因为k8本身以及相关的新组件用到的开源框架新语言新技术新理念很多,所以不可避免的踩坑也非常多,需要专门写个系列来记录错误和解决方案了。 慢慢会把其他的文章排查也在这汇总. 每个版面放5类,当前没有找到可以查看下一篇.
0x00.k8安装错误
1.如果node加入的时候hostname重复导致的master无法识别
情景: 很容易遇到,特别是用虚拟机模板创建的node们,很容易就忘记修改hostname了,导致两个主机名都叫nodeX 的主机同时join到master,master自然不能直接识别两个名字一样的node(要求唯一). 所以需要删掉重新加入.
解决方案1: 先在master删掉重复的node, kubelet delete node nodeX , 然后分别修改新的node名正常hostnamectl set-hostname nodeX , 然后删掉以下两个认证文件(第一次join后就生成了) 然后重启一次. (当然你如果熟悉也可以结束端口占用,但是我是不确定的目前)
1 | #以下是报错信息. 删掉 crt 和 conf 文件,然后重启即可 |
重启完后重新用join命令加入master即可.检查是否成功一看node有没有报错,二看master的 kubelet get node .
解决方案2: (推荐node上测试,master不推荐…但是实在没救的时候可以试试)
1 | $ kubeadm reset #这是node上的 |
2.kubelet的cgroup跟driver的cgroup 不同
说实话,这个还是应该匹配一下,因为docker17.x之后换成了cgroups . 一般用的1.12版本是systemd. 所以就需要去修改k8s的启动. 但是有时候这个改动不会生效,就会报错. 使用任何kubelet的命令都会报错.但是dashboard还是可以正常显示. 如图
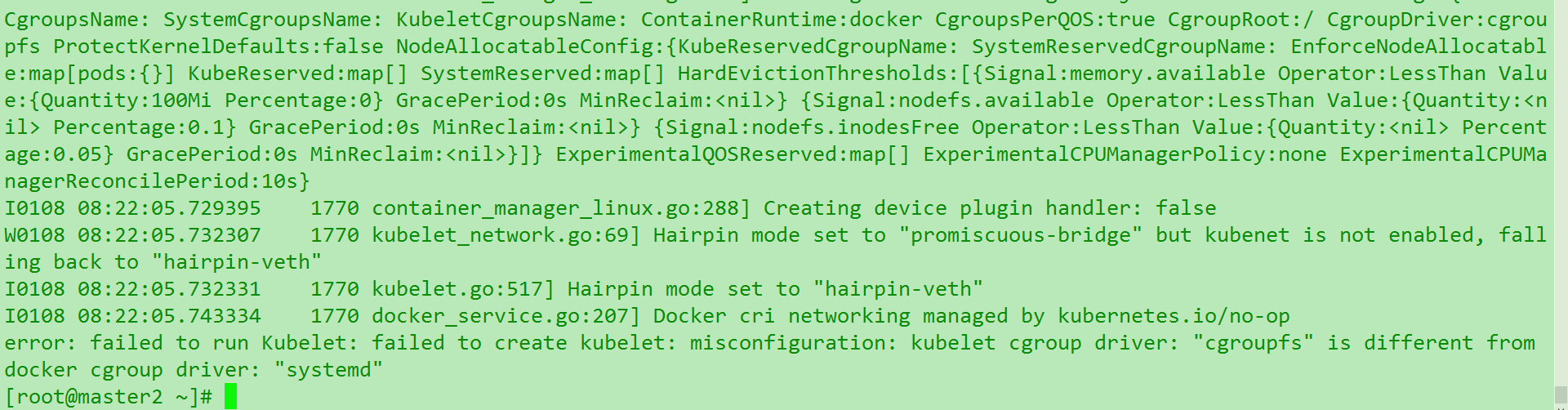
参考官方文档 .但是坑的是官方修改cgroups这404了. 然后下面的也校验了
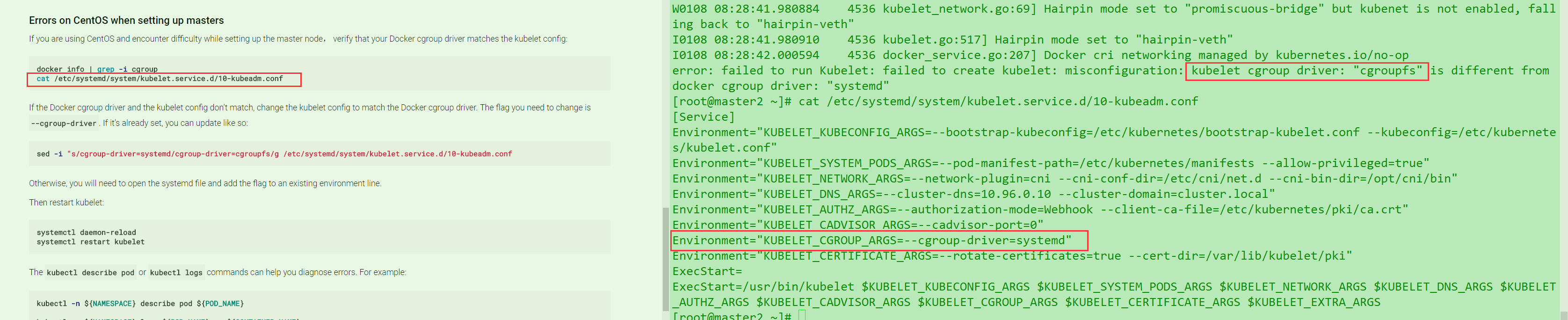
最后发现根本原因是因为只要你输入 kubelet 回车相关的命令. 会直接绕开启动参数原生的调用…..所以不管怎么样你都会报这个错,除非你改的是docker的cgroup,但是这样更不建议….. 天坑… 千万注意别搞错了…
3.k8的集群整体更换ip的问题. (最好不要换..)
这要分两个来说. 一是master的ip,二是node的ip. 显然,master的ip更换要麻烦的多,特别是基于kubeadm安装的话.因为中间是自动化操作的. 很可能就要reset 了. node的应该比较好说,毕竟只是一个工作载体. 更换ip之前先从master上delete node ,然后重新kubeadm join 加入新的master即可.
重点说一下master更换ip的事:

各方查阅(官网/群/issue/blog).皆无果,唯一参考有点价值的如上. 但是etcd并没有外置…所以等于白说.
只能先尝试kubeadm reset .发现还是不行,说明这个ip绑定已经很深了. 由于底层配置原理不清楚,所以也不好乱改,只得重装. 但是我们还是先尝试重新init-master一下. 注意之前脚本里面不需要重新走的. 比如解压/安装docker之类的注释掉. 不然很浪费时间.

果不其然.重新构建还是可以重新把10的新ip替换. 并且各项服务启动正常. 然后加载dashboard
然后我们试试node加入.直接join当然是会报错的.因为node之前加入了已有master,很多东西是占用了的.也要先reset. 然后试试加入. 很快成功了.但是… dashboard一看.不太对! 哎,看来node也要重新init一次.

然而蛋疼的是,重新init还是会出现一样的情况. 因为这个初始化并不是那种重新配置参数的.那我们还要分析原因. 因为理论上这是因为master对node2的ip识别有误. 或者是node2提供给master的路径有误. 我们要看看是哪种情况. 首先想起来之前的/etc/hosts 下配了ip-name的对应解析. 这个删掉. 再看看
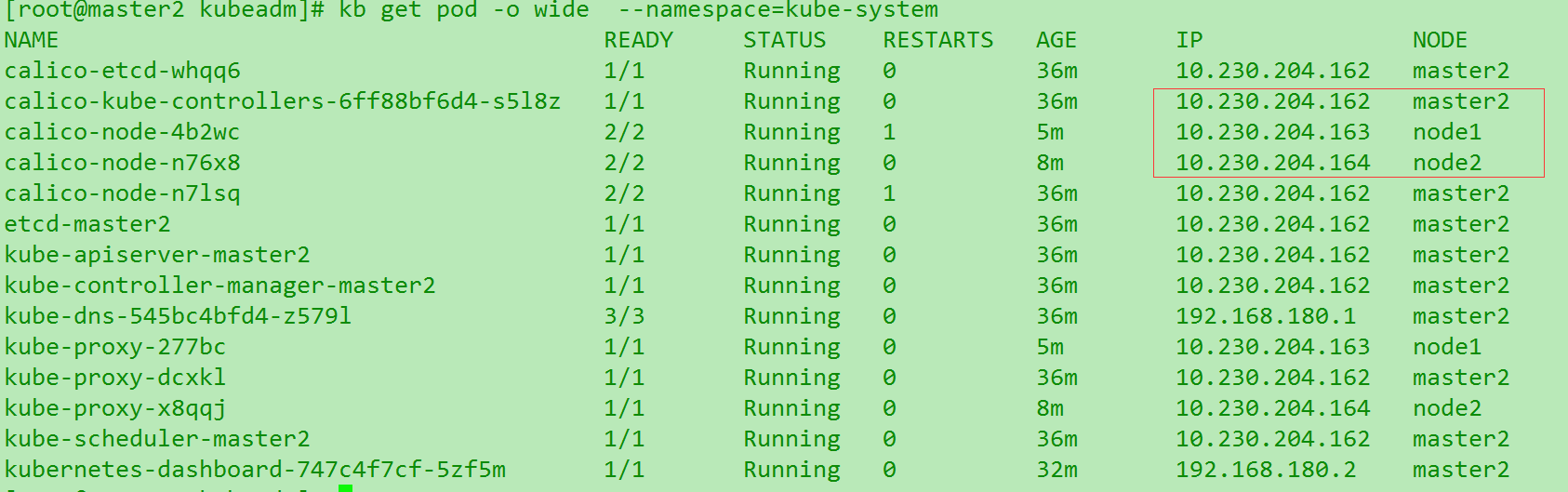
发现重新加入就ok了. 然后我们还不能掉以轻心,试试把heapster加进去. 加进去很简单.加完之后也没有报错,启动ok. 但是heapster没有显示效果… 我们考虑是不是直接调用了之前node1/2的退出的容器.先把容器rm 掉. 发现容器本身在kb delete 的时候就被rm了. 那么考虑是组件自身问题. 两种思路:
- 暴露三组件外部端口
NodePort,然后查看每一个的dashboard - 查看heapster日志. 因为它是负责收集
cAdvisor的 .最容易跟之前的老版本冲突.也可能是之前的挂载没有清空,好好读一下yaml文件. 官方troubleshooting参考
首先第一种思路有问题. 直接设置外部端口都是两个提示404,一个没有任何显示. 推断要么组件安装有问题. 要么不是这样去访问它们的dashboard. 开启参考这篇
第二种思路,
其他待汇总ing
0x01.dashboard相关问题
dashboard(包括heapster)这里发现一个别人blog上的图的不同问题. 初步推测是因为dashboard的版本不够高. 尝试到1.9.1+最新dashboard试试.
0x02.harbor安装错误
1. K8环境中RC不断backOff 镜像 (1.3/1.2x版本)
1.3版本的镜像算是无数的坑,几个1.3版本的RC会不断的报错,反复重启如图
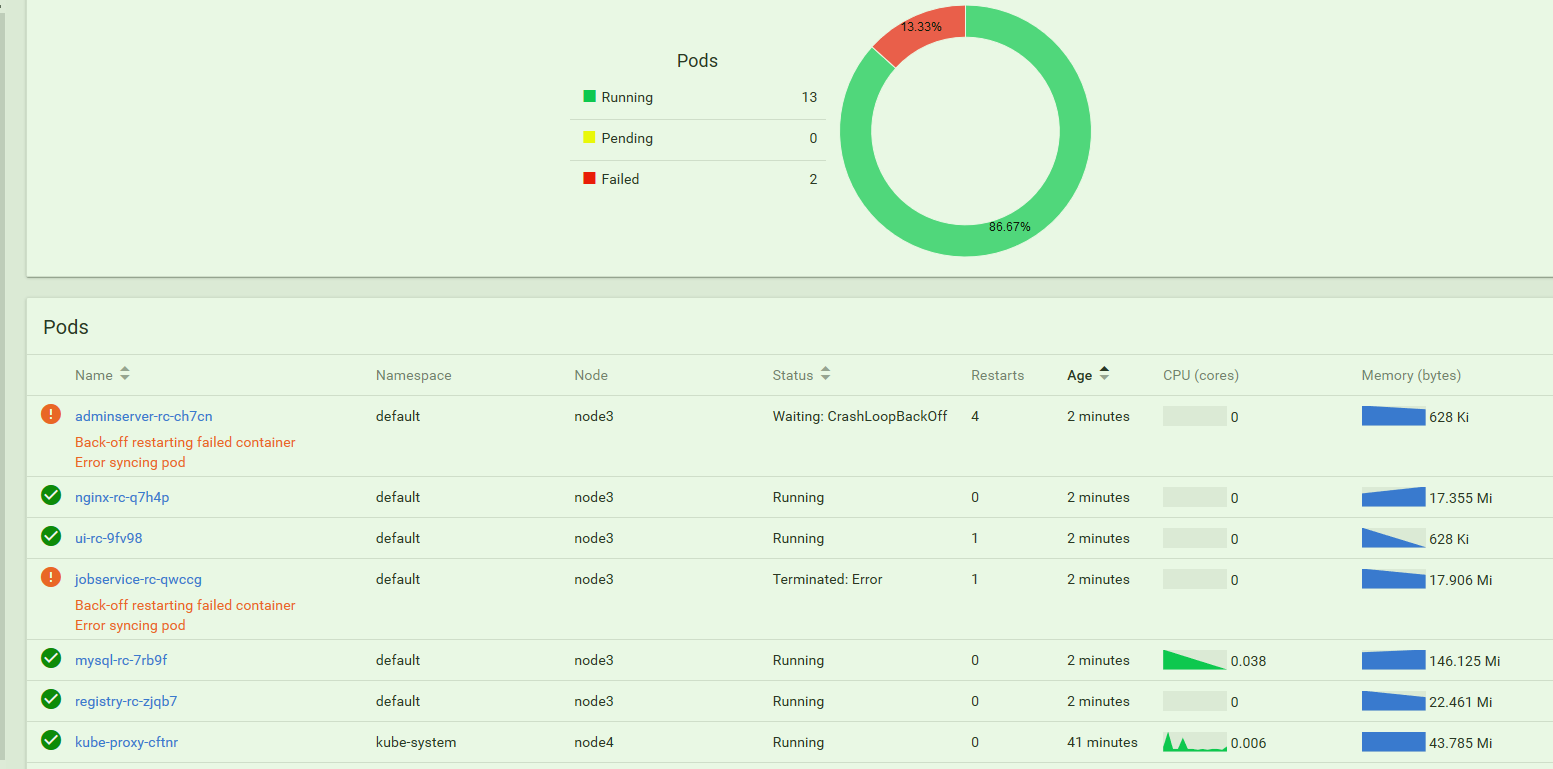
还是换1.2.2了. 先从master中把几个大坑的RC删掉,就是1.3版本的几只. kubelet delete -f xxx.rc.yaml , 最好是把1.3的一堆都删了,以免后面导入1.2.x的镜像又重叠.

然后发现1.2.2稳定一段时间还是会照旧出现问题,但是通过describe发现貌似陷入了互相抢占的冲突.
最后发现问题根本出在配置上端口暴露的地方. 这的确是个大坑,需要在harbor.cfg 文件的hostname 设置ip的时候加一个31000到33000之间的端口(不能冲突). e.g : hostname= 172.17.7.205:31997
然后在 nginx.svc.yaml 中添加一个 nodePort:31xxx (跟刚才设置的一致). 然后访问的时候带上端口.就会镜像正常了.
2. docker登录harbor报错
根本原因还是在于没有使用https.所以到头来不先弄CA一套,坑的还是自己…. 参考blog.
上面blog修改的地方cent7是错的…..到处都是天坑,而且你随便改错会导致master的组件失效. 正确地址应该是vi /usr/lib/systemd/system/docker.service 修改其中 :
1 | ExecStart=/usr/bin/dockerd-current \ |
然后 然后使用systemctl daemon-reload & systemctl restart docker `
3. docker-compose安装后端口占用
参考官方文档的Managing Harbor's lifecycle 部分.
1 | $ docker-compose down -v #批量停止移除,等待全部完成再下一步. |
4.docker-compose安装后无法访问(harbor本机可以curl到)
这个异常蛋疼 ss -tnl 查看一下端口情况.发现是正常的. 本机docker login -u admin harborIP 也是正常的,就是其他节点无法访问. 可以采取以下方法排错
- 在自己PC机上的VMvare开启一个节点,采用相同环境然后安装harbor,看看是否能访问,如果能说明是网络问题
- 在服务器/虚拟机上建一个纯净cent/ubuntu节点,然后安装docker+docker-compose,关闭firewalld,确定防火墙没问题,然后看看是否能访问. (大多是这个问题)
- 如果以上都不行,尝试跟虚拟机所在网段的管理员联系,看看是不是做了什么限制.
5.harbor仓库主从测试失败
这个问题遇到跟4的问题是很相似的. 但是我从中发现了问题,两台近乎一样的虚拟机,一台测试秒通,一台不通.
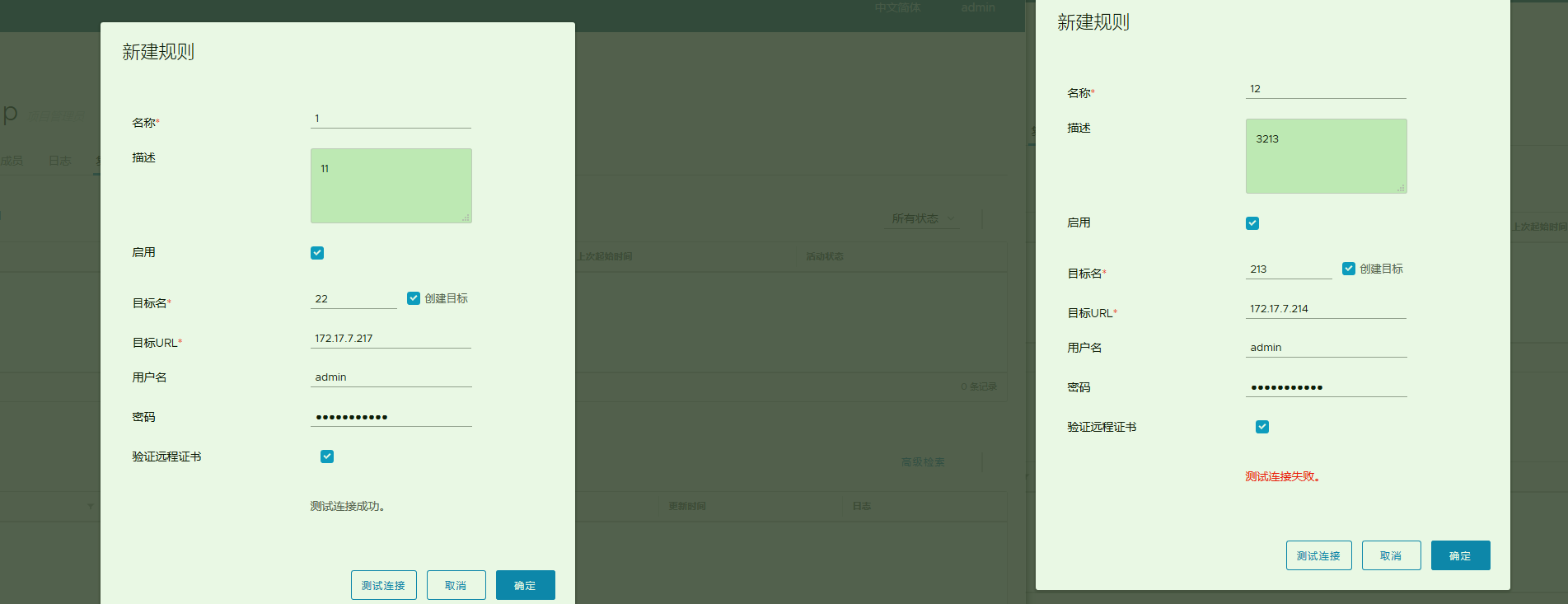
对比发现唯一的区别就是秒通的那台开启了firewalld ,而不通的那一台因为担心k8的网络问题,提前把firewalld 禁了.两台都可以互相curl或者ping.
重启harbor并新建会发现有这样一条关键: Creating network “harbor122_harbor” with the default driver . (default driver是基于谁? 不出意外应该是docker的虚拟网桥.)
现状 : A测试连接B是通的, B测试连接A不通的话. (测试发现)
- 如果stop A的firewalld: A,B测试都不通了. 仍然可以互相curl,ping
- 如果start B的firewalld: A,B测试都不通了, 因为B直接出现了问题4 的情况,就是curl都没有响应.关闭后恢复正常
然后很简单,控制变量. 我们分别新建一台A 的克隆 A1,B的克隆B1.然后互相做测试,最后结果果然是开启firewalld的正常.互相都是通的.
这说明两点:
如果模板机上预装docker的时候没有关闭firewalld,那么因为docker启动的时候,会在linux主机上创建一个docker0的网桥,规则是靠这个网桥来进行的转发. 那么之后建议也不要随便关闭firewalld.
如果想避免这种坑爹的问题,应该在装docker之前就把iptables/firewalld这种清干净或者禁掉.参考
1
2
3
4$ iptables -F && iptables -X \
&& iptables -F -t nat && iptables -X -t nat \
&& iptables -F -t raw && iptables -X -t raw \
&& iptables -F -t mangle && iptables -X -t mangle
附: 参考文档
6. 重启机器之后harbor部分容器没有启动
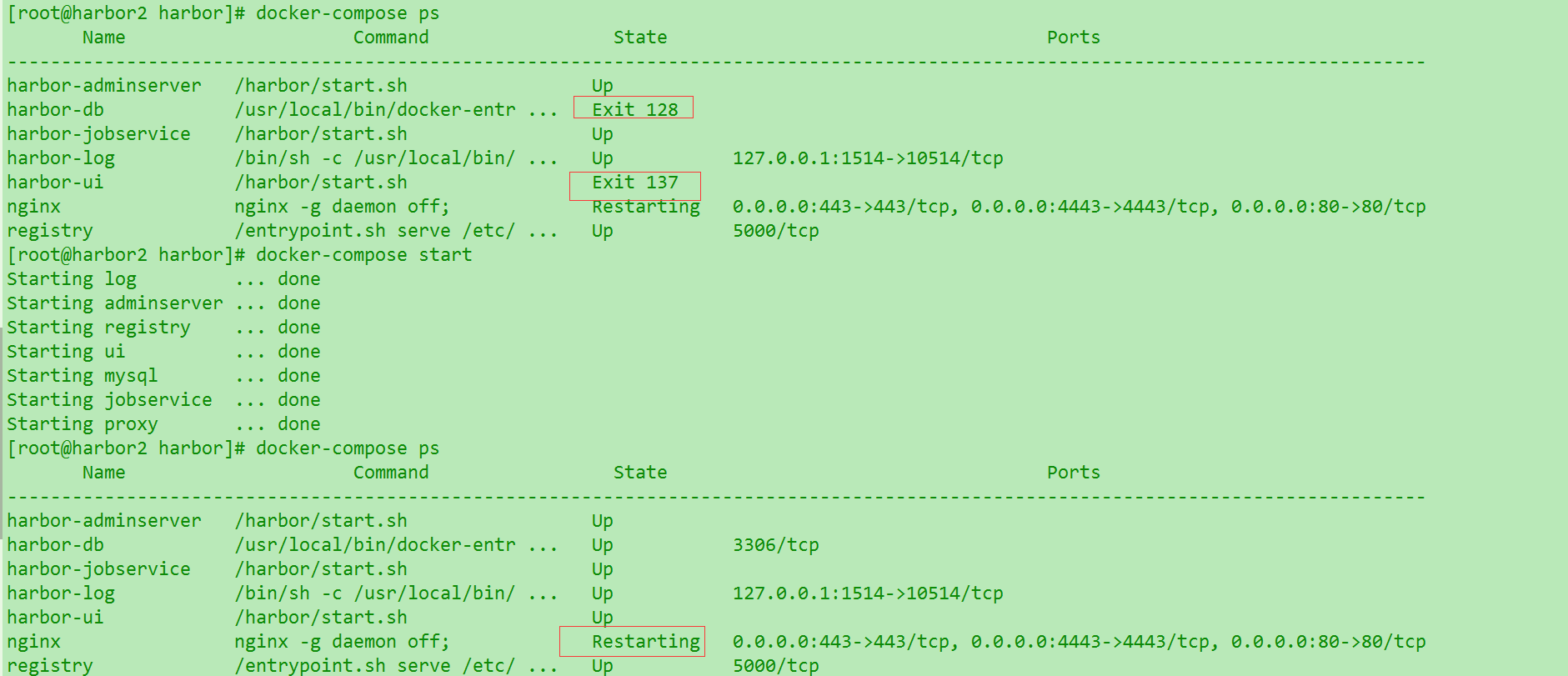
如图,甚至有时候手动启动之后nginx还是处于重启状态,可能需要先全部stop. 具体原因未知.待后续有空补充. 所以目前重启机器之后还是需要检查一下状态.
7.harbor启动直接报log错
如图. ERROR: for log Cannot start service log: devmapper: Error mounting

环境在这之前发生过一次改变,更换了虚拟网卡.切换172的ip到10段下. 尝试移除容器再构建. (命令参考上Q3).重建之后ok了. 暂时记录下来..有空更新原因
0x03. VM中cent相关报错
1.Another app is currently holding the yum lock
这个很蛋疼,有时候会自动解锁,有时候断网会一直卡着.所以最好解决一下. 出现在多个yum 同时占用或者没有退出.
解决办法 :
1 | $ rm -f /var/run/yum.pid |
2.VM中制作快照 & 克隆 & 模板
这三个概念都不一样,实际的技术应该也各有区别, 2和3我估计比较相近. 这里简单说一下.最核心要说的是快照. 因为它可能涉及了 **内存+外存(磁盘)**两个方面的技术应用.
1.快照
可以在运行时创建,也可以在运行时恢复. 以时间点为单位,精确度平常应该可以到秒级误差. 我初理解把它想成是单机游戏里面的存档. 这个大家应该很好理解. 但是在集群中使用就要千万注意,因为存档时间不算快(可能耗时几分钟),这时候如果是k8的master节点,那么其他的node可能会跟master失联几分钟. 这可能有许多隐患. 其次,因为master-node 的这种关联,就不比游戏的回档了,游戏中你是一个人在玩,你随便切档影响的时空是一个维度的.
但是在集群中,有很多个主机是相互关联的. 那么你随意的把某个人的时间回滚,可能就导致其它的主机跟这台主机互相产生不匹配. 这可能会很麻烦 ,所以,建议在k8中做快照,还是先给节点做,然后再给master做.
最好的办法是: 做master的HA,etcd的集群…. 少做快照
2.克隆(vm家族貌似都有,全量复制.)
3.模板(貌似vCenter这种特有,普通vmvare没有)