HDFS上路第三篇接着之前的集群部署, 加入核心功能HA(高可用机制), 因为HDFS的主节点状态很多, 所以需要比较复杂的模块来单独实现
0x00. 基本概念
HDFS HA我理解这里面的单故障点就是Master节点(NameNode), 所以我觉得可以直接类似K8s一样, 说Master HA就挺直观了, 当然这里其实也有两个方案, 旧的方案基于NFS(这里先不多说了). 先看使用QJM(Quorum Journal Manager)的正式方案, 这里先说一下一些缩写含义:
ZK: 全名
Zookeeper, 类似K8s中使用的etcd, 是一个分布式服务感知 + 配置共享的组件. (历史最为悠久/结构复杂)ZKFC: 全名是
ZKFailoverController, 它是一个独立进程, 相当于一个ZK客户端, 并且同时具有监控 + 管理Master节点的状态功能, 一般来说每台Master节点都有一个与之唯一对应的ZKFC, 负责和ZK集群通信, 下面是一张简单的”ZK + ZKFC +NN” 结构图:
ANN 和 SNN: 就是ActiveNamenode和 StandbyNamenode的缩写, 也就是主和主备, 数据节点同时会跟所有master通信, 一般主接受Client请求然后处理, 并写下操作日志(editLog), 然后发给JN集群. 其他主备节点会去读取同步. (每个NN有一个单独的ID标识)
JN: JournalNode, 可以理解为日志节点, 是一个独立的进程, 用来共享管理EditLog, 简单说就是同步多个Master节点间的数据, Master节点读写请求一般需要多数的JN返回成功才认为有效, 一般有3~5个
这是整体来看HDFS-HA后结构图:
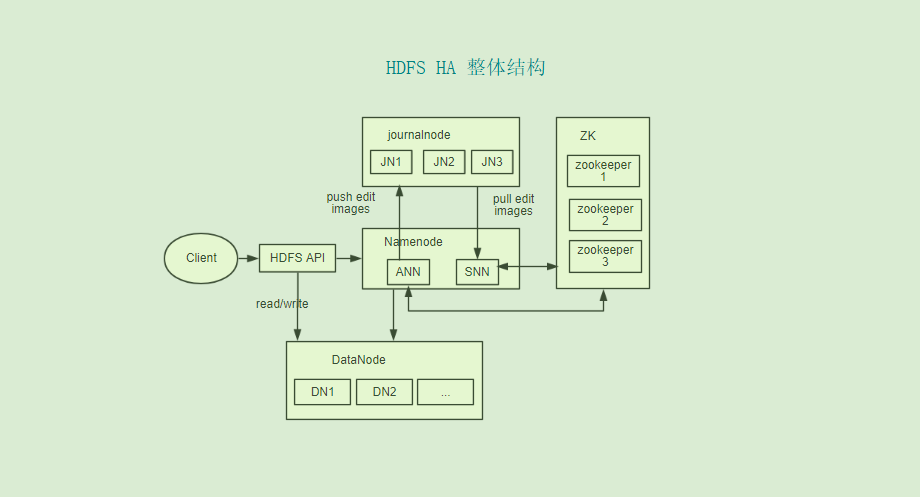
上面的理解之后, 再就可以看看实际生产环境中, 把”Yarn + HDFS” 同时部署的时候, 整个Hadoop集群HA的结构图(虚线框代表单台机器):
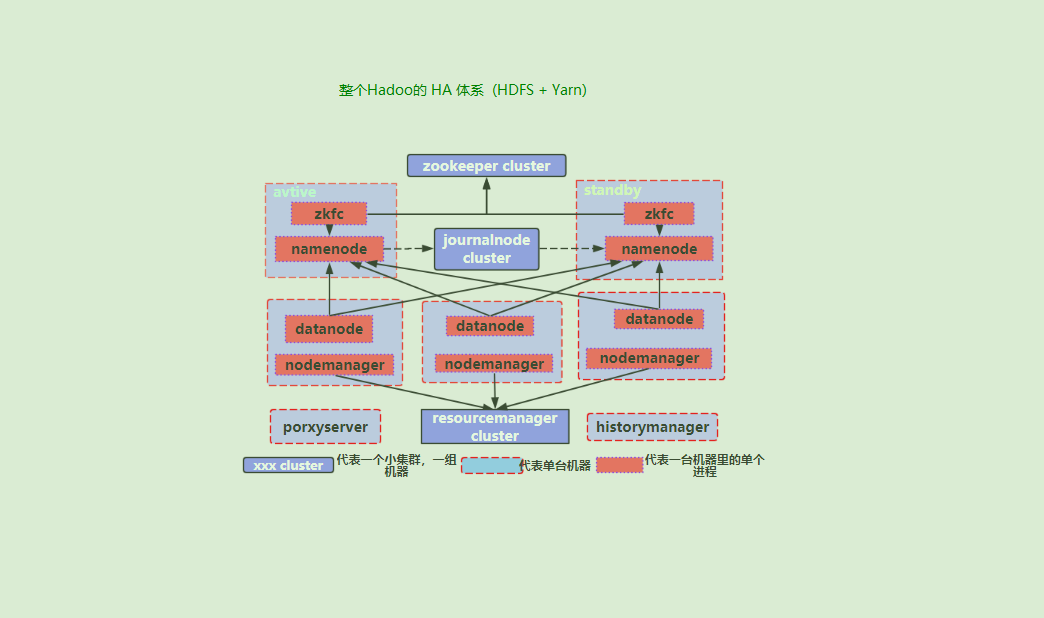
到这差不多简单的HA原理和结构就了解了, 但是这还没有涉及任何的细节和衍生的思考, 详细的文章可以参考文尾的2, 3篇文章, 写的挺不错, 后续看到HA相关的我再单独学习.
0x01. 实际部署
JN和ZK一般复用一台节点, 至少取3台, 那我们可以在之前的基础上, 再补充4台机器 (Yarn相关的进程我们就不再启动了, 去掉Manager相关). 当然如果机器不够, 也可以把JN或ZK放在数据节点, 或者和主节点(NN)共用. 为了清晰和符合生产环境, 就采用相对分离的做法.
| 节点IP | 功能(进程) | 备注 |
|---|---|---|
| 10.162.94.85 | NameNode1, ZKFK | 主节点 |
| 10.162.94.75 | NameNode2, ZKFK | 备用主节点 |
| 10.162.94.86 | DataNode | 数据节点1 |
| 10.162.94.87 | DataNode | 数据节点2 |
| 10.162.98.38 | Zookeeper, JournalNode | HA节点1 |
| 10.162.98.39 | Zookeeper, JournalNode | HA节点2 |
| 10.162.98.40 | Zookeeper, JournalNode | HA节点3 |
A. HDFS配置文件
然后主要是来在原有基础上修改之前的配置文件, 不必要的配置暂时不设置:
core-site.xml
1
2
3
4
5
6
7
8
9
10<property>
<name>fs.defaultFS</name>
<!--名字与hdfs.site中的nameservices一致-->
<value>hdfs://HAcluster</value>
</property>
<!--配置ZK地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>10.162.98.38:2181,10.162.98.39:2181,10.162.98.40:2181</value>
</property>hdfs-site.xml (主要)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56<!--HA-Start-->
<property>
<name>dfs.nameservices</name>
<!--名字可以随意取, 但是要保证后面配置一致,默认是mycluster-->
<value>HAcluster</value>
</property>
<property>
<!--HA集群的别名和通信端口-->
<name>dfs.ha.namenodes.HAcluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.HAcluster.nn1</name>
<value>10.162.94.85:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.HAcluster.nn2</name>
<value>10.162.94.75:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.HAcluster.nn1</name>
<value>10.162.94.85:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.HAcluster.nn2</name>
<value>10.162.94.75:9870</value>
</property>
<property>
<!--配置3个JN的地址-->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://10.162.98.38:8485;10.162.98.39:8485;10.162.98.40:8485/HAcluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.HAcluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<!-- 配置隔离机制,ssh到当前master并杀死它防止脑裂(多主)-->
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/${user.name}/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/${user.name}/hadoop/journal</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--HA-End-->
然后把修改后的hadoop3.1.2 包分发到新的Master02机和三台HA机器.
B. Zookeeper
这里主要就是安装启动ZK(3.5.5最新稳定版), 步骤简单, 3步就搞定了 (尽量多用批量分发)
1 | # 1.下载解压 |
C. 启动HA
这里我们需要先在三个HA节点启动JN, 然后再新的master备用节点使用standby指令
1 | # HA三台机器分别 |
这样如果顺利的话, HDFS的HA就完成了, 其实过程上看起来是比较简单的, 如果分发得当(配置hostname/ssh免密)会更快. 关键还是在于理解HA的结构和背后的考量, 以后再细看了.