“坚持性能分析——不要用你的眼睛去优化性能 “
PS : 文章会持续更新, 算是个人笔记了.. 之前的JVM性能监控分析参考此.
0x00. 前言
首先说明一下, Unix家族的前辈们做的贡献太多, 实力太强, 以至于大多数情况还远不到普通人谈调优它的问题… 所以准确说这里应该是学会使用Linux各种已有的强大的性能分析/监控/调优工具, 顺便了解一下他们的原理.
大致的路线是:
- 性能监控
- 性能分析
- 性能调优
使用频率& 难度自然也是依次增加的, 所以这篇文章也会逐步的填坑, 并且尽可能的参考已有的好文章/开源项目 ,而不是以个人经验为主, 同时尽量给出有体系的参考系列, 而不是各种零散的命令使用:
- (核心)性能优化大牛Brendan D. Gregg的性能优化页. 火焰图等也是这个前辈写的的… 并且他的性能优化分享做的非常多, 还包括容器性能分析/高内核4.1/4.9+分析等.), 这里简单列几个觉得写得挺好的分享, 如果大家有Linux基础, 请优先看前辈的相关Share, 不知道比我写的高哪去了..
- How to Profile on Linux-PDF -2015年
- Linux Perfermance-PDF - 常见性能分析命令介绍
- Linux基础的监控/命令合集 (基础的性能监控分析)
- zhihu-在Linux下做性能优化-系列(12篇) (进阶的性能分析优化, 需要kernel基础)
PS: Brendan前辈画的几张总结图都很全. 也非常经典, 我就不再单独搬运了. 大家想系统的了解, 优先推荐参考上面的三个系列
0x01. 性能监控
这里说的监控也包括基本的信息查询, 比如查询CPU/磁盘/内存的详细参数, 很多高性能硬件普通的查法是不能识别区分的. (基于CentOS7 )
更新: 推荐优先看看Netflix的这篇最常用监控小节, 原文地址
1. CPU
A. 硬件信息
先说一下, 我们一般说CPU核心, 其中核(core)和处理器(processor) 是两个概念, 说核心一般是说的物理核 ,比如某至强E5的CPU是24核心48线程, 这里线程是指的Intel/AMD的超线程技术, 为了和物理核区分, 也可以称它为逻辑核, 在OS的角度来看(比如top)等, 看到的处理器的数目, 也就是逻辑核.
除了知道超线程的适用场景外, 还要特别注意几点:
- 超线程一般在适合的场景(非计算密集)下, 能提升25%以内的单核性能, 如果大家要估算CPU性能对比, 建议以
CPU物理核数* 125%来算, 而不是直接比较通常是两倍的逻辑核数, 误差很大. - 并不是所有服务器的CPU都开了超线程, 也不是至强系列就一定开, E3的服务器也有好一些.. 估计CPU性能切不可直接暴力比较逻辑核数目.
- CPU的制程(22/14/10/7nm), 默认主频, 三级缓存的大小, 实际频率都需要考虑, 虽然这几年牙膏挤得过分, 但是基本的
Tick-tock一般也有**8%~22%**的综合性能提升, 不是说E5系列从12年款和19年款都是差不多性能的… 如果不清楚当前型号CPU具体性能, 建议查阅官方/跑分对比.
1 | # 查看CPU基本的参数 |
B. 实时信息
这主要是说从OS角度常看的CPU实时状态/历史负载等, 最常见的组合是top + ps , 说它之后也说一下稍微有趣一些的它的衍生.
top命令注意观察CPU0负载, 通常多处理器很可能是依赖
CPU0来进行调度的1
2
3
4
5
6
7
8
9
10
11
12
13
14# top命令是最常用的, 但是有几个必备快捷键是需要知道的
top # 进入交互后,不需要输'-'
-M 按内存使用排序
-P 按CPU使用排序
-c 展开进程的详细信息(比如python执行地址,参数)
-V 树形展示进程间的关系(类似tree)
-u 输入用户名, 然后只显示当前用户
-k 输入pid,等于kill pid
-1 数字1,显示所有逻辑核心的工作情况
# top单独查看某个进程的所有线程,'-'可省
top -Hp pid
# 其他top命令觉得都不需要记, 要用的时候再man吧top家族 (
htop推荐繁多进程的服务机使用. 可以输出启动进程命令, 自用简单可推荐gotop,)1
2
3
4
5
6
7
8
9
10
11# htop直接安装即可
yum intall -y htop
# 不用按官方的做法下载, 也无需go环境,直接下源包, 然后解压就行, 注意确认是否最新版.
wget https://github.com/cjbassi/gotop/releases/download/3.0.0/gotop_3.0.0_linux_amd64.tgz
# 解压得到干净的gotop,go这个特性真的是很不错
mv gotop /bin/ # 当然你自己找个可执行的地方都行
# 常用监控命令
gotop -spa #显示最全的信息
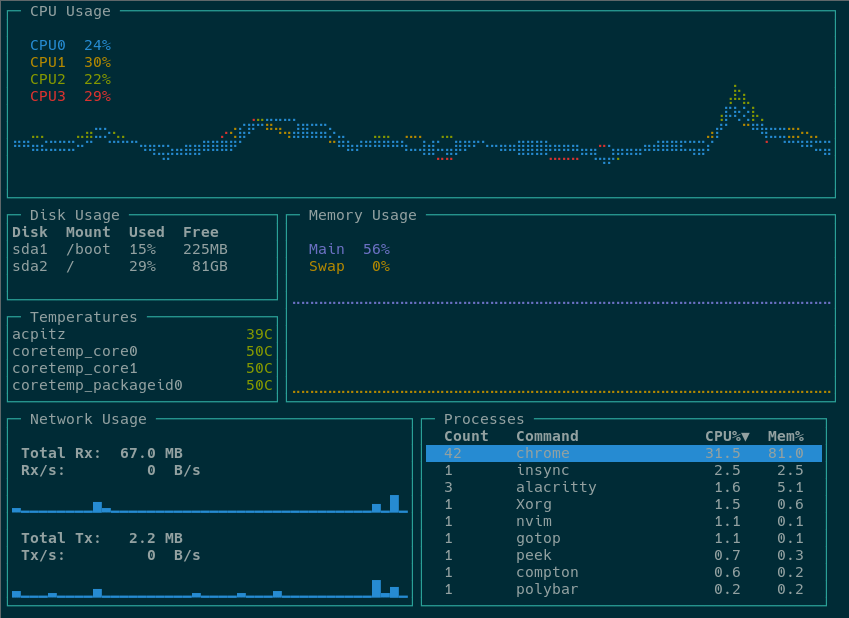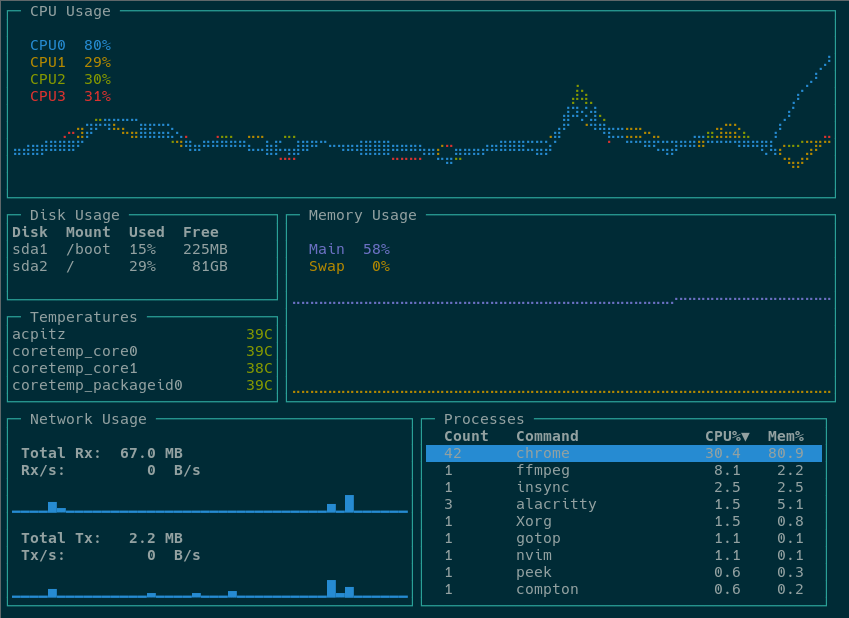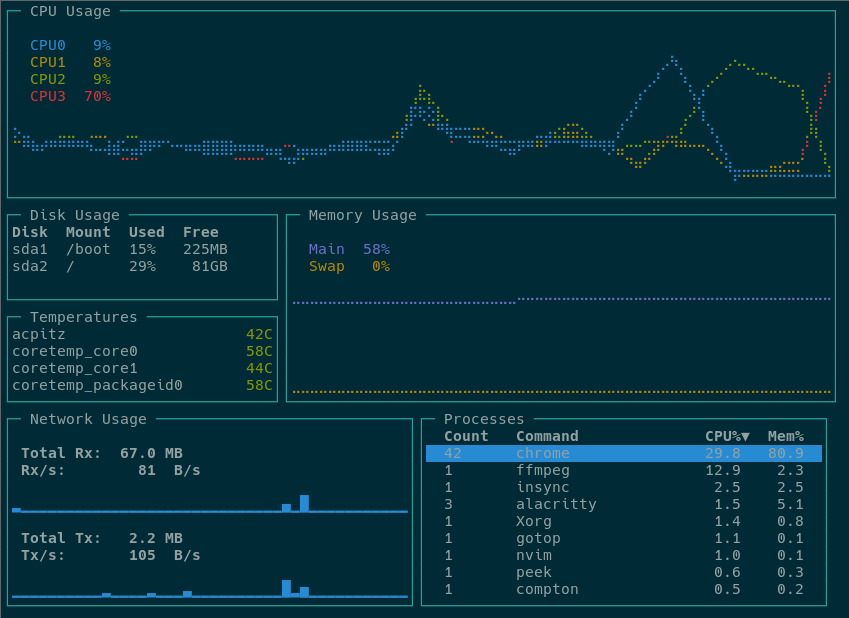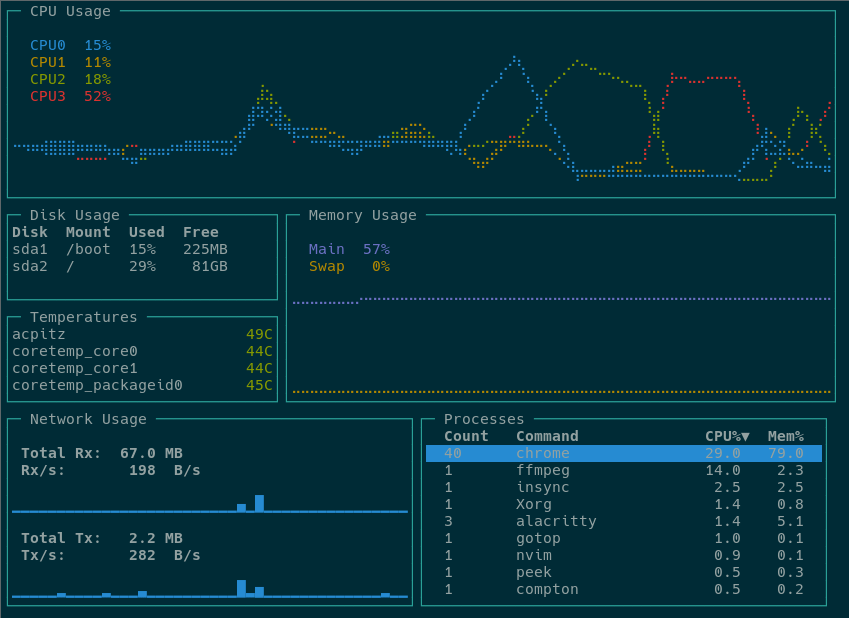
它差不多是整合了最基本的Linux监控, 包括磁盘/网络/CPU/内存等, 但是信息肯定远没有单独的Linux命令好, 这里提到它主要是两个原因:
- Linux上很难找到一个类面板综合了各种常见监控指标的软件, 如果我要看一台节点的几个指标, 通常要开多个bash, 略蛋疼… 不知道有什么好的综合监控软件可以推荐么?
- 为你自己的个人Linux主机添一些色彩, 不至于那么枯燥, 比起其他花哨的Linux软件来说,
gotop还算很轻量级的了.
一般而言, 平常用top + ps的组合也挺够用高效了, 做事的时候也不会用到htop/gotop 这种花哨的界面~ 只是个小插曲哈哈. (就像画家偶尔也会去丛林发现灵感~)
2. 内存
同样, 写说下最基本的两方面查询, 一般详细评估的时候, 建议考察至少以下参数:
- 内存频率 (1333/ 1666/ 2133 /2400 /3000等)
- 内存版本(ddr3/ddr4 差别也挺大)
- 内存条数, 几通道 (比如180G内存, 是多少根多大的组成的? )
1. 硬件信息
1 | # dmidecode 命令是基于BIOS特定规范下记录硬件信息的工具 |
2. 实时信息
1 | # free 命令基本信息也要看明白一些.. |
一般available ≈ free + buff/cache , 当然也可以说 ≤ ,这里关键在于理解buff/cache 这栏, shared 是一些共享库占用, 多不会很大, 首先内存当磁盘缓存是很好理解的, Windows上也有这样的做法, 甚至你还可以建一个内存盘 ~ 本质都是空间换时间 + 更多的复用
- buffer : 主要用于写磁盘的缓冲
- cache : 主要是为读磁盘的缓存
当然要注意, 一般Buffer多用于写Cache多用于读, 但是当然也可以有写缓存, 读缓冲.
一般在存储计算/高性能服务器上, 都是关闭交换内存的, 因为本质就是用磁盘当内存. 也就跟缓存相反, 是时间换空间的代表…会引起性能骤降. 所以这里不讲如何设置交换内存了.. swapoff -a 可临时关闭, 永久关改写文件即可(自查).
3.网络
最常见的ifconfig / ip a 这种命令, 就不单独说了, 想查看当前的网络流量情况, 可以通过ifstat 来查看. 强大的分析参考后面的iftop
简单的网络监控推荐使用 sar:
1 | # 5s/次输出所有网卡的流量进出 |
其他的仍然推荐看前辈的Share, 比我考虑的周全的多.
4.磁盘IO
这部分写的多了一些, 单独拆分了 —-> 详见磁盘对比和性能分析,
0x02. 性能分析
注意: 我这里写的性能分析都很基础, 日用可能够了, 但是进阶肯定推荐看看文首Brendan前辈的各种详尽性能分析专题, 我这仅仅是抛砖一枚.
CPU层面:
- sar : 查看历史性能最常用命令, Linux上如何查看CPU过去一段时间的平均负载?
- pstack: 跟踪进程的栈细节, 常用来分析假死的进程, 过于繁忙的进程在忙什么? (但需要对linux更为熟悉.)
内存层面:
- vmstat : 显示详细的内存/ page / block-IO / 中断等信息.
- dmesg : 这里常见可以看到因为OOM被OS给杀掉的进程, 以及一些内存硬件报错的问题, 虽然很少见, 但是出现就很严重了.
磁盘IO层面:
- lsof : 一切皆文件的哲学下, lsof命令作用非常强大
网络层面:
在现在普遍万兆网的前提下, 网络的分析一般不会太频繁(因为相对CPU/内存/磁盘, 网络带宽很难达到瓶颈). 但是有时候遇到一些网络问题, 没有好的分析工具, 还是会非常头疼的, 这里介绍一些神器. 比如iftop 或者是自带的iptraf-ng (也可能是iptraf)
1 | sudo yum intall -y iftop #非自带软件 |
除此之外, 还有一些更细节的网络包分析, 那最常见的就是使用tcpdump 了.
- tcpdump : 用来抓取从链路层到顶层详细的网络包, 一般可以导出文件, 给wireshark去进一步的直观查看.
补充: 然后网络这有非常多强大的分析扫描工具, 包括nmap ,nc/ncat, dig 等, 因为偏安全方向, 且很细化, 这里不单独说, 需要的时候会单独写一下.
0x03. 性能调优
在调优之前, 有个很关键的概念是如何定义高性能, 参考coolshell前辈的文章觉得有两个比较核心的点, 综合分析比较有参考价值:
- Throughput(吞吐量) : 简单说可以理解为并发数, 某个服务1秒能接受的请求数.
- Latency(延迟): 简单可以理解为处理每个请求的时间.
简单的例子, 比如每秒1000个请求, 每个请求平均相应10ms. 和每秒10万个请求, 每个相应500ms, 也许实际在客户端看到的实际速度可能前者反而更快, 所以不能只以QPS/吞吐来判断性能快慢, 当然, 在延时相差不大的情况, 一般吞吐越大自然是越好的. (极低的吞吐肯定是不太正常的)
然后其它各个方面的内容, 上面coolshell 前辈文章里写的挺好了, 虽然写的时间比较早, 但是大部分都是通用的, 建议仔细阅读. 后续我遇到了具体的情况再来具体写.
至于性能调优的工具, 其实和分析也有些重合, 这里先列一下:
- perf : 推荐优先使用它的可视化版火焰图. 并注意特定的进程可能有专门的火焰图工具.
- strace : 查看系统调用.
- …..
这里还没有提任何Linux事件, 内核级别的监听/ 动态追踪技术等…… (DTrace/ftrace等) ,包括特定语言的调试比如gdb
8.14更新: 拆分磁盘IO部分至磁盘对比和性能分析.
未完待续….
补充: Postman使用 (后续拆分)
普通把它当请求测试工具大家都清楚, 不过过了这么久发展, pman还有几个很强大的功能: 比如自动化测试和mock的功能, 我还没用过.
有个pman使用系列写的不错, 之后待学习使用, 现在把pman用的是有点太low了, 就纯粹成了个发重复请求的工具, 毫无自动化可言… 有点惭愧~
参考资料:
- Linux下60s的性能分析(入门)
- Linux基本性能监控
- Linux进阶之性能调优
- Linux下IO监控分析
- Linux性能汇总图2017
- 原文已引用的部分. 特别致敬Brendan D. Gregg