:
1 |
|
然后配置好之后, 理论上你就可以试试在项目里直接引入一个上传的测试jar包, 看看是否IDEA能自动解析导入了. (如果不能注意观察自动导包的URL是否正确, 然后建议重启一下IDEA, 避免大量缓存出现一些问题)
补充: IDEA测试的时候发现有些包明明已经导入成功了, 调用也没问题, 也没有本地/项目依赖冲突或者版本冲突, 但是就是提示红线(而且SNAPSHOT版就正常)…具体原因还不确定, 但是不影响使用. 如果发现根本原因我再来更新.
4.20更新: 如果SNAPSHOT包更新了, 没有自动发现, 最快的办法就是先把带日期的全路径复制到pom文件中, 等加载好再换回.
2. 部署
除了导入包, 还有个重要的功能就是部署包到Artifactory上, 那么这里需要在项目的pom.xml单独设置一下, 同样在Set Me Up 的默认页面就有相关配置参数, 比如:
1 | <distributionManagement> |
最后在命令中执行mvn package deploy -DskipTests ,表示先打包, 然后上传到仓库, 并跳过测试. (生产环境严禁跳过测试), SNAPSHOT 是平常常用的测试版本, 需要修改项目pom中的:
1 | <!--如果正式版本是0.9.0--> |
这里要注意, 如果没有配置好maven的settings文件, 上传会提示401无权限访问. 每个需要上传包的项目都可以这样写达到同样效果, 后面在[maven模块优化](#0x02. Maven优化) 的顶层pom 里只需要写一个, 其他模块就能都复用了. (而不需要每个模块复制配置…)
2. Jenkins使用
进入Jenkin控制面板后, 首先关闭一下确定用不到的插件, 然后根据下面的两个选择, 安装各自所需核心插件比如Blueocean 或Artifactory 插件,
然后你有两个选择:
- 使用旧的
Jenkins-pipeline-stage方式, UI不好看, 但是易于和插件结合, 并且参考资料多不少. (pipeline1.0 ,不需要Jenkinsfile) - 采用新的”BlueOcean + Jenkinsfile”模式, 可视化操作, UI直观简洁, 复用很方便, 是以后Pipeline模式的代表. (pipeline2.0,
Jenkinsfile有一定学习成本)
为了方便大家复用, 我这里优先选择Blueocean + Jenkinsfile的方式, 大家之后参考做法, 就像复用Dockerfile一样可以自己很快构建, 而无需研究Jenkins的使用..
待补充Jenkinsfile文件…
1 |
3. 二者整合
整合参考官方文档, 这里有些小坑, 等我跑顺再写吧…
待补充…
0x02. Maven优化
1. 核心
因为Huge官方的模块很多, 但是内部维护单独的版本和依赖打包会很不方便, 所以这里选择把Huge的模块归总到一个项目里, 然后用子模块的方式去管理, 并且希望修改顶层版本号的时候, 其他子模块能自动变更版本. 保持统一: (官方版本单独fork不冲突)
1 | #假设我们的目录结构是这样的 |
然后我们遵循以下几个步骤, 来一步步完善我们的**”父-子”** 模块管理, 对整个配置和原理也就更加清晰:
首先, 在顶层(root)的
pom.xml里添加version管理插件, 添加子模块, 并创建对应子模块(IDEA可一键创建)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25<groupId>num</groupId>
<artifactId>jin</artifactId>
<!--下面这行申明是一定需要的,好比告诉maven我是root-->
<packaging>pom</packaging>
<version>1.0</version>
<modules>
<module>module1</module>
<module>module2</module>
</modules>
<build>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>versions-maven-plugin</artifactId>
<version>2.7</version>
<configuration>
<!--默认会自动生成一个旧版的备份文件,熟悉后可去,但就无法回滚了 -->
<generateBackupPoms>true</generateBackupPoms>
</configuration>
</plugin>
</plugins>
</build>然后在每个子模块的
pom.xml中引入父模块声明, 这样就把父子模块关联了起来 (module2同理, IDEA完成后右侧有继承标志)1
2
3
4
5
6
7
8
9
10
11<parent>
<groupId>num</groupId>
<artifactId>jin</artifactId>
<version>1.0</version>
</parent>
<groupId>num</groupId>
<artifactId>module1</artifactId>
<!--↓如非必要↓, 子模块不单独设置自己的版本号,默认打包的时候会使用父模块的版本
<version>1.0</version>
-->在顶层pom中大量使用版本变量, 使子模块高效复用 (然后子模块引用依赖的时候无需写版本, 只用写
groupId+artifactId)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32<properties>
<!--所有依赖的外部jar包版本号统一设置在此-->
<guava.version>27.0</guava.version>
<!--当然,还可以设置一些全局属性-->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
</properties>
<!--这里分两种场景:一是子模块间内部相互引用, 二是引用外部包-->
<dependencyManagement>
<dependencies>
<!--项目内的模块,版本号全部使用${project.version}指定,无需单独定义,直接取parent的version-->
<dependency>
<groupId>num</groupId>
<artifactId>module1</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>num</groupId>
<artifactId>module2</artifactId>
<version>${project.version}</version>
</dependency>
<!--外部模块,版本号全部使用占位符指定(需要单独声明)-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava.version}</version>
</dependency>
</dependencies>
</dependencyManagement>在顶层pom引入本地的Maven仓库配置, 这样子模块就不需要重复填写了
1
2
3
4
5
6
7
8
9
10
11
12
13<!--给的是Artifactory的配置, Nexus也是类似的-->
<distributionManagement>
<repository>
<id>central</id>
<name>serverIP-releases</name>
<url>http://serverIP:8081/artifactory/repo-release-local</url>
</repository>
<snapshotRepository>
<id>snapshots</id>
<name>serverIP-snapshots</name>
<url>http://serverIP:8081/artifactory/repo-snapshot-local</url>
</snapshotRepository>
</distributionManagement>最后执行一键修改版本的命令(许多参数默认值都不用改, 不过注意有些情况下子模块自己的版本不会被修改, 此时建议去掉.)
1
2# 设置新的版本号未1.2.0-SNAPSHOT (其他详细参考可参考官网,一般不需要单独修改)
mvn versions:set -DnewVersion=1.1尝试打包一下, 看看有没有报错
1
mvn clean install -DskipTests
2. 补充
a. 单个模块继承多个parent(重要)
当然, 实际使用里可能遇到一些比较麻烦的问题, 比如一个module 同时继承了两个parent ,但是pom里是不支持多继承的, 那怎么办呢? 参考Spring-boot官方. 比如Huge里原本继承了一个oss-parent ,那我们可以删掉原本的parent, 然后在最顶层pom里加入如下: (version对应映射单独配置.)
1 | <dependency> |
当然, 还有一种可能的解决方案是在顶层的pom里把子类依赖的parent 搬过来, 但是这样做就算可以, 最多只能共用一个parent, 所以就不推荐使用了. (可行性?)
b. 优化.gitignore文件
首先建议去github上找一个大家使用的多的模板, 然后在定制化修改一下, 比如把pom.xml.versionsBackup 也加进去.
0x03. 与官方库同步
这是很关键的一步, 并且有一些坑, 不注意会很容易出错, 我们单独构建了一套管理方案之后, 很多时候还需要从官方版本上cherry-pick 一些改动 , 但是此时你会发现因为项目结构不一样, 你并不能直接这样做了. 但是还有个方案, 就是让官方的目录结构跟我们一样, 然后单独创建一个新的分支 (比如github) , 再去合并.
首先, 根目录下不需要历史记录, 也不需要任何文件, 使用--orphan 参数代表无任何提交记录.
1 | # 1.创建新的空记录分支 |
然后记得在根目录下放置一个.gitignore 文件, 然后0x02的根目录的pom.xml 来作为父管理几个子模块. 下面我以自己的尝试过程为例, 告诉大家这里存在哪些可能的坑, 当然也可以直接跳到[正确的做法](#2. 正确的做法)
1. 错误的做法 (可跳)
1 | # 1.尝试第一次提交 |
然后这时候你随便一搜“git checkout 无法切换”之类的 ,强制切换(-f)或者全部丢弃之类的, 就会发现文件都丢了, 而且就算全部丢弃, 下次这个github分支有任何的新拉取, 再切换还是一样的提示. 所以还是把根本原因搞清楚 ,再操作. 那先看看图 —– untracked files 是什么 :
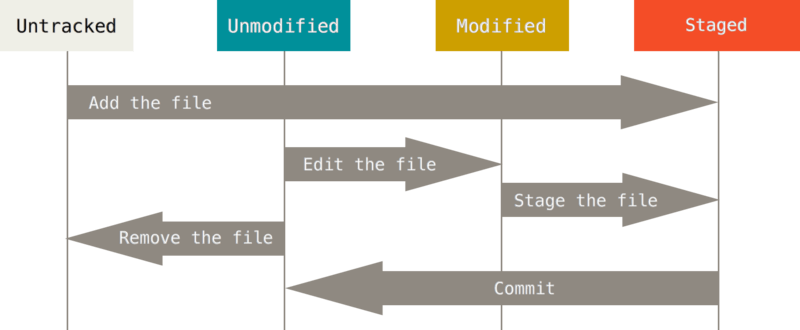
从图里你可以发现, 目录下所有文件只有两种状态:
- 未被标记 : 不存在历史记录中, 也没存入本地暂存区, 简单说就是还没纳入git管理.
- 已被标记 : 存在历史记录或本地暂存区中, 文件之后所有的变动都会被git跟踪检查到(
tracked)
1 | # 很简单的举例,在git目录下新建一个文件 |
这样可能就比较好理解了, 我们切换分支的时候, 还有一些文件根本没被git成功”纳入”. 此时切换分支, 这些文件要么丢弃, 要么被覆盖了, 但这显然不是我们的初衷, 我们是希望这些文件都保留下来. 但是这里诡异的是, 我们是新分支, 而且使用git status 查看也都提示nothing to commit, working directory clean, 并没有显示有未跟踪文件呢. 别急, 一步步来排查
使用
git status --ignored排除是不是被放入忽略文件了. (√)手动添加提示没被跟踪的文件, 发现问题
1
2
3git add hugegraph/.gitignore
# 提示hugegraph是一个子模块
fatal: Pathspec 'hugegraph/.gitignore' is in submodule 'hugegraph'
这里又涉及到另一个git子模块管理的概念, 当然这个并非我们想要的, 那为什么模块们都自己变成submodule 了呢? 这要回到最开始我们添加这些文件的时候的git add . 命令, 这个命令平常随便用没问题, 在这个嵌套.git文件夹的时候, 就非常蛋疼了, 它会自动把.git的子目录当为子模块, 从而自动忽视所有子模块的内容, 只是把一个空的文件夹添加到了git仓库中, 让我们误以为成功了…. 而且这个是强制自动执行的, 那么如何解决呢, 大致3个思路,
2. 正确的做法 (手动)
先来看看三种常见方案, 我们选择最合适简单的一种:
使用
git submodule子模块管理 (不合适, 我们这只是单纯组织管理下文件, 引入不必要的复杂度.)删除所有模块的
.git文件夹 (不合适, 这适用于0x02, 但这里我们要经常和官方同步, 并不能删掉.)在根目录的
.gitignore中添加.git忽略 (符合, 来试试)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# 0.添加忽略.git文件夹,请先把.gitignore,shell之类的放入
echo ".git" >> .gitignore
# 1.1 先尝试添加一个模块 (失败, 错误做法X)
git add hugegraph #糟糕, 仍然提示添加子模块, 实际又只加了个文件夹.为什么.gitignore没有生效呢?
# 1.2 尝试单独添加里面的一个文件 (成功, 正确做法√)
git add hugegraph/.gitignore
# 1.3 那会不会是git add的检测机制的问题呢? 尝试用 hugegraph/ ,直接使用 hugegraph会被当成一个整体添加. 而不是单纯的文件夹
git add hugegraph/ # 大功告成! 再git status看一下发现文件都加了进去, 并且没有.git文件夹. 符合我们的需要
# 1.批量一次性添加,测试用通配符'*'似乎不OK(也不能写成一条add命令,原因暂时未知..)
git add hugegraph/ && git add hugegraph-client/ && git add hugegraph-common/ && \
git add hugegraph-loader/ && git add hugegraph-tools/ && git add hugegraph-studio/ && \
git add .
# 2. 提交为初次记录
git commit -m "init from official github on 19.06.21"
# 补充:如果添加studio的时候提示有CRLF存在...批量转换一下. (Win下常见..)
dos2unix hugegraph-studio/studio-ui/assets/vendors/bootstrap-select/css/bootstrap-select.min.css
你再切换到其他分支就会发现丝滑顺畅了~ 之后需要和官方哪个模块进行同步合并, 就切换到github分支, 然后进目录里单独git pull 一下就行. 当然合并操作推荐使用IDEA 自带的强大对比功能, 而不是手动的复制粘贴. (不过这里都是手动操作, 很笨拙, 下面给一个自动化的方式. 且可以避免一些问题)
3. 与社区保持同步 (自动)
上面的操作做完之后, 可以手动对单个模块进行更新和同步, 但是模块多了就很繁琐, 并且这里还有个比较麻烦的事, 就是实测IDEA(2018)对带有.git文件夹的模块进行查看的时候会提示Bad version xxx, 因为此时相当于存在两个 git 版本控制重叠, 重命名或去掉.git 文件后, 对比合并其他分支才能正常
但是这样每次更新都得手动把.git 文件夹名改一下, 然后首次提交还需要把git_bak上传, 我写了个脚本自动做, 但还是比较麻烦…(git子模块不知道会不会更优雅).
暂时先简单写了个自动化脚本 sh update.sh, 如果有改进或其他的思路, 欢迎及时告知. (脚本放整合的根目录下, 也就是顶层 pom.xml)
- 确认子模块是否包含
.git文件夹, 如果没有则确认含有git_bak文件夹, 并将其重命名为.git(都无直接退出) - 遍历每个模块, 从社区拉取最新代码尝试自动合并
- 完成后将
.git重命名为git_bak然后自动提交
1 |
|
执行完后, 就可以看到自动更新完毕代码和提交记录了(有冲突则需要手动处理)…. 整个过程是有点艰辛, 但是大家在此基础上改进, 应该会好不少..
补充: 这里拉取代码的时候选择的是官方库, 如果你想给官方提交PR贡献, 那么开始拉取的时候应该选择你自己Fork 之后的链接为好, 但是这同样比较蛋疼. 所以暂时推荐单独维护一个版本和社区同步, 而不是混用.
0x04. 总结 & 反思
总结:
- CI/CD核心是流水线, 以及自动化的脚本, 并非工具本身
- Docker化后可以将编译和打包和测试整合, 强烈推荐使用 (TODO)
- 内部维护建议单独一个项目(project)整合, 定期与社区同步
- 父子模块的
maven使用要注意规范, 版本管理建议统一, 多复用 git的管理和使用要千万注意, 它不出问题还好, 一出问题可能异常棘手- 大版本的
git社区合并要更加注意, 使用脚本也需谨慎一些, 分拆模块合并比一起merge好得多
待Docker完成再补….
反思:
- 还记得Linus邮件常
说的Read the fuxking manual(RTFM). 但是很多时候我还是不经意的忽略了一些Unix返回的**警告(Warning)**信息, 这次这个git add .导致的问题本来也有输出信息, 但是被一带而过的忽视了, 才导致这个问题变复杂了许多. - 遇到不熟悉领域的问题, 还是小心参考网上很多教程, 啪啪啪几下命令下去, 可能你上了天堂, 也可能下了地狱. 耐心一点分析一下背后的原理, 搞清楚这步到底是在做什么, 我的问题是不是需要这样, 很多时候也许你的问题跟别人说的并非一回事. 错误的依葫芦画瓢, 最后可能导致你的问题变得不可弥补…
- 严谨一点, 再严谨一点….
add dir和add dir/在有些时候, 就有很大的区别…. 切勿惯性拍脑袋, 强迫自己做事一步步尝试, 而不要一下就觉得对或不对