看完Namenode端 的两种错误恢复处理, 也就是pipeline恢复 和租约恢复 过程后, 最后再来看看Datanode端的对应处理, 同样也分成两个大块
文档图待补…
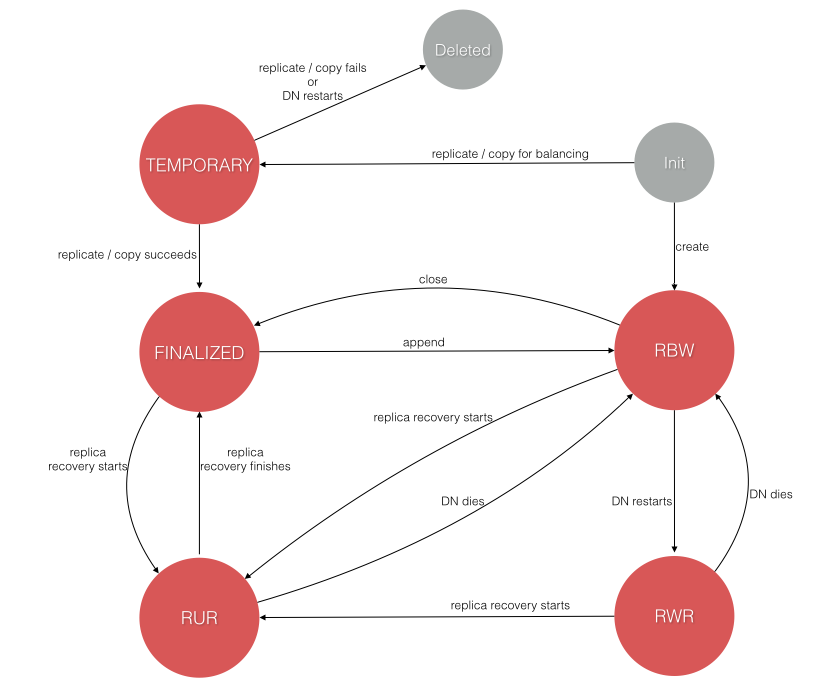
0x00. 概念 从这里起, Datanode端会引入一个重要的成员FsDataSetImpl, 它功能许多, 今天我们接触的就是它负责管理DN副本块 的功能 (CURD), 而不管是客户端触发的错误恢复, 还是NN端触发的租约恢复, 具体的实现代码也都在它这, 在学习它们之前, 先来看看之后可能会经常看到的几个副本块的状态转变 (原图应该是Cloudera官方?)
几个状态对应的含义在之前的普通写流程NN篇 已经说过, 图上设计的操作比较繁杂, 可以先只看和写/追加写/错误恢复 相关的几个, 其他以后再说.
0x01. Pipeline recovery 这里接的是之前主要在Client端写/追加写异常 在Datanode端的处理, 可以回顾一下串联起来.
从Client端做错误恢复的代码来看, 如果不添加新的DN, 似乎跟DN的关系并不大, 只是把异常DN剔除, 然后重建pipeline, 也没有在DN的writeBlock的主流程里看到和错误恢复直接相关的地方, 但是仔细想一下, 每次错误恢复重建pipeline后, 块的时间戳 和长度 都可能更新, 那就有两个核心问题:
之前在DN处于写入状态(RBW)的块副本会怎么处理呢?
之前的线程在处理旧块, 怎么切换到新创建的块副本上呢?
在讨论不同的异常情况之前, 先来看一个关键前置 , DN在发现异常时会如何处理错误.
0. responder 线程处理异常情况 这里补充说的是之前说DN写入时没有具体讲的, 接收下游响应ack并转发 上游的responder线程的细节, 但它是影响到我们错误恢复的关键点, 如下我列举了3DN情况下不同的DN异常的处理方式:
graph LR
subgraph DN3异常
e2(DN2标记DN3错误) --转发--> h(DN1标记自己后转发)
end
subgraph DN2异常
g(DN1标记DN2错误, 忽略DN3)
end
subgraph DN1异常
b(pipeline) --> c{发现其它错误DN?} --Yes--> d3(先处理已知错误DN)
c --No--> d4(剔除DN1)
end
h --转发--> a(client)
g --转发--> a
a--写失败--> b
然后有了整体认识, 再来看看细节上是怎么做的, 比如DN2异常, 怎么忽略DN3的呢? 如果还有DN4…DNn, 该怎么忽略呢? 有两个关键的参数, 单独说明一下:
ack.replies (响应ack的数目)bytesAcked (DN已ack的字节数)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 private void sendAckUpstreamUnprotected (params...) { final int [] replies; if (ack == null ) { replies = new int [] { myHeader }; } else if (mirrorError) { int h = PipelineAck.combineHeader(datanode.getECN(), Status.SUCCESS); int h1 = PipelineAck.combineHeader(datanode.getECN(), Status.ERROR); replies = new int [] {h, h1}; } else { short ackLen = (type == LAST_IN_PIPELINE ? 0 : ack.getNumOfReplies()); replies = new int [ackLen + 1 ]; replies[0 ] = myHeader; for (int i = 0 ; i < ackLen; ++i) { replies[i + 1 ] = ack.getHeaderFlag(i); } if (ackLen > 0 && PipelineAck.getStatusFromHeader(replies[1 ]) == ERROR_CHECKSUM) throw new IOException ("down streams reported the data sent by this thread is corrupt" ); } PipelineAck replyAck = new PipelineAck (seqno, replies, totalAckTimeNanos); if (replyAck.isSuccess() && offsetInBlock > replicaInfo.getBytesAcked()) { replicaInfo.setBytesAcked(offsetInBlock); } replyAck.write(upstreamOut); upstreamOut.flush(); Status myStatus = PipelineAck.getStatusFromHeader(myHeader); if (myStatus == Status.ERROR_CHECKSUM) throw new IOException ("checksum error in received data." ); } public PipelineAck.ECN getECN () { if (!pipelineSupportECN)return PipelineAck.ECN.DISABLED; double load = ManagementFactory.getOperatingSystemMXBean().getSystemLoadAverage(); return load > NUM_CORES * 1.5 ? CONGESTED : SUPPORTED; }
看完DN端responder线程做的事之后, 再来**”总-分”的看看DN端到底是如何 感知Client端的错误恢复请求, 并 做了什么**操作.
1. DN响应Client端恢复请求 DN虽然没在DataXceiver的主流程里进行明显错误恢复的判断, 但是它把这个过程放在了BlockReceiver 初始化 的时候, 回顾一下DN处理客户端发送Sender.writeBlock后, 它会先初始化一个BlockReceiver对象作为之后主要读取packet的载体, 之前并没有细看它的初始化方法, 这次就来看看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 BlockReceiver(params...) { try { this .isTransfer = stage == TRANSFER_RBW || stage == TRANSFER_FINALIZED; packetReceiver = new PacketReceiver (false ); if (isDatanode) { replicaHandler = datanode.data.createTemporary(params..); } else { switch (stage) { case PIPELINE_SETUP_CREATE: replicaHandler = datanode.data.createRbw(params..); datanode.notifyNamenodeReceivingBlock(params..); break ; case PIPELINE_SETUP_STREAMING_RECOVERY: replicaHandler = datanode.data.recoverRbw(block, newGs, minBytesRcvd, maxBytesRcvd); block.setGenerationStamp(newGs); break ; case PIPELINE_SETUP_APPEND: replicaHandler = datanode.data.append(block, newGs, minBytesRcvd); block.setGenerationStamp(newGs); datanode.notifyNamenodeReceivingBlock(params..); break ; case PIPELINE_SETUP_APPEND_RECOVERY: replicaHandler = datanode.data.recoverAppend(block, newGs, minBytesRcvd); block.setGenerationStamp(newGs); datanode.notifyNamenodeReceivingBlock(params..); break ; case TRANSFER_RBW: case TRANSFER_FINALIZED: replicaHandler = datanode.data.createTemporary(params..); break ; default : throw new IOException ("Unsupported stage xx" ); } } replicaInfo = replicaHandler.getReplica(); final boolean isCreate = isDatanode || isTransfer || stage == PIPELINE_SETUP_CREATE; streams = replicaInfo.createStreams(isCreate, requestedChecksum); } values()[ordinal() | 1 ]
我们需要关注的是recoverRbw和recoverAppend . 先看看最常见的RBW恢复, 首先想清楚什么情况下需要块恢复, 块恢复需要做哪些事:
客户端进入异常恢复后, 它会剔除掉错误的DN, 然后用剩下的DN重新去创建一次pipeline, 此时会携带一个新的块时间戳 (比旧的大)和客户端记录的文件长度
DN需要停止原有的工作线程, 并给新的pipeline开启工作线程
如果DN写盘的数据比Acked数据大, 需要剔除这部分数据, 重新计算校验, 最后更新block的时间戳和长度信息.
2. 写入中的副本恢复(Streaming) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 @Override public ReplicaHandler recoverRbw (params..) { while (true ) { try { try (AutoCloseableLock lock = datasetLock.acquire()) { ReplicaInfo replicaInfo = getReplicaInfo(b.getBlockPoolId(), b.getBlockId()); if (replicaInfo.getState() != ReplicaState.RBW) throw new ReplicaNotFoundException ("xx" ); ReplicaInPipeline rbw = (ReplicaInPipeline)replicaInfo; if (!rbw.attemptToSetWriter(null , Thread.currentThread())) throw new MustStopExistingWriter (rbw); return recoverRbwImpl(rbw, b, newGS, minBytesRcvd, maxBytesRcvd); } } catch (MustStopExistingWriter e) { e.getReplicaInPipeline().stopWriter(xx); } } } private ReplicaHandler recoverRbwImpl (params...) { try (AutoCloseableLock lock = datasetLock.acquire()) { long oldGS = rbw.getGenerationStamp(); if (oldGS < b.getGenerationStamp() || oldGS > newGS) throw new ReplicaNotFoundException ("GS range should be [a,b]" ); long bytesAcked = rbw.getBytesAcked(); long numBytes = rbw.getNumBytes(); if (bytesAcked < minBytesRcvd || numBytes > maxBytesRcvd) throw new ReplicaNotFoundException ("length range should be [min, max]" ); long bytesOnDisk = rbw.getBytesOnDisk(); long blockDataLength = rbw.getReplicaInfo().getBlockDataLength(); if (bytesOnDisk != blockDataLength) { bytesOnDisk = blockDataLength; rbw.setLastChecksumAndDataLen(bytesOnDisk, null ); } if (bytesOnDisk < bytesAcked) throw new ReplicaNotFoundException ("Fewer bytesOnDisk than acked xx" ); FsVolumeReference ref = rbw.getReplicaInfo().getVolume().obtainReference(); try { if (bytesOnDisk > bytesAcked) { rbw.getReplicaInfo().truncateBlock(bytesAcked); rbw.setNumBytes(bytesAcked); rbw.setLastChecksumAndDataLen(bytesAcked, null ); } rbw.getReplicaInfo().bumpReplicaGS(newGS); } catch (IOException e) { IOUtils.cleanup(null , ref); throw e; } return new ReplicaHandler (rbw, ref); } }
来看看如何通过truncateBlock 方法删掉多的数据的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public static void truncateBlock (params...) { if (newlen == oldlen) return ; if (newlen > oldlen) throw new IOException ("Can't truncate bigger len" ); final FileInputStream fis = fileIoProvider.getFileInputStream(volume, metaFile); DataChecksum dcs = BlockMetadataHeader.readHeader(fis).getChecksum(); int checksumsize = dcs.getChecksumSize(); int bpc = dcs.getBytesPerChecksum(); long n = (newlen - 1 )/bpc + 1 ; long newmetalen = BlockMetadataHeader.getHeaderSize() + n*checksumsize; long lastchunkoffset = (n - 1 )*bpc; int lastchunksize = (int )(newlen - lastchunkoffset); byte [] b = new byte [Math.max(lastchunksize, checksumsize)]; try (RandomAccessFile blockRAF = fileIoProvider.getRandomAccessFile( volume, blockFile, "rw" )) { blockRAF.setLength(newlen); blockRAF.seek(lastchunkoffset); blockRAF.readFully(b, 0 , lastchunksize); } dcs.update(b, 0 , lastchunksize); dcs.writeValue(b, 0 , false ); try (RandomAccessFile metaRAF = fileIoProvider.getRandomAccessFile( volume, metaFile, "rw" )) { metaRAF.setLength(newmetalen); metaRAF.seek(newmetalen - checksumsize); metaRAF.write(b, 0 , checksumsize); } }
3. 发空尾包时的错误恢复(Close) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 @Override public Replica recoverClose (ExtendedBlock b, long newGS, long expectedBlockLen) { while (true ) { ReplicaInfo replicaInfo = recoverCheck(b, newGS, expectedBlockLen); replicaInfo.bumpReplicaGS(newGS); if (replicaInfo.getState() == ReplicaState.RBW) finalizeReplica(b.getBlockPoolId(), replicaInfo); return replicaInfo; } catch (MustStopExistingWriter e) { e.getReplicaInPipeline().stopWriter(xx); }}} private ReplicaInfo recoverCheck (ExtendedBlock b, long newGS, long expectedBlockLen) { ReplicaInfo replicaInfo = getReplicaInfo(b.getBlockPoolId(), b.getBlockId()); if (replicaInfo.getState() != FINALIZED && replicaInfo.getState() != RBW) throw new ReplicaNotFoundException (xx); long oldGS = replicaInfo.getGenerationStamp(); if (oldGS < b.getGenerationStamp() || oldGS > newGS) throw new ReplicaNotFoundException ("Expected GS range is [a, b]" ); long replicaLen = replicaInfo.getNumBytes(); if (replicaInfo.getState() == RBW) { ReplicaInPipeline rbw = (ReplicaInPipeline) replicaInfo; if (!rbw.attemptToSetWriter(null , Thread.currentThread())) throw new MustStopExistingWriter (rbw); if (replicaLen != rbw.getBytesOnDisk() || replicaLen != rbw.getBytesAcked()) throw new ReplicaAlreadyExistsException ("xx" ); } if (replicaLen != expectedBlockLen) throw new IOException ("Corrupted replica with a length xx); return replicaInfo; }
recoverAppend 与 recoverClose + recoverRbw 的内容相似, 是追加写异常 的单独分类, 就先不再单说了, append出错后重建pipeline也会保证所有DN副本一致 .
0x02. Block recovery 再说明一下, 这里块恢复(Block Recovery)的意思, 是特指 的租约恢复 触发的块恢复操作 (为了和pipeline-recovery在DN端区分开)
在这里引入了上一篇NN篇 说过的主恢复DN (Primary Datanode), 并由它来做中介统一所有DN上的块信息, 然后汇报给NN恢复结果, 它主要就是两个DN间的RPC调用, 整体流程参考之前NN的时序图, 在DN这边做的步骤主要4步 :
主DN的块恢复线程接受到了NN的请求, 开始依次执行恢复操作
主DN向其它DN发送RPC询问副本块的信息 (initReplicaRecovery)
主DN算出一个最佳副本块信息
主DN向所有DN同步 (updateReplicaUnderRecovery), 最后汇报NN恢复结果
下面几个核心步骤都需要补充流程图….
1. recover 块恢复的过程在Namenode发送指令给主DN后, 在DN专用恢复的线程中触发, 它会一直调用recover()方法, 统计其他DN副本信息的操作, 并尝试同步副本信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 protected void recover () throws IOException { List<BlockRecord> syncList = new ArrayList <>(locs.length); int errorCount = 0 ; int candidateReplicaCnt = 0 ; for (DatanodeID id : locs) { try { DatanodeID bpReg = getDatanodeID(bpid); InterDatanodeProtocol proxyDN = bpReg.equals(id)? datanode: DataNode.createInterDataNodeProtocolProxy(id, conf, dnConf.socketTimeout, dnConf.connectToDnViaHostname); ReplicaRecoveryInfo info = callInitReplicaRecovery(proxyDN, rBlock); if (info != null && info.getGenerationStamp() >= block.getGenerationStamp() && info.getNumBytes() > 0 ) { ++candidateReplicaCnt; if (info.getOriginalReplicaState().getValue() <= RWR.getValue()) syncList.add(new BlockRecord (id, proxyDN, info)); } } } catch (RecoveryInProgressException ripE) { return ; } catch (IOException e) { ++errorCount; } } if (errorCount == locs.length) throw new IOException ("All datanodes failed xx" ); if (candidateReplicaCnt > 0 && syncList.isEmpty()) throw new IOException ("but none is in RWRor better stat); // 执行选择副本和同步, 汇报的操作 syncBlock(syncList); }
2. initReplicaRecovery 上面提到每个DN会返回主DN一个ReplicaRecoveryInfo对象, 记录副本块的信息, 核心代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 static ReplicaRecoveryInfo initReplicaRecoveryImpl (params..., long recoveryId) { final ReplicaInfo replica = map.get(bpid, block.getBlockId()); if (replica == null ) return null ; if (replica.getState() == TEMPORARY || replica.getState() == RBW) { final ReplicaInPipeline rip = (ReplicaInPipeline)replica; if (!rip.attemptToSetWriter(null , Thread.currentThread())) { throw new MustStopExistingWriter (rip); } if (replica.getBytesOnDisk() < replica.getVisibleLength()) throw new IOException ("getBytesOnDisk() < getVisibleLength()" ); checkReplicaFiles(replica); } if (replica.getGenerationStamp() < block.getGenerationStamp()) throw new IOException ("replica.getGenerationStamp() < block.getGenerationStamp()" ); if (replica.getGenerationStamp() >= recoveryId) throw new IOException ("newGS > oldGS" ); final ReplicaInfo rur; if (replica.getState() == ReplicaState.RUR) { rur = replica; if (rur.getRecoveryID() >= recoveryId) { throw new RecoveryInProgressException ( "rur.getRecoveryID() >= recoveryId = " + recoveryId + ", block=" + block + ", rur=" + rur); } final long oldRecoveryID = rur.getRecoveryID(); rur.setRecoveryID(recoveryId); } else { rur = new ReplicaBuilder (ReplicaState.RUR).from(replica).setRecoveryId(recoveryId).build(); map.add(bpid, rur); if (replica.getState() == TEMPORARY || replica.getState() == RBW) ((ReplicaInPipeline) replica).releaseAllBytesReserved(); } return rur.createInfo(); }
这个方法相对简单. 下面接着看看主DN收集了信息之后的判断
3. syncBlock 主恢复DN在接受了其他DN返回的副本信息之后, 会根据副本状态选取一个最佳值, 最后统一发送给每个DN, 然后给NN汇报结果, 这个是syncBlock中进行, 在整个块恢复过程中, 不符合同步条件的DN副本会被忽略, 之后这些DN上的副本时间戳与NN不一致, 最终会被NN给清掉.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 void syncBlock (List<BlockRecord> syncList) { DatanodeProtocolClientSideTranslatorPB nn = getActiveNamenodeForBP(block.getBlockPoolId()); boolean isTruncateRecovery = rBlock.getNewBlock() != null ; long blockId = (isTruncateRecovery) ? rBlock.getNewBlock().getBlockId() : block.getBlockId(); if (syncList.isEmpty()) { nn.commitBlockSynchronization(.., 0 , true , true , DatanodeID.EMPTY_ARRAY, null ); return ; } ReplicaState bestState = ReplicaState.RWR; long finalizedLength = -1 ; for (BlockRecord r : syncList) { assert r.rInfo.getNumBytes() > 0 : "zero length replica" ; ReplicaState rState = r.rInfo.getOriginalReplicaState(); if (rState.getValue() < bestState.getValue()) bestState = rState; if (rState == ReplicaState.FINALIZED) { if (finalizedLength > 0 && finalizedLength != r.rInfo.getNumBytes()) throw new IOException ("Inconsistent size of finalized replicas." ); finalizedLength = r.rInfo.getNumBytes(); } } List<BlockRecord> participatingList = new ArrayList <>(); final ExtendedBlock newBlock = new ExtendedBlock (bpid, blockId, -1 , recoveryId); switch (bestState) { case FINALIZED: for (BlockRecord r : syncList) { ReplicaState rState = r.rInfo.getOriginalReplicaState(); if (rState == FINALIZED || rState == RBW && r.rInfo.getNumBytes() == finalizedLength) { participatingList.add(r); } } newBlock.setNumBytes(finalizedLength); break ; case RBW: case RWR: long minLength = Long.MAX_VALUE; for (BlockRecord r : syncList) { ReplicaState rState = r.rInfo.getOriginalReplicaState(); if (rState == bestState) { minLength = Math.min(minLength, r.rInfo.getNumBytes()); participatingList.add(r); } } newBlock.setNumBytes(minLength); break ; case RUR: case TEMPORARY: assert false : "bad replica state: " + bestState; default : break ; } if (isTruncateRecovery) newBlock.setNumBytes(rBlock.getNewBlock().getNumBytes()); List<DatanodeID> failedList = new ArrayList <>(); final List<BlockRecord> successList = new ArrayList <>(); for (BlockRecord r : participatingList) { try { r.updateReplicaUnderRecovery(bpid, recoveryId, blockId, newBlock.getNumBytes()); successList.add(r); } catch (IOException e) { failedList.add(r.id); } } if (successList.isEmpty()) throw new IOException ("the following datanodes failed:" + failedList); final DatanodeID[] datanodes = new DatanodeID [successList.size()]; final String[] storages = new String [datanodes.length]; for (int i = 0 ; i < datanodes.length; i++) { final BlockRecord r = successList.get(i); datanodes[i] = r.id; storages[i] = r.storageID; } nn.commitBlockSynchronization(datanodes, newBlockParams...); }
4. updateReplicaUnderRecovery 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 @Override public String updateReplicaUnderRecovery (params...) { final Replica r = data.updateReplicaUnderRecovery(newBlockInfo...); ExtendedBlock newBlock = new ExtendedBlock (oldBlock); newBlock.setGenerationStamp(recoveryId); newBlock.setBlockId(newBlockId); newBlock.setNumBytes(newLength); final String storageID = r.getStorageUuid(); notifyNamenodeReceivedBlock(newBlock, null , storageID, r.isOnTransientStorage()); return storageID; } @Override public Replica updateReplicaUnderRecovery (params..) { try (AutoCloseableLock lock = datasetLock.acquire()) { final String bpid = oldBlock.getBlockPoolId(); final ReplicaInfo replica = volumeMap.get(bpid, oldBlock.getBlockId()); if (replica == null ) throw new ReplicaNotFoundException (oldBlock); if (replica.getState() != ReplicaState.RUR) throw new IOException ("must be RUR" ); if (replica.getBytesOnDisk() != oldBlock.getNumBytes()) throw new IOException ("xx" ); checkReplicaFiles(replica); final ReplicaInfo finalized = updateReplicaUnderRecovery(params...); boolean copyTruncate = newBlockId != oldBlock.getBlockId(); if (!copyTruncate) { assert finalized.getBlockId() == oldBlock.getBlockId() && finalized.getGenerationStamp() == recoveryId && finalized.getNumBytes() == newlength : "Replica information mismatched: oldBlock=" + oldBlock + ", recoveryId=" + recoveryId + ", newlength=" + newlength + ", newBlockId=" + newBlockId + ", finalized=" + finalized; } else { assert finalized.getBlockId() == oldBlock.getBlockId() && finalized.getGenerationStamp() == oldBlock.getGenerationStamp() && finalized.getNumBytes() == oldBlock.getNumBytes() : "Finalized and old information mismatched: oldBlock=" + oldBlock + ", genStamp=" + oldBlock.getGenerationStamp() + ", len=" + oldBlock.getNumBytes() + ", finalized=" + finalized; } checkReplicaFiles(finalized); return finalized; } } private ReplicaInfo updateReplicaUnderRecovery (newBlockk) { if (rur.getRecoveryID() != recoveryId) throw new IOException ("xx" ); boolean copyOnTruncate = newBlockId > 0L && rur.getBlockId() != newBlockId; if (!copyOnTruncate) rur.bumpReplicaGS(recoveryId); if (rur.getNumBytes() < newlength) throw new IOException ("rur.getNumBytes() < newlength" ); if (rur.getNumBytes() > newlength) { if (!copyOnTruncate) { rur.breakHardLinksIfNeeded(); rur.truncateBlock(newlength); rur.setNumBytes(newlength); } else { FsVolumeImpl volume = (FsVolumeImpl) rur.getVolume(); ReplicaInPipeline newReplicaInfo = volume.updateRURCopyOnTruncate( rur, bpid, newBlockId, recoveryId, newlength); if (newReplicaInfo.getState() != ReplicaState.RBW) { throw new IOException ("Append on block " + rur.getBlockId() + " returned a replica of state " + newReplicaInfo.getState() + "; expected RBW" ); } newReplicaInfo.setNumBytes(newlength); volumeMap.add(bpid, newReplicaInfo.getReplicaInfo()); finalizeReplica(bpid, newReplicaInfo.getReplicaInfo()); } } return finalizeReplica(bpid, rur); }
租约恢复在DN这里的部分还需要细化一下.
0x03. Transfer Block 之前在Client的错误恢复 中提到过, 如果满足条件, Client可能会再申请一个新的DN 替换异常的DN, 把副本同步 到新的DN上
注意: 整个流程是Client通过Sender发起transferBlock()请求, 然后建立一个临时的pipeline去单独做这次数据同步操作, 它同样也属于pipeline recovery 的范畴, 只不过这个过程并非必要 , 且主要操作在DN端, 所以单独从pipeline_recovery拆出来描述.
这里流程图同样待补… (细节也待梳理)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 @Override public void transferBlock (params...) { previousOpClientName = clientName; final DataOutputStream out = new DataOutputStream (getOutputStream()); checkAccess(out, true , blk, blockToken, Op.TRANSFER_BLOCK, BlockTokenIdentifier.AccessMode.COPY, targetStorageTypes, targetStorageIds); try { datanode.transferReplicaForPipelineRecovery(params...); writeResponse(Status.SUCCESS, null , out); } catch (IOException ioe) { incrDatanodeNetworkErrors(); throw ioe; } finally { IOUtils.closeStream(out); } } void transferReplicaForPipelineRecovery (params...) { final long storedGS; final long visible; final BlockConstructionStage stage; try (AutoCloseableLock lock = data.acquireDatasetLock()) { Block storedBlock = data.getStoredBlock(b.getBlockPoolId(),b.getBlockId()); if (null == storedBlock) throw new IOException (b + " not found in datanode." ); storedGS = storedBlock.getGenerationStamp(); if (storedGS < b.getGenerationStamp()) throw new IOException ("storedGS < b.getGenerationStamp(), b=" + b); b.setGenerationStamp(storedGS); if (data.isValidRbw(b)) { stage = BlockConstructionStage.TRANSFER_RBW; } else if (data.isValidBlock(b)) { stage = BlockConstructionStage.TRANSFER_FINALIZED; } else { final String r = data.getReplicaString(b.getBlockPoolId(), b.getBlockId()); throw new IOException (b + " is neither a RBW nor a Finalized, r=" + r); } visible = data.getReplicaVisibleLength(b); } b.setNumBytes(visible); if (targets.length > 0 ) { Daemon daemon = new Daemon (threadGroup, new DataTransfer (params...)); daemon.start(); try { daemon.join(); } catch (InterruptedException e) { throw new IOException ("Pipeline recovery for x is interrupted." , e); } } }
下面来看看DataTransfer守护进程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 @Override public void run () { incrementXmitsInProgress(); Socket sock = null ; DataOutputStream out = null ; DataInputStream in = null ; BlockSender blockSender = null ; final boolean isClient = clientname.length() > 0 ; try { final String dnAddr = targets[0 ].getXferAddr(connectToDnViaHostname); InetSocketAddress curTarget = NetUtils.createSocketAddr(dnAddr); sock = newSocket(); NetUtils.connect(sock, curTarget, dnConf.socketTimeout); sock.setTcpNoDelay(dnConf.getDataTransferServerTcpNoDelay()); sock.setSoTimeout(targets.length * dnConf.socketTimeout); Token<BlockTokenIdentifier> accessToken = getBlockAccessToken(b, EnumSet.of(BlockTokenIdentifier.AccessMode.WRITE), targetStorageTypes, targetStorageIds); long writeTimeout = dnConf.socketWriteTimeout + HdfsConstants.WRITE_TIMEOUT_EXTENSION * (targets.length-1 ); OutputStream unbufOut = NetUtils.getOutputStream(sock, writeTimeout); InputStream unbufIn = NetUtils.getInputStream(sock); DataEncryptionKeyFactory keyFactory = getDataEncryptionKeyFactoryForBlock(b); IOStreamPair saslStreams = saslClient.socketSend(sock, unbufOut, unbufIn, keyFactory, accessToken, bpReg); unbufOut = saslStreams.out; unbufIn = saslStreams.in; out = new DataOutputStream (new BufferedOutputStream (unbufOut, DFSUtilClient.getSmallBufferSize(getConf()))); in = new DataInputStream (unbufIn); blockSender = new BlockSender (b, 0 , b.getNumBytes(), false , false , true , DataNode.this , null , cachingStrategy); DatanodeInfo srcNode = new DatanodeInfoBuilder ().setNodeID(bpReg).build(); String storageId = targetStorageIds.length > 0 ? targetStorageIds[0 ] : null ; new Sender (out).writeBlock(b, targetStorageTypes[0 ], accessToken, clientname, targets, targetStorageTypes, srcNode, stage, 0 , 0 , 0 , 0 , blockSender.getChecksum(), cachingStrategy, false , false , null , storageId, targetStorageIds); blockSender.sendBlock(out, unbufOut, null ); if (isClient) { DNTransferAckProto closeAck = DNTransferAckProto.parseFrom(PBHelperClient.vintPrefixed(in)); if (closeAck.getStatus() != Status.SUCCESS) { if (closeAck.getStatus() == Status.ERROR_ACCESS_TOKEN) { throw new InvalidBlockTokenException ( "Got access token error for connect ack, targets=" + Arrays.asList(targets)); } else { throw new IOException ("Bad connect ack, targets=" + Arrays.asList(targets) + " status=" + closeAck.getStatus()); } } } else { metrics.incrBlocksReplicated(); } } catch (IOException ie) { if (ie instanceof InvalidChecksumSizeException) { LOG.info("Adding block: {} for scanning" , b); blockScanner.markSuspectBlock(data.getVolume(b).getStorageID(), b); } } finally { closeAll(blockSender, out, in, sock); } }
0x04. 疑问 1. 假设Client发了N个packet, 前N-1个正常ack, 第N个提示异常, 进入错误恢复, DN这边如何处理? 假设第一个DN接收N个Packet都成功, 并成功写入磁盘了, 但是第二个DN在接受第N个packet的时候超时, 此时进入错误恢复后, 客户端会重新发送第N个packet, 那第一个DN等于多写了一个Packet到磁盘上, 是会在错误恢复的时候删掉这个部分么? (没看到?) 还是不处理, 在Client重新发第N个packet时比较SeqNo 然后跳过?
正确结果是, 在客户端重建pipeline时, DN执行recoverRbw(). 此时ackLength是所有DN都成功的packet, 所以只要有packet在DN的ack是异常的, 那么上游DN虽然会先把此packet写入磁盘, 但是packetLength并不会增加, 在对比的时候, 就会剔除掉多写到磁盘的部分, 保证pipeline重建后, 所有DN的副本时间戳和长度保持一致, 并且接收packet也与Client保持一致. (详见response线程转发ack 给上游的代码)
2. 假设第二个DN挂了, 第三个DN不确定情况, 返回给Client的ack中, ack.reply长度是否为2? 如果是, 那应该在DN的response线程向上游转发的时候会判断, 如果下游DN挂了, 会直接把关键的mirrorError 参数置为true, 然后直接标记下游节点bad, 自己的是OK, 转发给上游, 不会管后续不确定的下游DN.
3. 租约恢复之主DN与NN的感知 (待确定) 租约恢复的完整流程中, 主要是依靠主DN 这个重要的中介者来统一其他DN, 并和NN进行通信的, 但是这个过程并不是阻塞的, 而是比较特别的通过一个心跳携带的指令, 主DN 汇报结果也是自己操作的, 那就有些问题了:
如果主DN接受到剩余DN中汇报同步失败的, 该如何处置?
如果DN这边统一失败了, 或者有异常, 告诉NN后会怎么办? 之前的文件租约被释放了么?
如果主DN没有, 或者没有及时给NN回复这个租约恢复的结果, NN怎么确定呢? (会等一段时间再去问么, 还是不管重新恢复?..)
参考资料:
HDFS3.1.2官方源码 Hadoop 2.X HDFS源码剖析-Chap.4.4.2 HDFS异常处理与恢复-cnblogs