K8S的安装相信经历过的普通新手都是无比难受,加上网上各种教程的过时,OS,环境,证书,验证各种问题.苦不堪言.那么这几节讲如何用专门的构建模块Kubeadm来实现自动化安装. 版本是1.8.1 (后续会更新为1.8.4)
这里需要注意的是,Kubeadm的坑也很多,后面会专门给一个小节总结各种可能出现的错误,大家可以参考一下…. 官方文档,强烈建议阅读
0x00.实战上手
0. 避免踩坑先关的各种东西.* (非常重要)
- master最少给2核,2G的RAM,单核可能
kube-dns启动不来.(经测试确认). 其他node看实际需要 - 永久关闭Selinux :
vi /etc/selinux/config把其中行改成SELINUX=disabled.(临时关:setenforce 0) - 永久关闭swap :
vi /etc/fstab把swap行注释/删掉 . ( 临时关:swapoff -a) - 关防火墙,这个写脚本了
systemctl stop firewalld.service & systemctl disable firewalld.service - 修改每个主机的主机名. MAC地址,
product_uuid以免找不到或者人工出错.ip link检查cat /sys/class/dmi/id/product_uuid查看product_uuid
- 安装中出了问题要看日志journalctl -n 10 ,运行中的日志查看
tail -f 10 /var/log/messages,docker的日志使用docker logs -f 容器id - 使用
kublet init之后, 一定要等kubet-dns模块都加载完3/3 running,再去进行后面的工作 不然也可能会天坑.
进新的机器首先把自己主机名改一下,确保网络curl和ping都是可以的,这非常重要!!!!!!! 如果重复了后面就很麻烦了。
然后加上其他节点的名字,以免发现服务失败.hostnamectl set-hostname master ,然后在/etc/hosts 文件增加其他node的解析 : ip hostname (e.g 192.168.157.90 node1 ) 附上快捷命令 (记得修改ip)
1 | echo "172.17.7.200 master1 |
把整个包传到master/node 机器目录下,tar -xzvf xxx.tar.gz ,解压后结构图如下: (建议吧这个提前解压传文件夹到一个,然后做成虚拟机的模板.避免重复操作费时.) (虚拟机上分发 :scp -r kubeadm/ usrname@ip:/tmp )
1 | #各种自动化脚本,核心三个:Master / Node / Dashboard |
分别在master/node下运行对应的shell(注意要在解压目录内). 来看看内容,因为原始的版本有许多东西没有加进去,手动操作很容易忘记或者失误. 我就自己修改优化了如下: (12.19号更新)
1 | #这是修改优化后的init-master.sh,可以直接复制 |
12.17更新: 注意以下截图跟出错的很多是因为原始的脚本直接执行报错的.我上面附的修改后的脚本是不会报大部分的错了的. 如果你使用了上面的脚本,应该是可以跳过下面大部分的调错时间的.
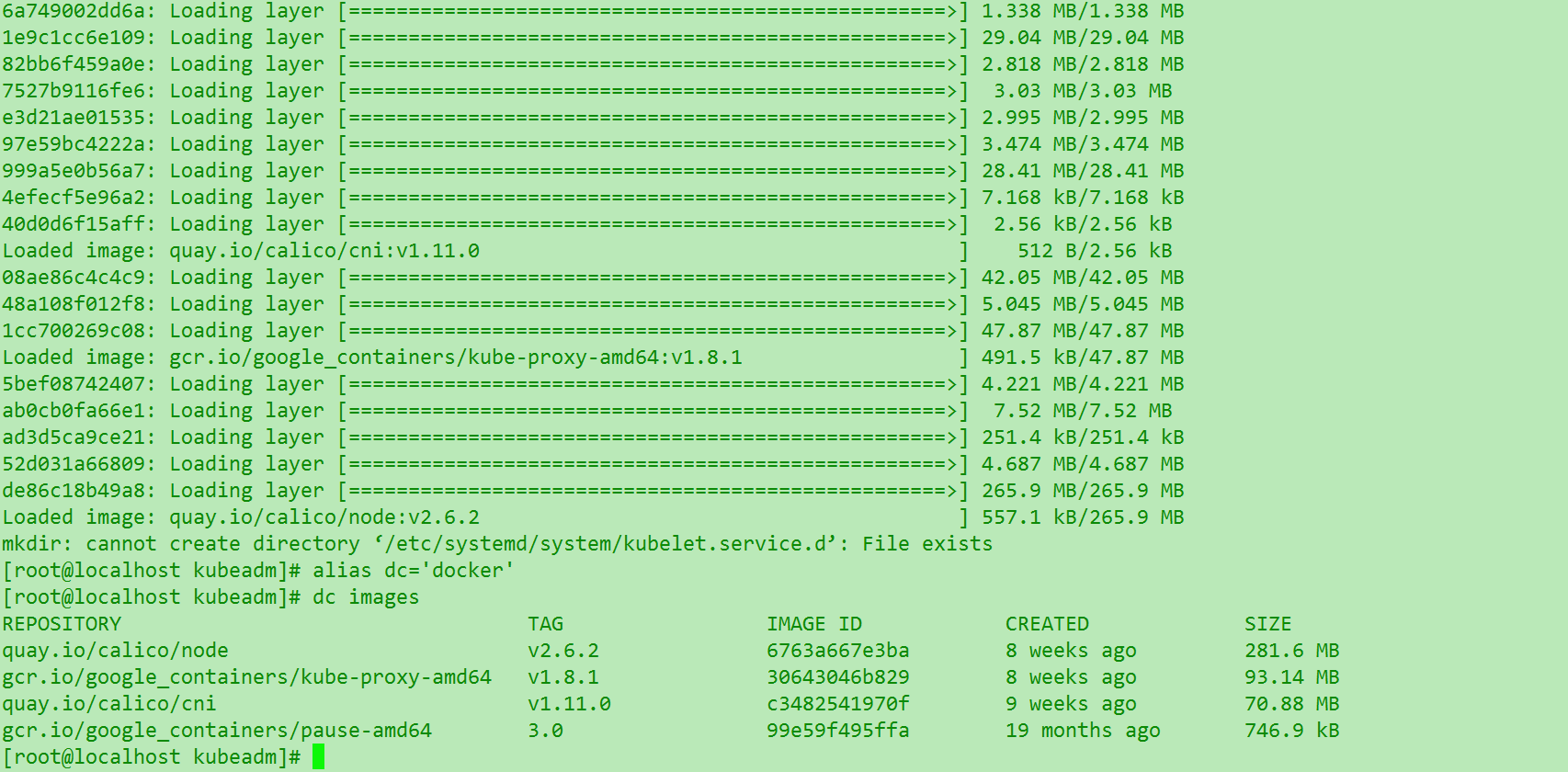
这是node脚本执行正常后的docker images .整个环境都是离线的可以,避免任何的网络不和谐和google的问题…也方便之后批量自动化部署. (这里为了方便自己不弄混多个节点,还是改个主机名.命令见k8初识(一))
然后我们并行执行master脚本的时候发现后面报错了
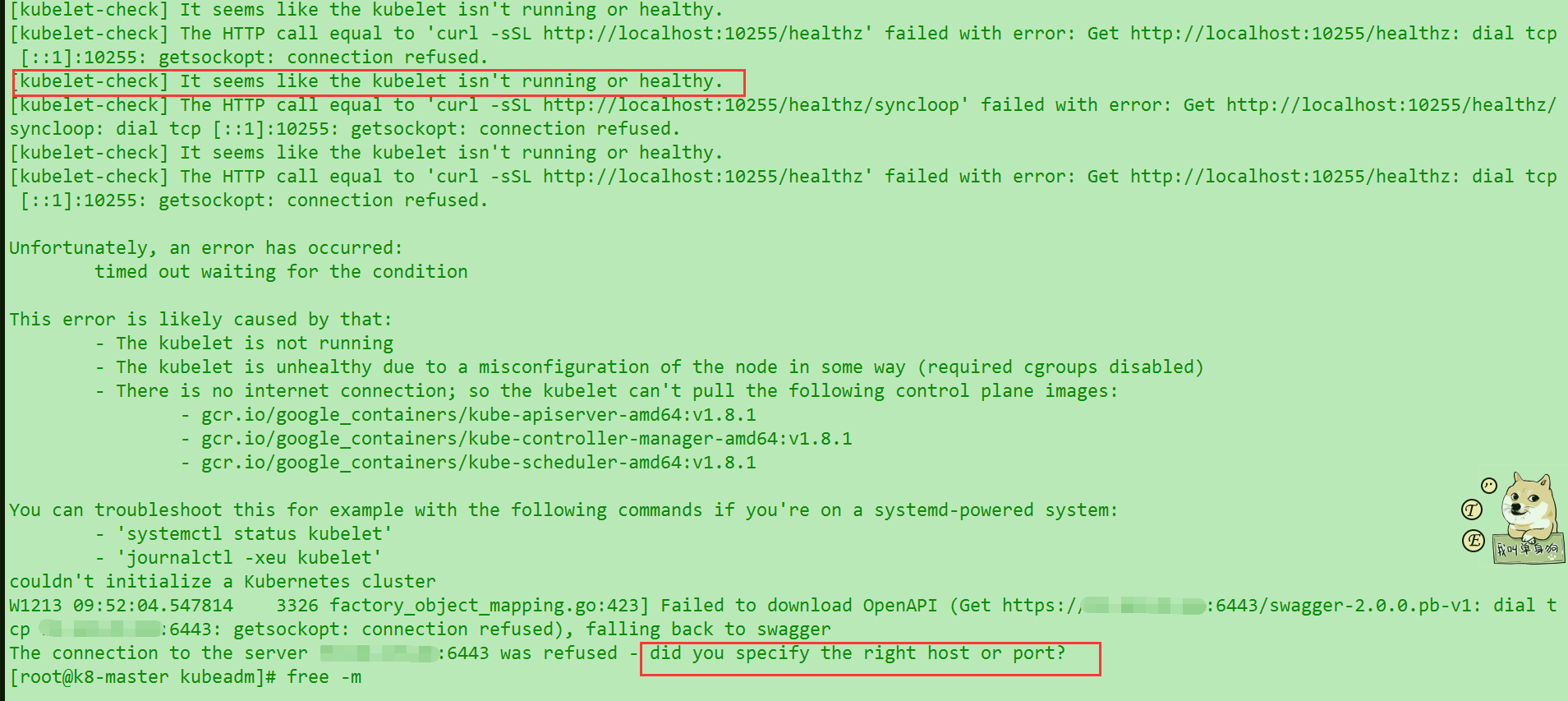
大家先不要慌,遵循RSA解决问题原则. 读了报错信息,查了一下就知道了. 需要把脚本中的--ship-preflight-checks 去掉. 我们试着单独跑一次这行命令,发现还是报错.继续RSA

终于成功, 然后我们自己把master上面语句之后的mkdir -p $HOME/.kube&&cp -i /etc/kubernetes/admin.conf $HOME/.kube/config和最后加载calico网络的命令自己执行一下…
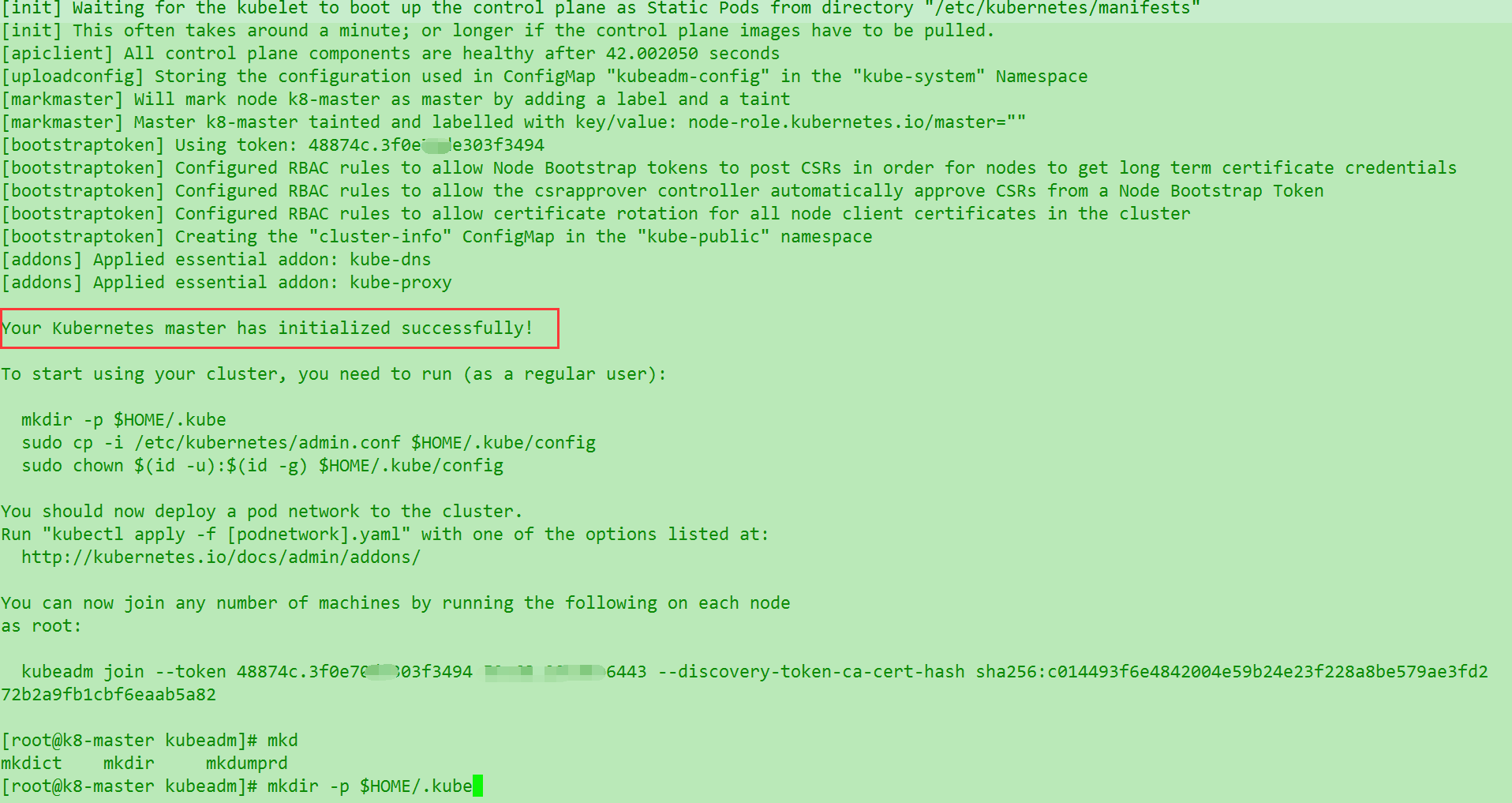
这里因为脚本之前的问题….calico.yaml 解压后位置变化了….应该执行这个kubectl apply -f ./kube-master/calico.yaml
1 | kubectl get node # 显示如下正常 |
一定要等上面的kube-dns 加载完成!!!!!!!! 然后这里先不急着去join node节点,先把dashboard init起来,执行脚本.脚本内容如下: (理解后面)
1 | kubectl apply -f kubernetes-dashboard.yaml |
很快就弹出如下的配置文件
1 | apiVersion: v1 |
这里line 24的 type 需要改成type: Nodeport ,通过端口映射出去. ClusterIP只能内部访问. 默认已经走了https
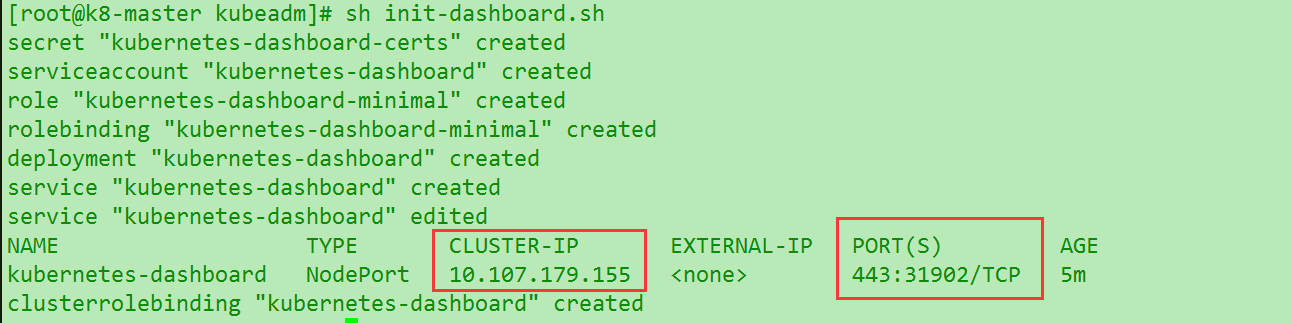
然后尝试访问https://ip:31902 就可以看到初始化的login界面了 注意ip是自己外网的,映射的port是随机的一般都是31xxx.自行修改.完成后ship就可以进入dashboard,但是这个方法是很不安全的,生成环境肯定是要使用RBAC(k81.7之后提出的新安全权限策略). (详情会单独写一篇RBAC的文章)
然后我们把最后生成的kubeadm join --token xxx 一大串复制到node节点去执行.建立联系.
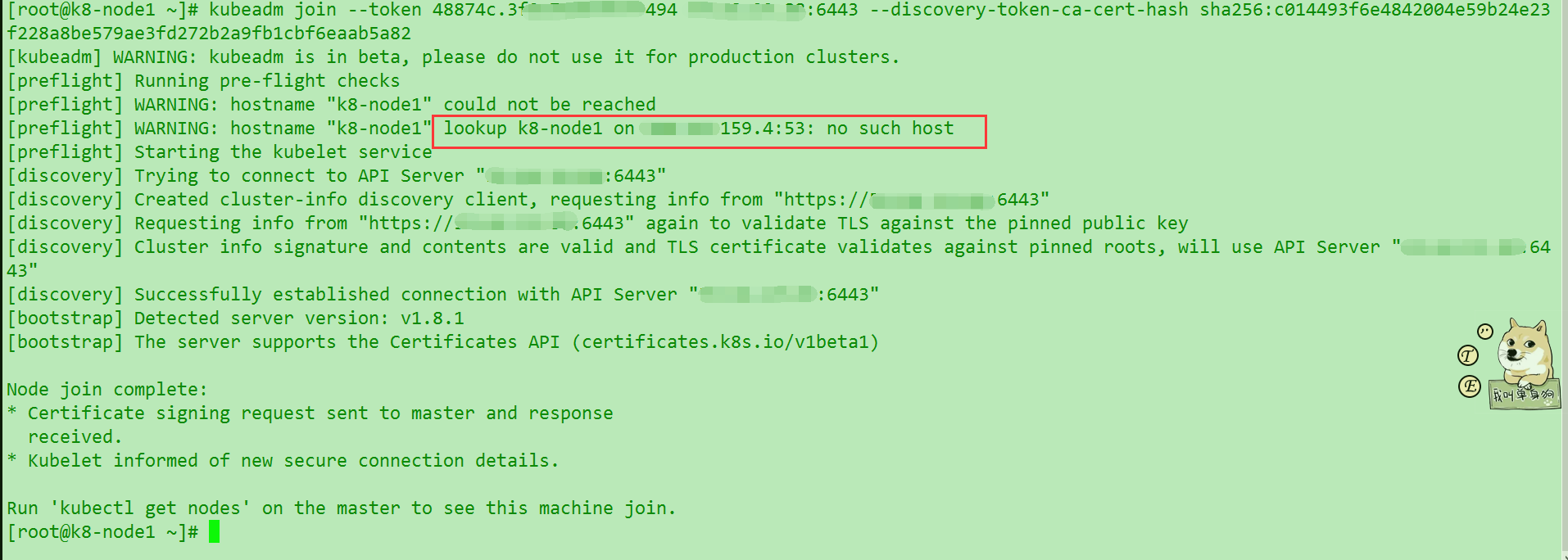
注意: 这里发现node join的时候速度奇慢无比,不知道是宿主机本身原因还是画圈内网dns的原因. 之后会加以验证. 其他节点也是如法炮制.
最后在master 中输入之前查看node的命令,就可以看到节点了,开始的时候是not ready 状态 是因为还没加载好,也没生成对应的calico-node.

当然….我就知道即使到了最后问题还是有的,node就是不启动~ 还是明天再来看看什么情况把…
- 发现异常,当然是先查看日志. 先看看总体日志
tail -f /var/log/messages(因为k8的状态已经看了)
发现报错
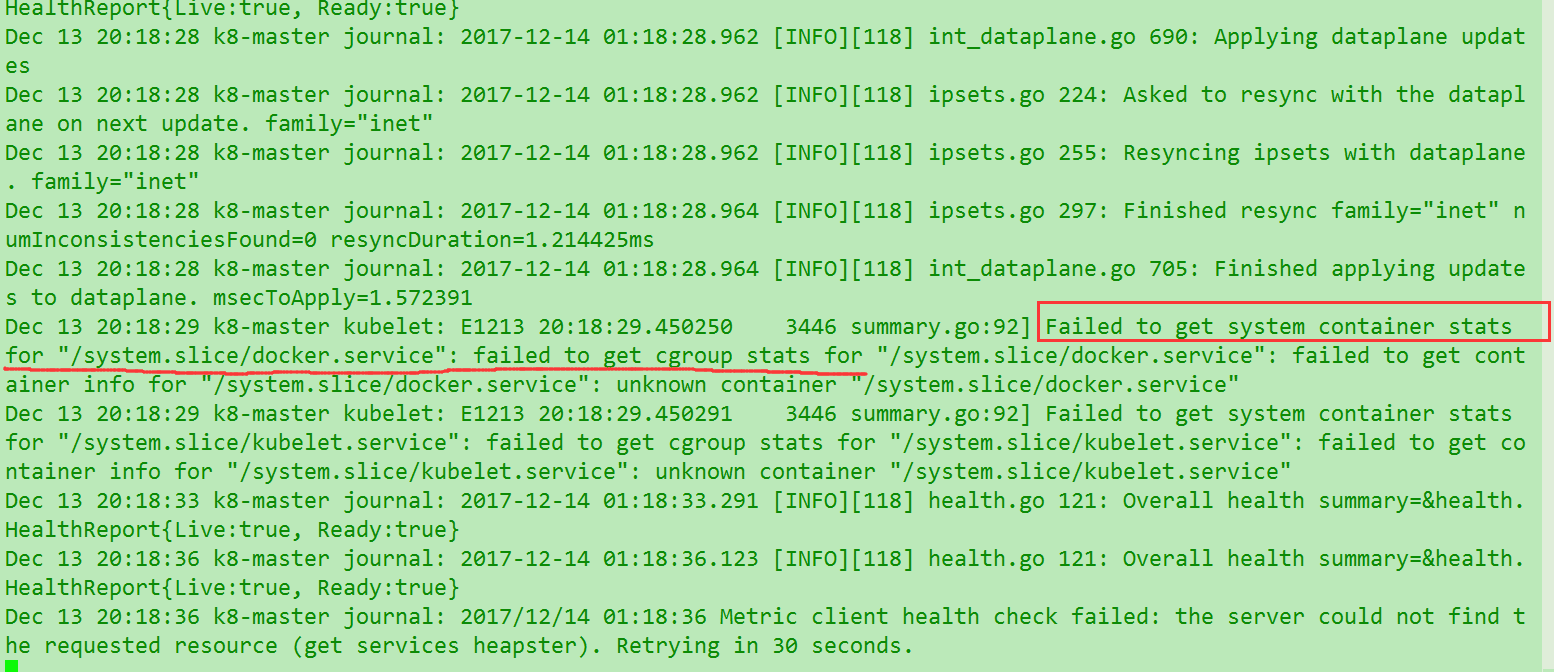
查看控制台发现也有提示报错信息.
| Ready | False | KubeletNotReady | runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized |
|---|---|---|---|
开始疯狂Search,大部分集中在github的issue里面,但是千万注意,大部分是1.6.x版的问题,并不是我们遇到的这个,所以很多都是失效的. 然后剩下都在stackoverflow上找. 解决方法说了无数个,心累无比. 最后继续完整关键字找到一个很少人的… kubelet fails to get cgroup stats for docker and kubelet services.
他说: Try to start kubelet with:
--runtime-cgroups=/systemd/system.slice --kubelet-cgroups=/systemd/system.slice
那么问题来了,现在已经启动了,再如何启动kubelet呢. 我们想到用 systemctl stop kubelet ,发现毫无作用….而且systemctl start的时候也不允许带后面的参数…
最后发现有个配置文件kubeadm/kube-master/10-kubeadm.conf有kubelet 的启动参数. 但是这里有两个ExecStart
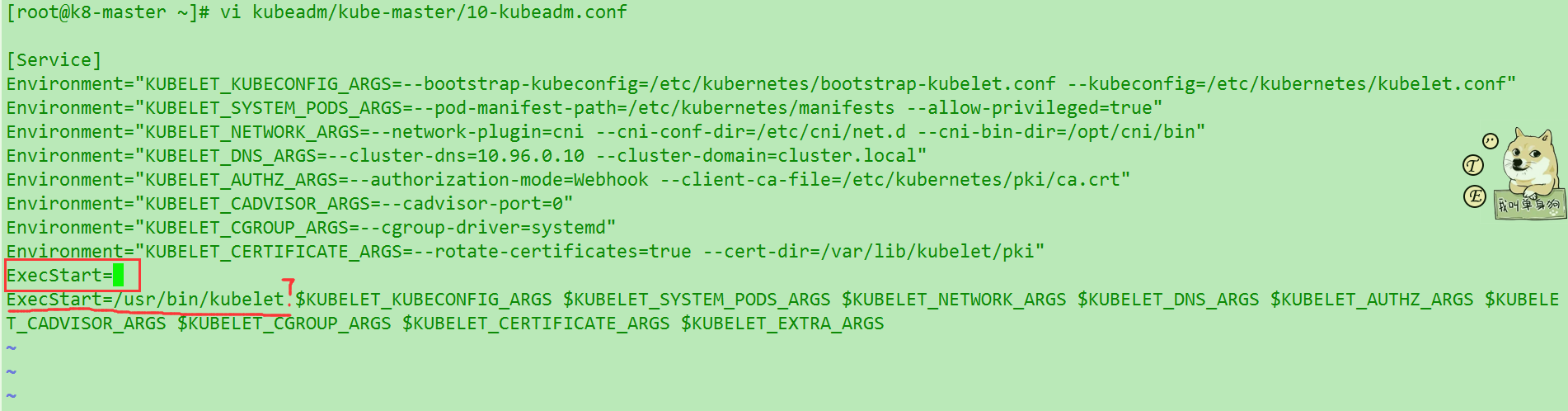
修改完成后发现重新加载systemctl restart kubelet 还是没什么区别. 然后之后虚拟机被停用了….这个方案效果也没有确认. 等后续更新.
0x01. 改进
查看日志总结:
- journalctl -xe
- tail -f /var/log/messages 动态查看
重启后报错. (假设master/node意外down掉了,我们来看看此时的情况),以重启master之后为例

发现服务没有自启动.手工启动发现Go Die..
各种报错和踩坑
内核死锁或者死循环….
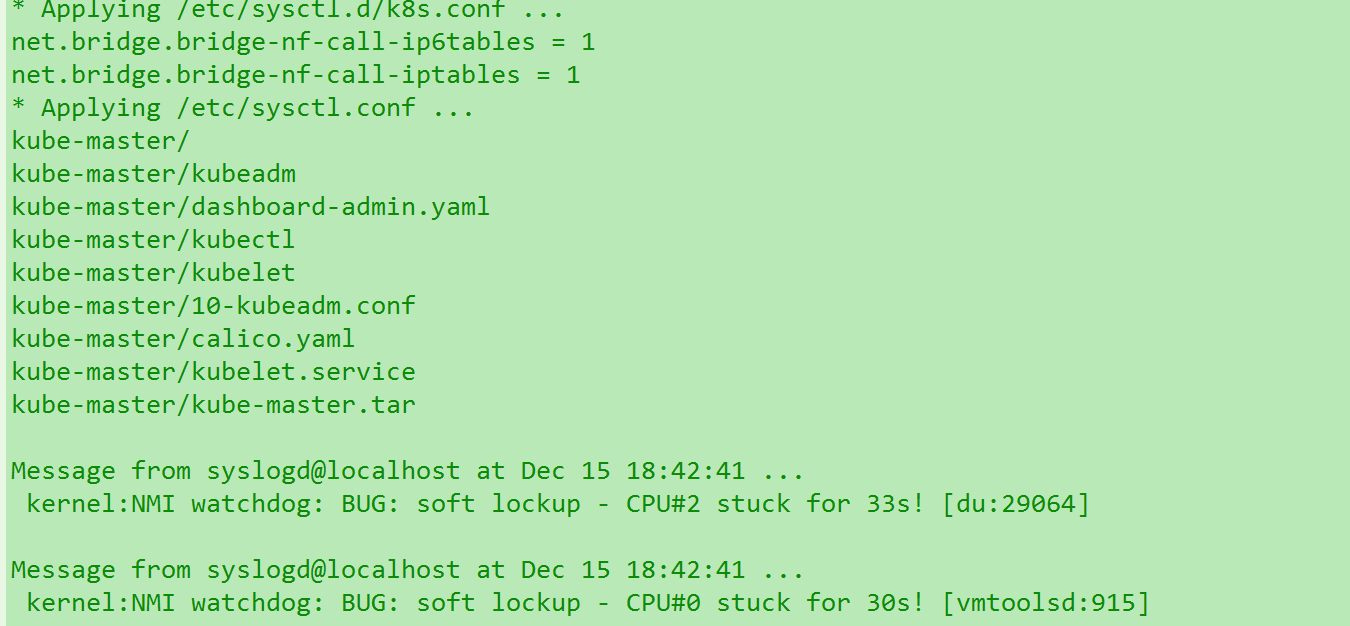
这也能被我遇到? 我去… 原因不明,我试着关闭了虚拟机的多CPU槽.看来要慎重虚拟两个CPU槽..换成一个之后的确没报这个错了…
kubelet安装超时
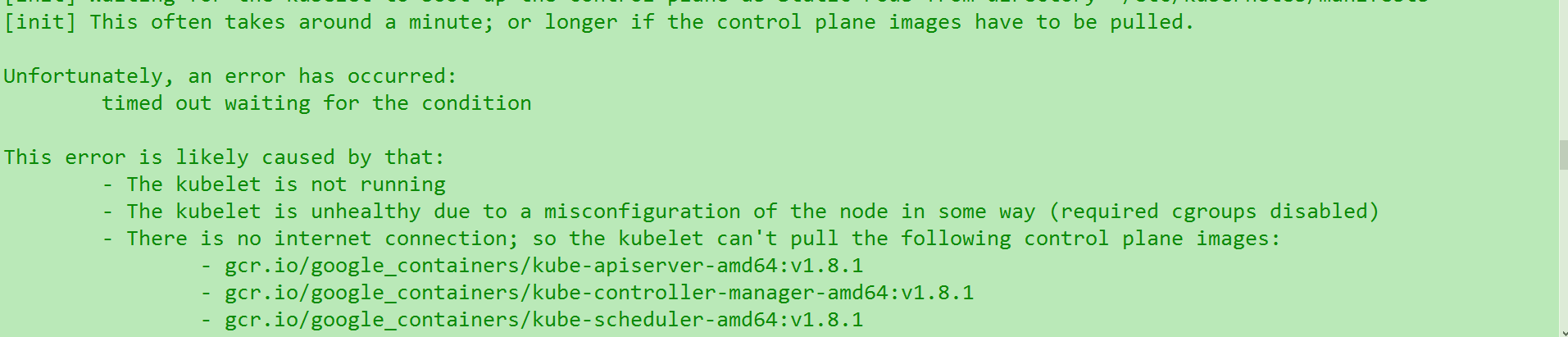
这个也是莫名其妙….完全不知道怎么会卡死.也没有其他报错信息的. 但是总结发现,是因为取消了那个skip的参数. 因为我加上之后就不报这个了. 但是这只是部分环境下. 大家默认使用脚本的时候还是先不要加
--ship. 这个只能在没加卡住或者报错的情况下再尝试. 切记cni config uninitialized (*)
这个错误坑人几天,因为实在太难查. 全部报错如下.
Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
原因太多,至今没有确切有效的方案
kube-dns启动失败 (不要
随便使用reset…)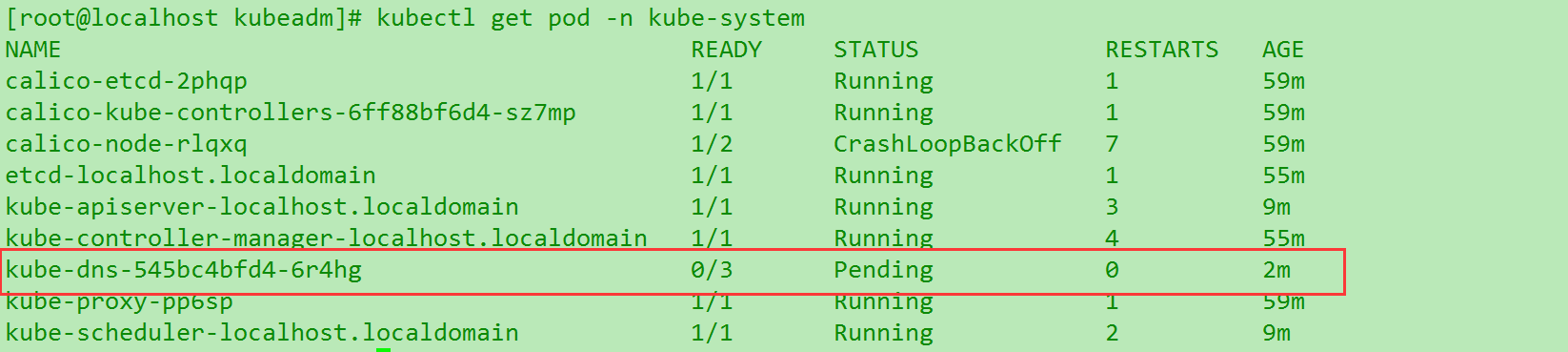
测试发现使用
kubeadm reset虽然可以启动成功….. 但是dns服务再也启动不来了就.等于废了. 所以在有好的解决方案之前..如果崩了就重搞个纯净的虚拟机吧..TLS handshake timeout
这个问题遇到两次了. 唔,建议查看node之前先查看组件启动状态是否完成
kubectl get pod -n kube-system. 不然网络没起来看pod报错也正常. 而且会反复… (就是如图在好坏中间切换.)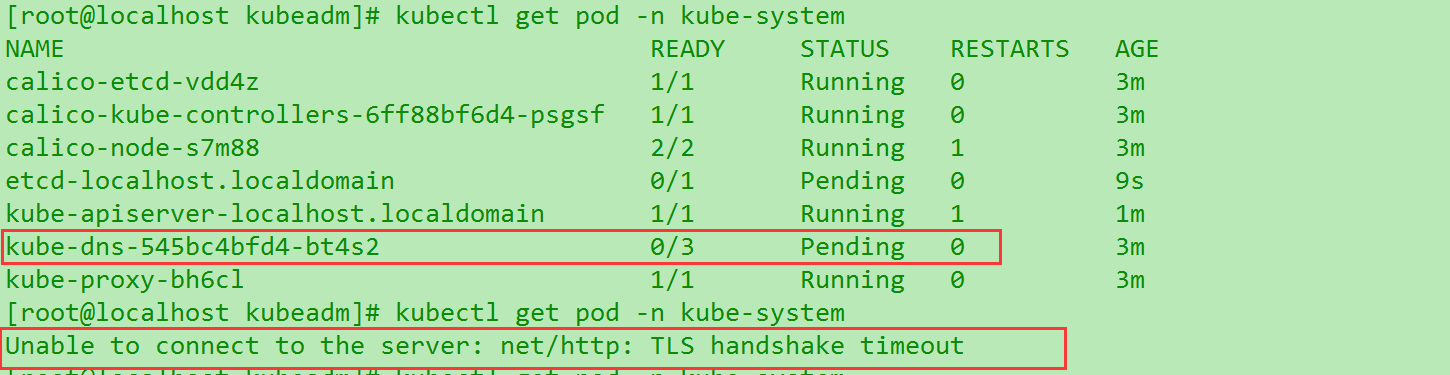
可以发现核心罪魁祸首在
kube-dns这三个一直是准备中.导致网络没起来. 这个在重置之后也遇到过…毫无进展目前. 不好查Swap空间报错
这个错误很可能是因为只是
swapoff -a临时关闭了,重启后没去删除/etc/fstab 带swap行配置.千万要提前准备好… 包括SElinux,也是做模板机的时候就都关了为宜.Node无法join到master (*)
getsockopt: no route to host报错这个. 查了一下很多说是因为防火墙没关. 尝试查看一下fw状态.systemctl status firewalld. 果然跟docker冲突了..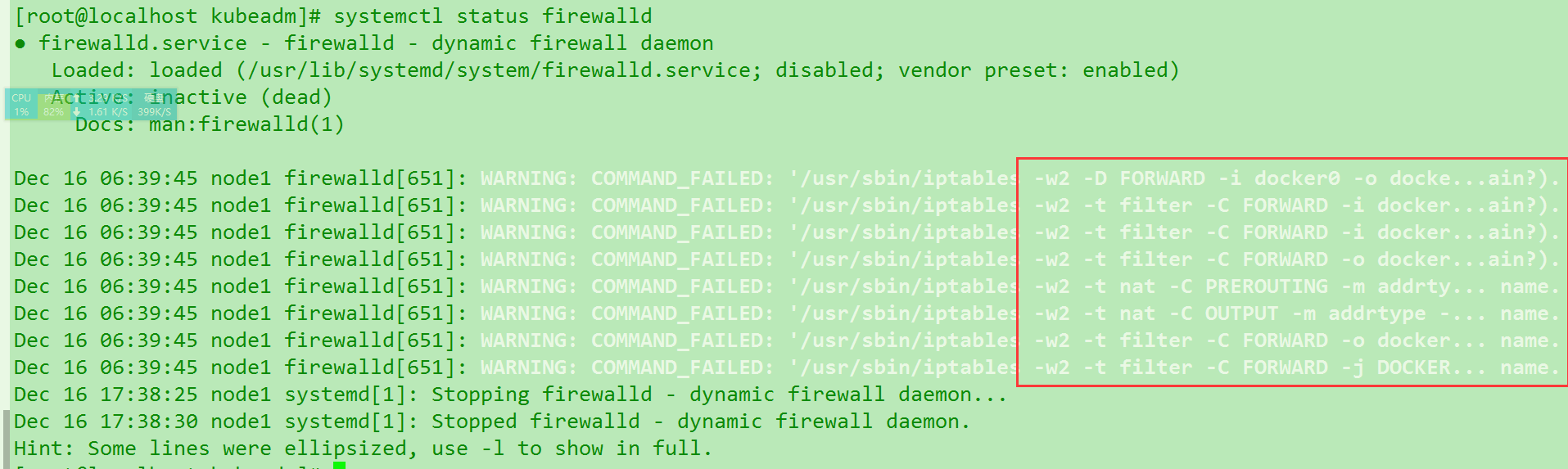
那在脚本里面补上关闭防火墙….而且k8中一次操作失误基本就要重装了,因为你并不知道怎么恢复……千万注意.
然后进一步分析发现原因. node节点无法找到master的路径. curl都是失败的.
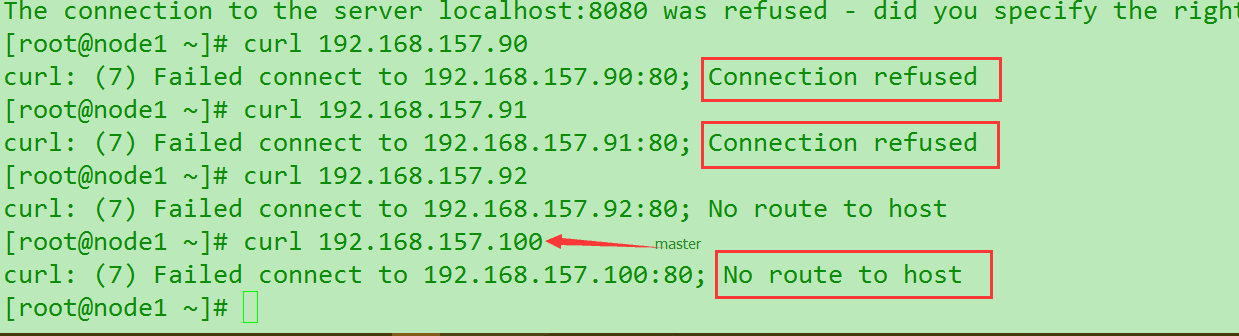
这个时候查阅官方文档,发现网络问题的确很多. 使用
hostname -i查看是否正确解析.以下依次是node1和node2的图,发现不太对.

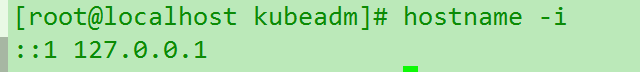
再经过无数的XX的坑人blog说什么cent7默认只用firewall或者直接
systemctl stop iptables就行了这种鱼的发指的话之后,加上我发现iptables calico都在疯狂写入规则.我尝试使用
iptables -F发现…..就都通了.不会出现no fuxing route to host了 . ( √ )通过这次踩坑,还学到了个东西,就是对比
Connection refused和no route to host(快回应/长回应)的区别跟不同 .node节点加入新的master读取不到. (没报错)
因为kubeadm经常会崩,所以master崩也是常见的事,那么如果一个master1下面跑了5个node.之前join成功果,但是后面master1 down掉,重新装了个master2 . 发现node1~5是不能直接join master2的.
如果你无视去join,也可以成功,很快,但是会发现master读取不到….所以千万注意两个事.
- 在master没有稳定之前不要join很多节点,到时候浪费很多时间去重装node
- master的确很需要做HA. 包括etcd也肯定需要做高可用.
纯净cent7.4时间记录 (9点)
05分30s开始安装docker ~ 06分43s 耗时:1分10s
07分45s开始执行init-master.sh 总耗时:4分23s
08分45s解压kube-master.tar 耗时:1分
09分50s加载各种镜像完成 耗时:1分5s
10分30s—–init kubelet命令执行,显示
This often takes around a minute; or longer if the control plane images have to be pulled.出现报错getsockopt connection refused耗时40s.- 重复出现至12分. 提示初始化失败. 耗时1分30s
15分开始尝试执行不带–ship参数. 进入
This often takes around aminute....等待安装成功. 耗时53s
手工执行完后续脚本三行,耗时15s
kubectl get pod -n kube-system 检查完成
所以说如果你master节点全部初始化超过5分钟,多半是出了问题或者错误..别重复试了..看日志找错排错.
0x02.反思
之前是先用1.8.1版本跑了个无RBAC,无高可用的模式.然后有很多的问题.
- 重启master节点之后发现kubectl启动不来. kubelet 服务启动很多问题. 回想起来因为之前二进制法移动过
- 附上VMvare中虚拟机的模板配置,大家可以参考.这是Node跟master公用的东西,提前做好.省事很多.
1 | Pure模板机.几乎没装任何多余东西. |
kubelet module status
通过kubectl get pod -n kube-system 可以查看各个组件状态,用的非常多. 而且核心.常见几种状态: Runinng, Pending ,ContainerCreating , PodInitalizing ,bad,ErrImagePush,Init:ImagePullBackOff 等等.
先说一下node join 到master的过程体现
etcd & apiserver & controller-manager & scheduler 开始进入pending状态.
kube-dns 开始进入 ContainerCraeting 状态. READY : 0/3 , dashboard进入 PodInitalizing状态 0/1
dashboard 进入第二状态
Init:imagePullBackOff如果出错 : dashboard进入
CrashLoopBackOff.看到这个就很麻烦了, dns进入ErrImagePull这就宣布狗带了.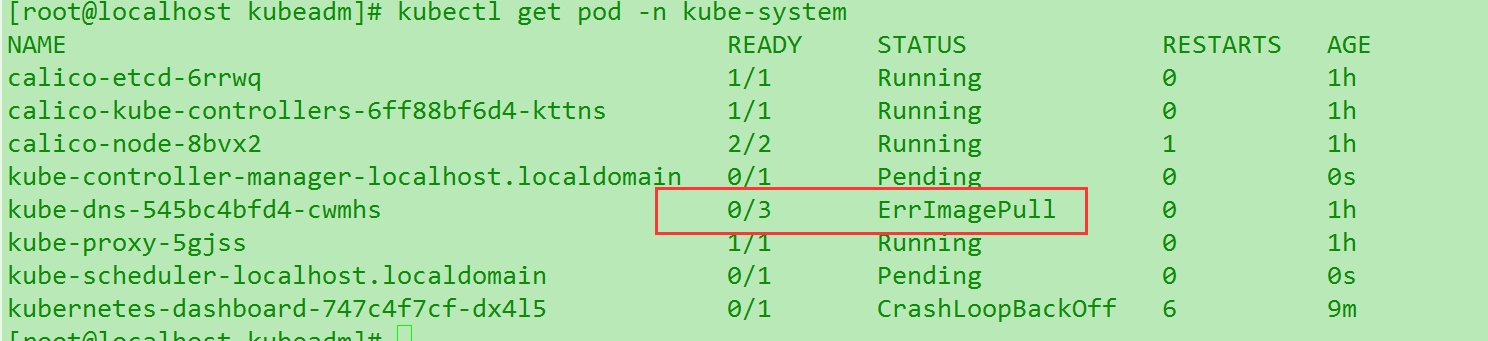
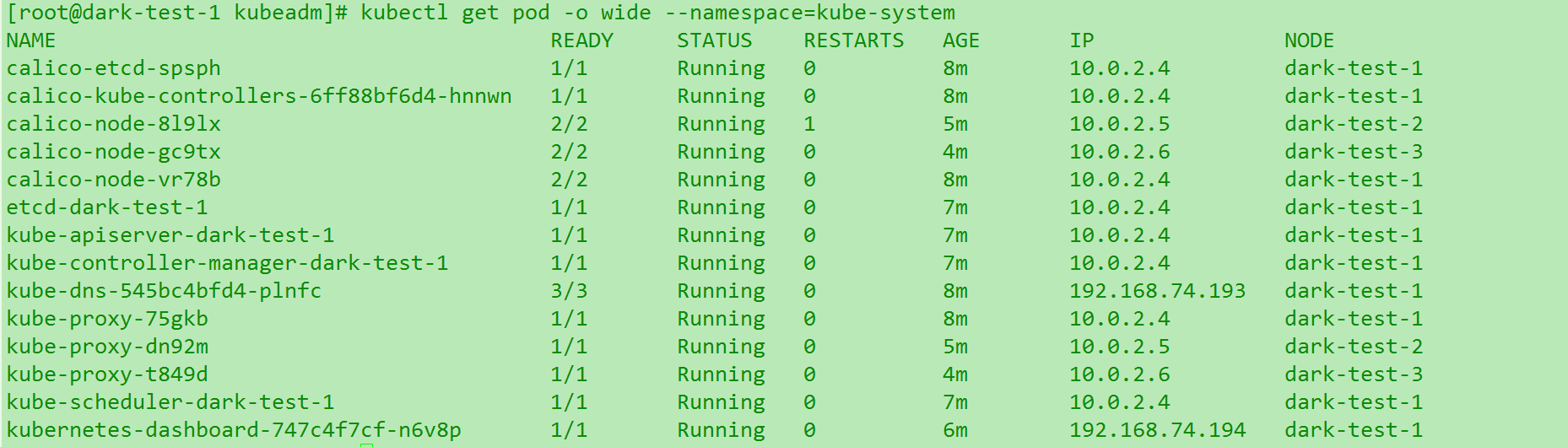
使用命令
kubectl get pod -o wide --namespace=kube-system查看dns或者dashboard挂载的ip是否正常.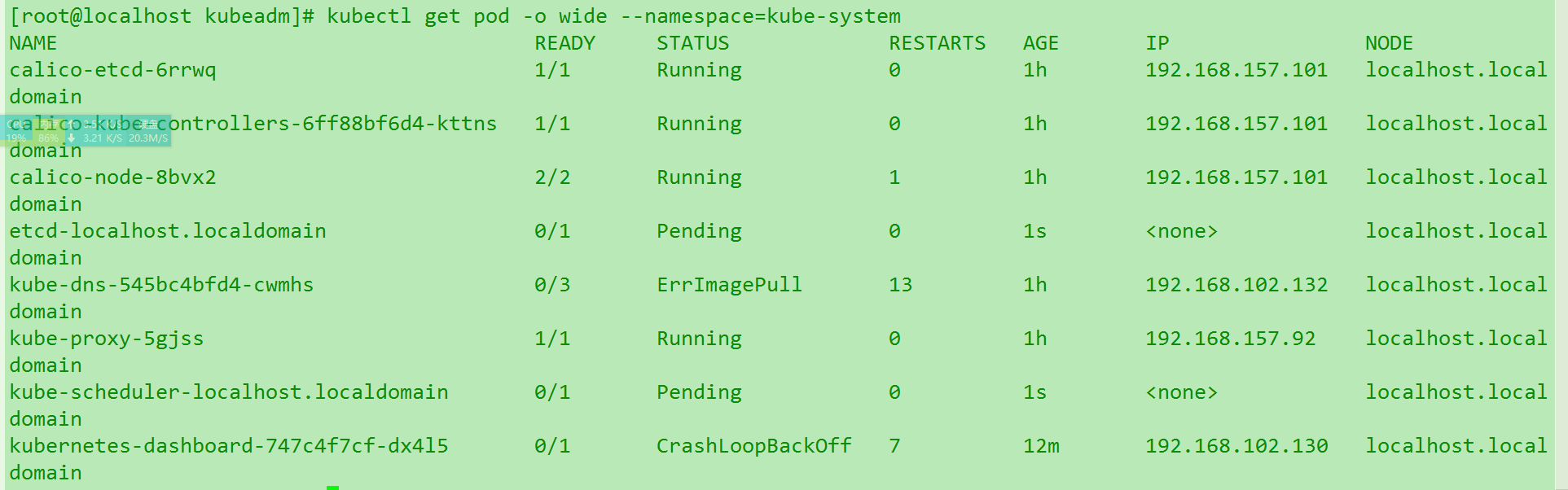 如下是正常的情况: (感谢lcx提供的Azue机器测试. 用正常的机器跑我优化后的脚本是一次就快速OK的.)
如下是正常的情况: (感谢lcx提供的Azue机器测试. 用正常的机器跑我优化后的脚本是一次就快速OK的.)