janus项目开源出来是17年4月,前身是Titan.不管是图数据库,还是janus,诞生时间都挺短,那么主要学习肯定是先从阅读官方文档开始.JanusDoc 配合实际需要跟分析读源码+文档.
但是因janus的源码结合了很多其他的存储服务.所以单独写了很多接口,核心在它的core模块中. 由于代码结构也很庞大,所以我们不能从main函数开始读了… 先看最关键的实现.(比如schema,index,edge & vertex相关)
0x00.引言
官方介绍待续ing .先看schema的部分,以及相关的事务提交,回滚机制. 以及cassandra和es的对接口.着重搞清楚以下问题:
基于上次的janus入门 ,每个janus都对应一个schema,类似db的datebase(包含事务,索引,表,存储过程等.) 它本身的数据结构就是一个图. (什么图?看源码)
5.11更新: 在本文档基础上优化做了一个gitpitch的演示,因为md跟gitpitch之间的转换还不算很小.所以有些东西先在那上面加了.
0x01. 结构分析
虽然这次不从main函数开始看结构,但是基本的思路还是一致. 先看看maven依赖,看看核心的core模块的层级.然后看看这次要分析的schema相关的类.
1.maven依赖
因为总项目内容太多.我就只放idea-clean后的简版核心依赖模块,也就是常用模块:
1 | <modules> |
这样可以看出其实是一个一带多的模块方式,核心的模块提供接口,其他需要实现对接的模块各自实现.比较方便不同的团队一起合作吧. 每个module里面都有自己的maven依赖.然后我们通过maven分析直观看看janus-core模块的结构:
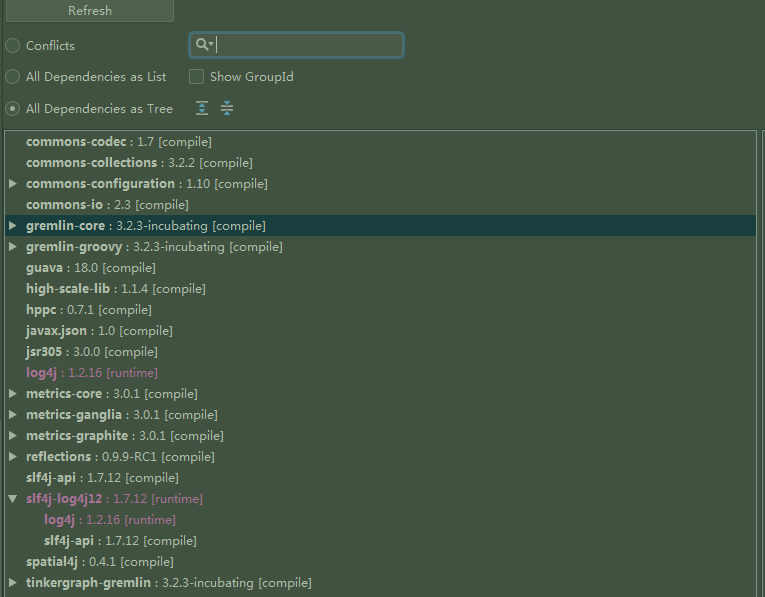
可以看出除了常见包,主要依赖 gremlin , groovy ,guava,metrics,tinkergraph .其中后面两个都不清楚为什么依赖还. tinkergraph 难道是tinkepop自己的图么.. 带着这些疑问再看源码把.
2.代码结构

如图可以看出,核心四大包 : (example就一个测试类,不单独提)
- core (其中包括schema子包)
- diskstorage (包括索引,ID策略等等)
- graphdb(这里也有个schema的子包,等下细看)
- util(公用的工具类)
所以先看core的schema包,然后再看graphdb的schema包.这是core包中schema下的类:
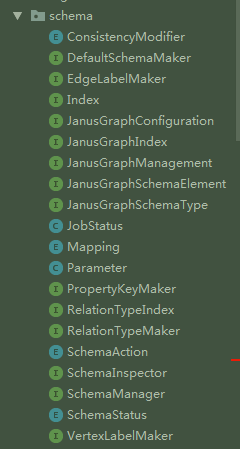
0x02. 源码分析
一共6个普通类(4个枚举). 然后剩下全是接口,那说明具体实现可能不在一起…如果一个个看结构太乱,沿着之前的数据导入的SchemaUtil来看. 有这几个主要的类影响创建Schema: JanusGraphManagement (包含IndexBuilder),SchemaInspector,SchemaManager,PropertyKeyMaker,Cardinality,Multiplicity
首先看最核心的JanusGraphManagement (jm),之前从数据导入分析的创建Schema主要就是创建property,创建index,创建label三个过程. 那就一个个来看. 先看看jm的依赖图: (可以发现SchemaInspector是幕后核心)
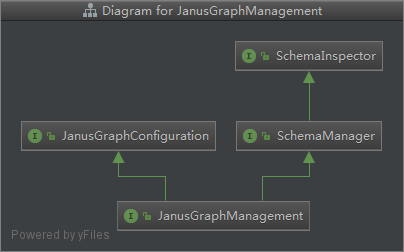
1.创建property
1 | //需要传入JM,String,Class,Cardinality,就是如果存在直接获取,不存在新建. |
首先getPropertyKey()方法是SchemaInspector接口中定义的,有三个实现(但是本质都是调的一个):
1 | //impl by StandardJanusGraphTx |
可以看到从StandardJanusGraphTx往上有很多的接口跟实现.. (当然既然继承了Blueprints,为什么又直接实现SchemaInspector?) 然后进一步可以发现,核心的创建schema的方法在这很多
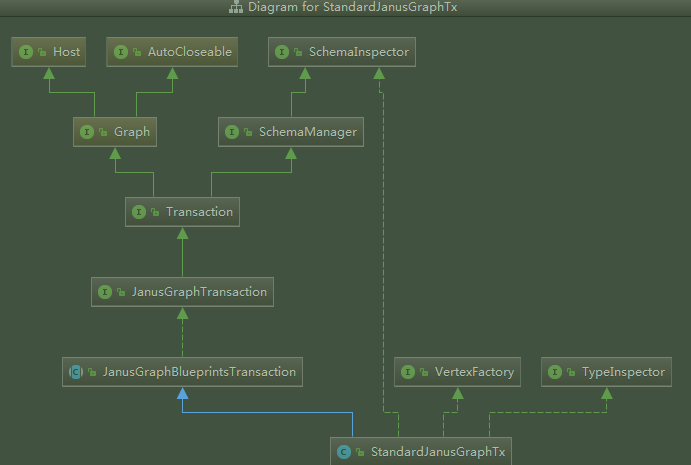
- 开头定义了内部数据结构 (包括顶点/索引缓存,ID池)
- 各种读写权限的检查方法
- 加工顶点的方法()
2.创建label
2.1顶点label
2.2边label
3.创建顶点/边
首先这有个重要的概念得先搞清楚 :创建顶点/边的label & 创建 顶点/边的区别跟关系.
如果我们把label理解为顶点/边的名字: 比如名为系统部的顶点A和名为存储组的顶点B之间有一个名为直属的边C, 那么系统部, 存储组, 直属 都是label. 而A,B,C这种虚拟的代词是顶点/边实体. 那有个问题,如果是这样的关系,那为什么不直接设置为一个特殊的属性(PK)呢? 带着这个疑问继续看代码.
首先抛开代码,我们自己设计如果要创建一个顶点对象,方法名是addVertex(),它需要什么入参,返回什么,需要做什么?
- 需要传入一个构建好的顶点对象vertex
- 返回添加后的状态,比如Y/N,或者返回这个顶点对象(如果接下来需要)
然后再看看源码的过程:
- 传入一个vertexID,传入一个vertexLabel. 返回一个JanusGraphVertex对象. (为什么只需要传入id & label?而不是传入顶点对象,接着看)
- 首先判断label是否为空,如果空, 给顶点一个默认label=”vertex” . 那这样就有个新的疑问,顶点名是不能重复的,如果给第一个顶点默认label叫
vertex,之后是不是再传入任何没有label的顶点,都会直接报错呢? (待确认) - 下面对顶点ID进行一系列的复合条件检查(非空不唯一,或存在多个空(意思就是我上面的疑问?)).通过之后创建一个StandardVertex对象,从ID池里产生一个临时顶点ID (这里引入了一个重要的类,IDManager.后面单独说)
- 下面
在生成了janus对象之后,创建用户Schema的整个步骤应该是: (围绕了核心的vertexID开始展开)
- 创建一个ID池,这个池子会被分成多个部分. 最重要的功能就是分配/回收vertexID.
- 创建了一个系统内部Schema,
4.创建index
IDManger类
从中可以看出,在janus的ID管理中,基本都是分为用户和系统两种区别对待.也包括一些特殊顶点(ttl,static?)
1 | /** 控制最核心的概念之一VertexID的生成和意义,每个位的参考注释如下 |
然后就有如下的例子:
- 用户Schema定义的顶点ID :
0 | count | partition | ID padding (if any) - 系统Schema定义的顶点ID:
0 | count | ID padding(没有分区)
assignID() 根据vertex不同类型分配不同vid
1 | private void assignID(InternalElement element, IDManager.VertexIDType vertexIDType) { |
5.提交(事务)
因为代码部分太多,也比较繁杂,所以还是上图了清晰版可点原图,原图也开源,欢迎大家可以自行修改补充优化.

0x03.测试实践
参考文章:
更新分割线:
Multiplicity(多样性)是一个比较重要的轴,围绕它有边的方向(Direction)以及Cardinality的转换.简单说Multiplicity就是给某条边的限定条件.
首先看看有哪几种限定条件: (默认设置是MULTI)
Multi: 两个顶点间的同名label可以有任意个
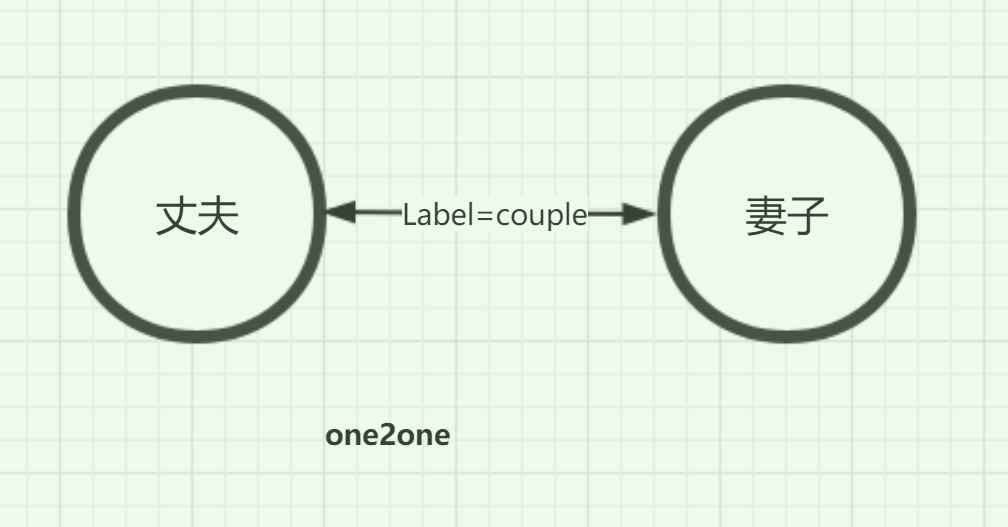
simple: 两个顶点间相同名的label只能有一个. 区别于one2one是simple可以有很多个不同名的label的 ?
many2one: 顶点最多只能有一个出边(outgoing edge)和任意个同名入边(incoming edge) one2many则与之相反.
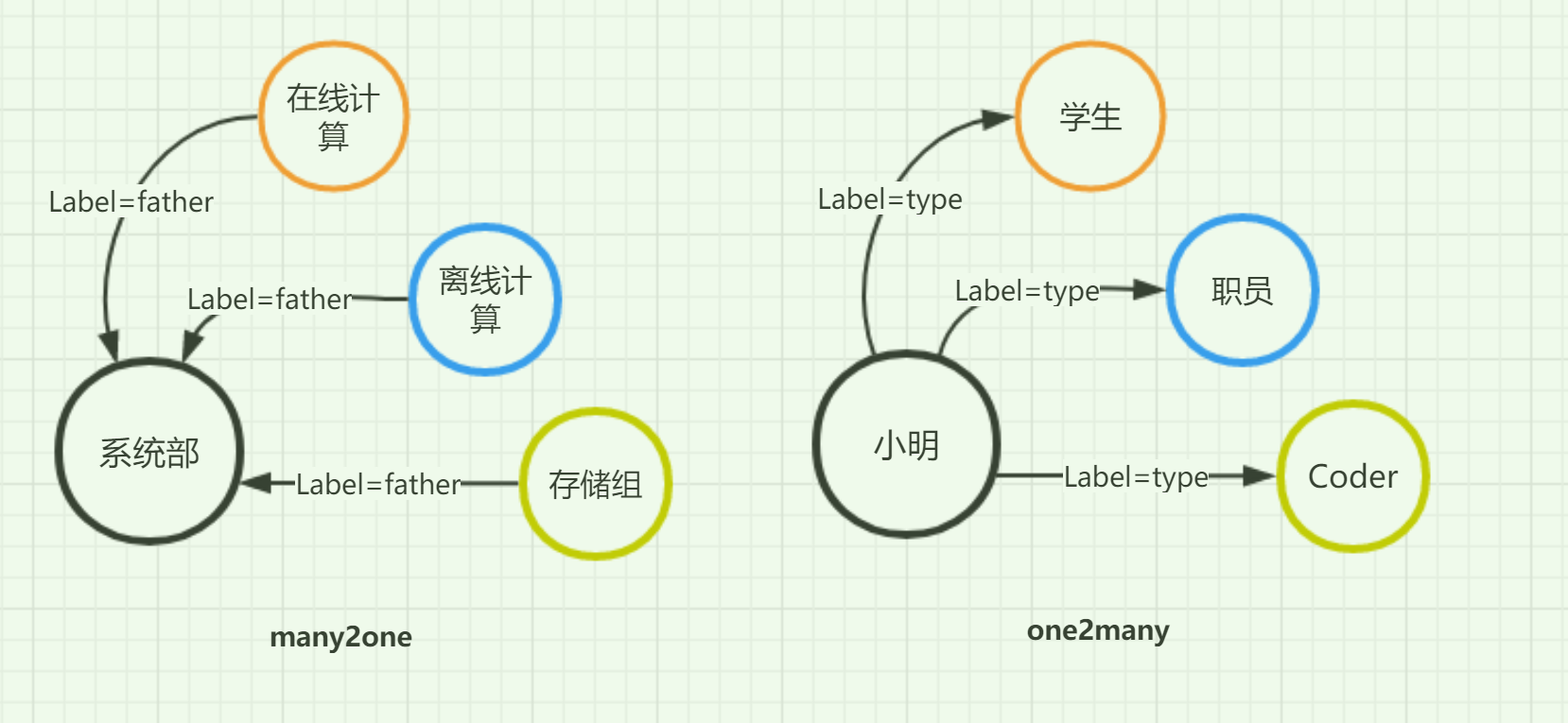
one2one: 在此label下仅能有两个顶点,有且仅有一出/入边
1 | //给个一句话的例子,假设我们已经有了janusManager对象,创建一条多对一的边做法 |
然后还可以知道Multiplicity和Cardinality之间是可以互相转换的,如下的方式:
- List : multi
- Set: simple
- Single: many2one (为什么?single是什么?某一个对象么.之后会说)
Cardinality,之前的Multiplicity是对边的标签限制,Direction是对边的方向限制,那么cd显然是对顶点的某种限制. 参数已经给了.
Janus/Titan有哪些待改进点(参考Nosql杂谈,链接待补)
问题1:顶点属性和边存储在一行中,读取时会相互影响性能
假设顶点有10个属性,出边和入边总共100个,则在该顶点的一行数据中,会有110列(除用户数据之外,还会有一些系统属性,此处忽略),那么查询该顶点的属性时相当于从110列中只取出10列,在效率上肯定慢于仅从10列中取10列数据,因为多扫描了一些无效数据。也就是说当点的出入度越大时,属性查询耗时将会越大,在扩线的最后一次查询点属性时,就会耗时越久。
问题2:边基于Immutable的存储设计, 属性查询和更新代价较大
从Janus的数据结构可以看出,边作为顶点中的一列存储,边的属性也全部存储在这一列中,那么更新其中某一个属性时,需要先获取整个边的数据,修改完成后再写回,效率较低。而且针对边的属性过滤,Titan的做法是将数据取回客户端,在客户端进行过滤。所以对于扩线场景,需要将所有的边取回客户端,然后再进行边的过滤,增加了网络传输的消耗。
问题3:支持多个后端存储其实是一把双刃剑
在Titan时期,后端就已经支持Cassandra、HBase、Berkeley DB和Immemory模式,到可Janus时期还增加了完全的BigTable结构支持,无疑大大提高了兼容性,但是这显然是有代价的,这需要在软件架构上增加一个可以适配多个存储的数据格式(StaticBuffer).无论是写入还是读取,数据都需要先转化成中间格式,带来了序列化和反序列化的一些性能损耗。当数据量比较小时,性能损耗可能还不是特别明显,但是当点和边到百万级别,这个损耗值相当可观。当顶点上升到十亿/百亿的时候,就大到惊人了.
问题4:Titan把后端存储当做黑盒,几乎纯Client端的实现
以HBase为例,Titan完全可以基于HBase深度定制一些功能,例如可以利用HBase的Coprocessor能力,将计算过程下推到HBase端,还可以定制查询过滤器,使得查询更加高效。但当前却完全未利用这些能力。
在提出了这些问题之后,事实上也是为Janus指明了关键的优化方向