上一篇入门篇主要在感受在整个k8的脉络,因为k8越了解发现体系越庞大,每个模块,每个知识点都可以写很多的东西. 更别说二次开发,优化,糅合其他技术.所以这次先把它的模块简单说清楚. 配上图去解释
0x00. 体系
k8的文档跟handbook的厚度已经完全不亚于一本经典黑书了. 但是大量枯燥的文字代码介绍会让大部分人望而生畏,很一些核心概念,用图或者动画来演示比文字要形象的多. 然后理解全貌的基础上,再去读文档可能会事半功倍~ (以下所讲已经假设我们的k8集群已经搭建完成, 且具有基本的docker理解)
k8中的核心概念(node/pod/rc/serivce等) 都可以看做是一种**”资源对象”** ,它们都可以通过kubectl工具(或者编程api)去执行CURD(增删改查) 并将其保存在分布式的etcd中实现数据持久化. 所以从这个角度看,k8是一个高度自动化的资源控制系统, 它根据对比etcd 中存的**”资源期望状态”** 与当前实际状态实现自动化运维.
0x01.核心概念
1.部署容器
k8的最小操控单位不是容器,而是一个豌豆荚(pod),即使我们只需要一个容器,也会以pod来定义. 这样的好处等你将docker用于实际项目之后就会明白.
裸docker部署一个应用很简单,用docker pull 拉容器镜像,然后docker run 去启动它初始一个内外映射的端口就可以了. 那么现在加了k8进来,怎么去部署呢? 其实也很简单,一条指令就可以部署pod了,而且比docker直接在命令中设置端口,存储等等冗长的字段要完善的多. (使用yaml配置文件) 见下:
1 | $ kubectl create -f demo.yaml |
2.cluster (集群)
cluster这个概念到处都在说,其实本质是很普通的.多个节点(不管是物理机还是虚拟机),都可以称为集群.那么在k8中,多个node与 master 之间当然也构成了集群的关系.
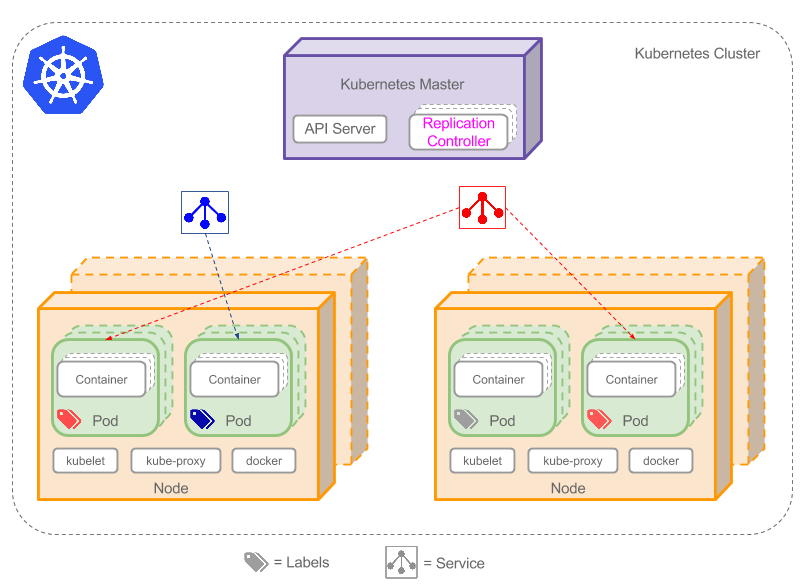
这个图是选得简化的版本. 基于大家在安装完之后已经理解了master - node 的主从体系. master作为控制者去调度集群. 图中关键的组件(Service & Labels 图已标注 )
- Pod (最小单位)
- Label (
 标签)
标签) - Replication Controller (副本控制器)
3.Pod(※)
Pod是k8最重要最基本的概念, 它自身内部结构图如下: (图摘自k8权威指南,清晰度将就一下了..)

可以看到每个pod都有一个特殊的root container(称为Pause容器) ,然后之上才是各种任务容器.Pause容器的镜像属于k8的一部分.(从image地址也可看出).那么为什么要这样设计呢?
- 一个pod通常包含一组container,我们难以对整体简单判断. e.g: pod中一个容器死亡,这时候整体算死亡?部分死亡?监控的效率? 引入业务无关不易死亡的pause容器就可以代表整个容器组的状态,巧妙解决整个问题.
- pod的核心特性共享ip和存储. 那么共享谁的呢? 这里还是需要一个无关的载体,通过pause来作为中介简化容器的通信问题
8给每个pod都有唯一ip,pod内容器共享. 然后k8中任意一个pod里的容器和其他节点pod的容器可以直接通信,这是很有难度的网络实现. 有时间可以专门用一个专栏来讲了.(比如Flannel,calico)
由(2)中图可知,pod就是在节点上的一组容器 + 卷 . 比如一个项目有前后端存储. 他们就可以放在一个pod中,从而可以共享网络和存储. (甚至通过localhost互相通信) .它是临时存在的.不是持久化的实体. 有如下可能的问题:
- 既然pod是临时存在,那么重启node之后pod的数据还在么? 如何持久化data呢? 卷(volumes) 就是为此而生
- 实际中pod当然需要有负载均衡或者备份. 如何自动生成 ? 答: Replication Controller 控制多副本(自动复制)
- pod临时存在还有个大问题,重启之后IP可能会变化,那前后端就对不上了? Service这里就起到作用了.
pod有两种类型: 1.普通pod 2.static pod . 静态pod比较特殊,它并不存放在etcd中存储,而是放在具体的节点上的某个文件中,并且只在此node上运行. (普通pod一旦创建就会被放入etcd中存储,然后被master调度到具体的node,最后**绑定(bindind)**起来) .
默认情况下,如果某个容器意外停了,k8检测到后会自动把整个pod重启(再三强调,k8最小操纵的单位是pod),那你可能会说,咦这样做不是很不划算么? 明明只是pod中一个容器出了问题,却要把整个都重启,为什么呢? (思考题~)
最后简单说一下pod的资源配置. 核心当然是设置CPU/内存. 单位都是绝对值,比如某pod使用了0.2核(等价200m)和0.4G内存. 所以不管是在单核还是百核的机器上,容器对应的使用性能都是等同的.那么在定义yaml文件的时候,就可以简单设置资源额度.
- requests: 最小申请量
- limits: 最大申请量.超过可能会被k8 kill掉然后重启 例如:
1 | spec: |
4.Label
还是看上面(2)的图,图中每个pod都有一个彩色标签. 可能相同,也可不同. 它们跟pod的关系非常紧密. 就像我们常用的K-V对,紧密联系,方便管理汪去分类/操控 pod. 键值对的例子如下,用来标记pod.当然也可以是RC/Service. 通常在定义的时候就确定,也可以后续动态修改. 通过给资源加标签,可以非常方便的实现横纵向管理的功能.举例说明:
- 开发版本:
release: stable,release: beta1,release: beta2(对应稳定版/测试版1,2) - 项目类型:
type: tea,type: orange,type: cow(对应茶叶/桔子/牛xx系统) - 开发环境:
env: dev,env: qa,env:production(对应开发/测试/生成环境) - 人员分类:
tier: backend,tier: frontend,tier: middleware(对应前后端+中间件) - 项目版本:
function: all,function: public.function: government(对应全程版/大众版/政府版) - 质量管控:
track: daily,track: weekly
然后可以使用selector (标签选择器)选择某一部分label所对应的pod,然后将service 或 rep controller 应用到之上,其实也可以想成是一种简化的sql对象查询机制(类似select * from pod where tier=backend). 提供两种查询方法:
- 基于等式 :
name=mysql-slave–>匹配所有带mysql-slave标签的资源 - 基于集合 : env not in (frontend) –>匹配所有没带
frontend标签的资源
5.Replication Controller (复制管控,基本已被Deployment取代)
更新补充 : RC首先已被RS基本取代. 新版来说这两个都可以被Deployment取代. (原生支持滚动更新过程)
可以简单理解为是自动复制 ,只不过它功能不止这么简单. RC(Replication Controller)可以确保在一个时间点上存活指定数量的pod副本. 如果其中某个失去了连接(不管是网络未响应还是其他情况),RC都可自动替换它.使其总数保持一致. (比如如果我们设置A项目有三份副本.如果某一pod宕机.)

看动图是很好理解,但是实际我们应该多想一些,比如如下常见问题:
- 如果之前失去响应的pod是因为网络延迟了,后面又恢复正常了,就有4个副本了,那么RC会将某一个终止.
- 如果业务需求调整,我们需要马上增/缩pod副本. 可以在其他pod照常运行的时候修改为7/2个,RC会自动启动/停止同样的pod. 实现无感伸缩
创建RC,最少需要两个属性:
- pod的template(模板),这样RC才能自动创建新的副本
- label : RC高效工作需要监控label
那么现在有一堆RC自动创建的pod,这还并没有实现负载均衡. 注意了哦,好比你在机器上跑了几个不同端口某个app的副本,是不可能自动负载均衡的. 还需要Nginx 这种web server . 也是单一职责原则的体现.
k8中又需要自己去配nginx么? 你可以用,但是这里它有专用的service.
6.Service
service这里翻译成服务很容易搞混,这里更适合叫它proxy(代理). 特别是后面还有个kube-proxy .一定要区分好,这个到时候也会单独说.(k8中的service机制).
因为docker跟pod的网络设定,重启之后ip就可能会变化,前后端绑定的时候通常都依赖一个绝对路径.这里service通过label找到对应的一个/组pod,然后在这些pod上加一层策略抽象. 听到这大家肯定也难理解,不是上面说是就是类似nginx做负载均衡么? 或者想让pod的ip固定,怎么突然就扯到抽象了? 还是要举例+动图演示
假设现在:
一个FE,有两个BE(后端)的pod,对应的Service名为 “be-service” ,label是(type=backend,project=tea). 那么 be-service 会做以下两件事:
- 创建一个本地集群的DNS入口,FE(前端)的pod只需要DNS找到主机名叫
be-servive,就能解析出FE对应的可用ip - 现在FE有了BE的ip,但是有两个BE,它应该访问哪一个呢? 这里service就提供了透明的负载均衡,会把请求根据负载算法分发给其中一个.通过每个node(节点)上自己的
kube-proxy完成. (细节后续补充.)
给个简单动图展示service的作用,注意具体的实现跟网络配置并不简单,实际研究需要进一步深入.
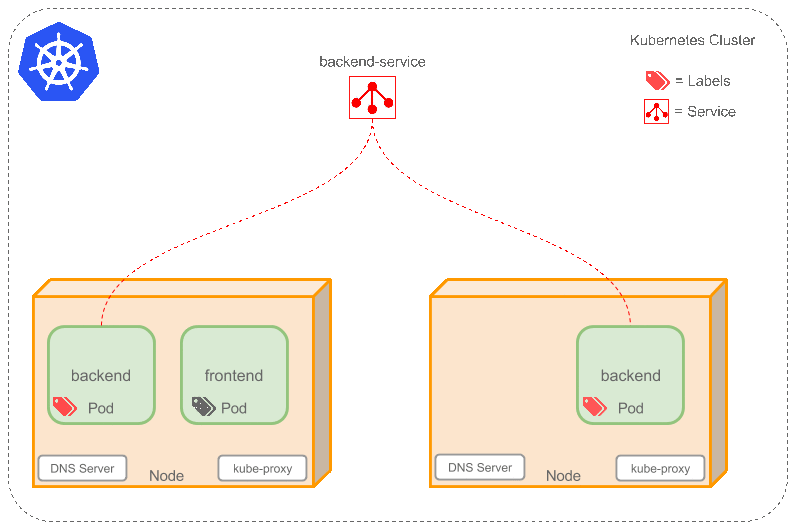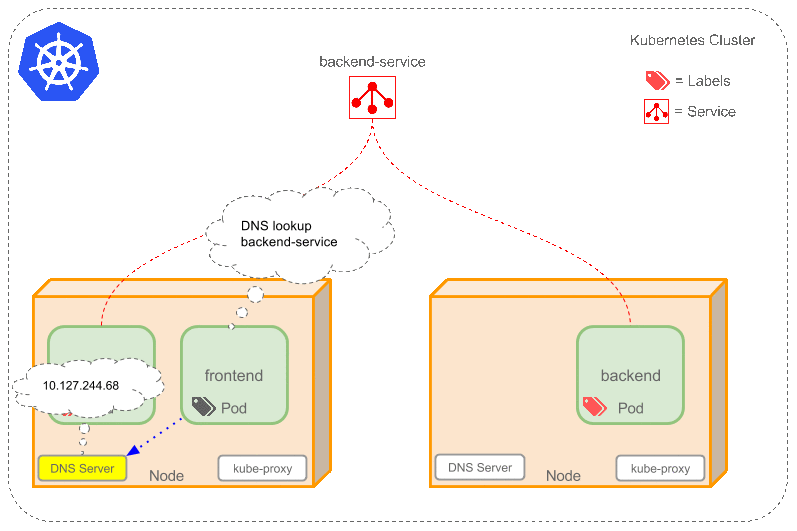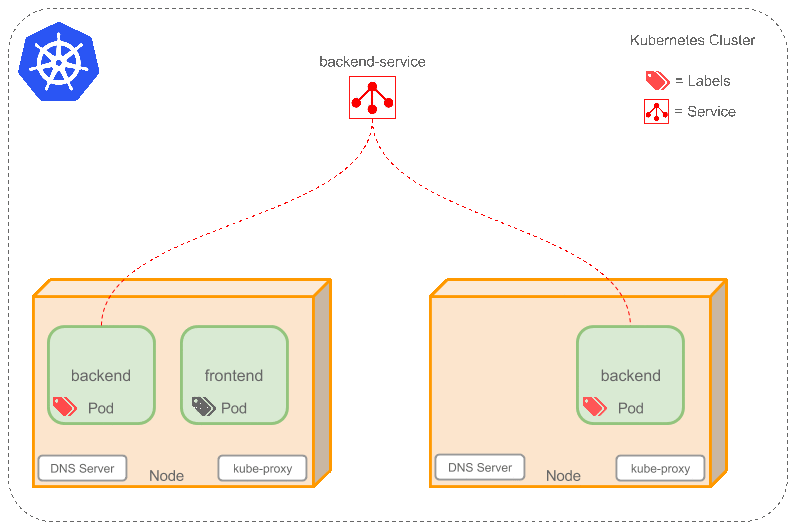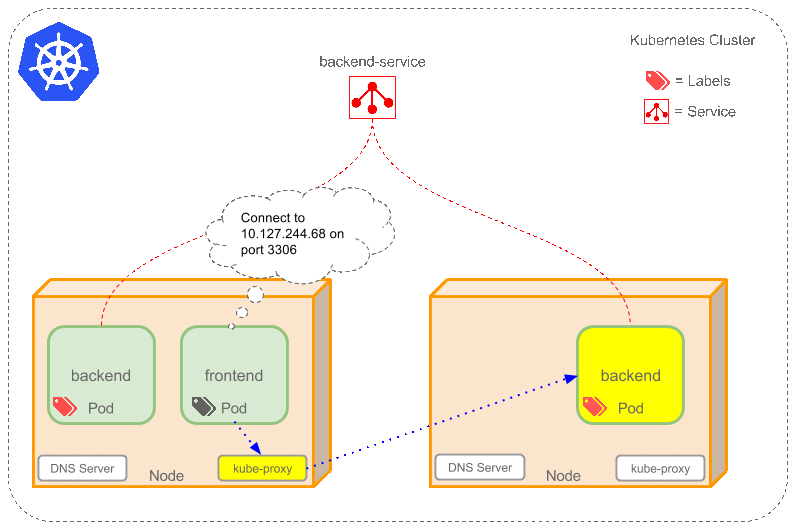
补充: 有一个比较特殊的k8s的service,称为LoadBalancer ,作为外部的负载均衡使用. 在 一定数量的pod之间均衡流量. (待补充)
7. Master
之所以把这两个放最后说(一般都是放最先),是因为这两个在上一篇初窥门径(一)里面实战过的应该都清楚很多了.这里不再累赘. 简单说一下重要的点 :
- master是首脑, 所有执行命令基本都在master上,所以生成环境master必须添加高可用(多个master副本,一般建议为3个)
- master当然也可以作node使用,但是一般不建议这样.然后总数一般为奇数,因为etcd的决策需要半数以上统一.
- master上特有的核心组件
- kube-apiserver : 提供k8所有资源CURD的唯一入口(满足RESTful规范),也是集群控制的入口进程.
- kube-controller-manager : k8所有资源的自动化管控中心,可以当做各种资源的总管大臣
- kube-scheduler : 负责资源pod的调度进程,相当于公交调度中心
8.Node
Node早起版本称作Minion(所以慎看使用这种说法的blog). node是k8集群中实际干活的,被首脑master分配任务执行,如果某个节点宕掉,其上的工作负载会被master自动转移到其它节点上去. (如果多个节点出现问题呢?)
每个节点都有以下核心模块(进程):
- kubelet : 负责pod中具体容器的创建/启动/停止.与master是密切合作的,最核心的模块
- kube-proxy : 之前说过service是全局上的代理,kube-proxy是与service沟通和负载均衡的核心.
在node正确安装配置后,它可以在运行期间动态的添加到k8中,node会定时自动向master定时汇报自身情况(CPU/内存/pod运行情况等),这样master才好高效均衡的进行资源调度,如果某个node超过时间失联,master会显示为Not Ready状态,然后触发负载任务自动转移.
可以通过kubectl describe node nodeName 的命令查看具体node详细信息. (这里注意的是node必要的自检):OutOfDisk,MemoryPressure,DiskPreesure,Ready. 前面几个False 状态的时候正常,不然就是磁盘/内存超了. 最后都没问题就会设置Ready = True .
0x02.简单实战
环境搭建好,概念基本理解就开始马上上手. 加固对上面模块的理解和实际观察.这里沿用经典的Java+mysql+tomcat组合快速用k8跑一个实例.
先创建mysql的RC—mysql-rc.yaml ,并用kubectl create -f mysql-rc.yaml 应用. 需要特别注意的是 : 这里labels必须匹配之前的spec.selector. 不然RC会不断重试.
1 | apiVersion: v1 |
创建完成后可以观察动态
1 | $ kb get rc #13s后 |
然后创建mysql的serivce. 然后应用. 等上面两个都成功running之后再创建app
1 | apiVersion: v1 |

可以看到每个service都会被k8分配一个集群ip. 这样其他的pod就可以通过 cluster-ip + port 的方式来访问它.一般情况这个ip是自动分配的,那么我们很自然有个问题 : 既然无法提前知道比如mysql的服务ip,那么myweb 之后怎么去自动找mysql呢? 这里k8巧妙使用了**linux的环境变量** 当服务发现机制. 后续会详细说明. 现在我们知道根据service的名字就能唯一找到一个对应的ip+port去访问.
tomcat的RC. 创建完应用,这里可以思考一下,我们在app的RC中并没有指定mysql相关的属性,k8是如何自动关联的呢? 更推荐的做法应该是使用service的名称mysql去关联.
1 | apiVersion: v1 |
最后是tomcat的serivce.建立前后端联系.
1 | apiVersion: v1 |
注意yaml文件内容是千万不能写错的,空格也是必须有的,当然你可以在dashboard里面写避免出错可能.然后启动demo**必须先把mysql的rc和service都跑起来再去跑tomcat app. 如果提前跑了会出现如下报错**.

如果顺利成功.应该如下. 可以看到急速跑起了一个web app, 唔…不过貌似firefox前端的地方需要更新一下居中了.

可以对比发现,如果熟悉过程,可以急速创建一个apps集群. 并且不同于docker的单纯运行,k8提供了极其强大的dashboard和分类调度以及扩缩容,这个之后再来慢慢体会. 这里不能浅尝辄止,我们继续思考尝试一下以下:
我修改RC的副本数目,该如何操作,效果是什么样的
很自然有两种想法,一种是停止当前的,修改之前的配置文件,然后改副本数重新生成,但是这明显太蠢,肯定跟k8理念不符. 简单查一下api就发现有
scale命令非常简单的控制括/缩容. 如图:
顺便还发现了
replace,autoscale,patch这几个看起来就很棒的命令. 以后再细说我如果停止了某个service对应的容器进程,会有什么现场发生?
尝试发现会直接断开,但是具体细节还没看,因为service的具体原理还没细究.只是表面看明白了没什么意义.