在之前的云计算&分布式概述就说过, 分布式这个概念随着Google的三驾马车论文应声而出,其中有几个核心的概念. 之后会一一理清,今天说的是
map-reduce.尽量从多个角度去全面理解它
0x00.概念
Map_Reduce(简称mr)是大数据中可能是最常听见的一个词.先不说概念,来个网络图理解一下.
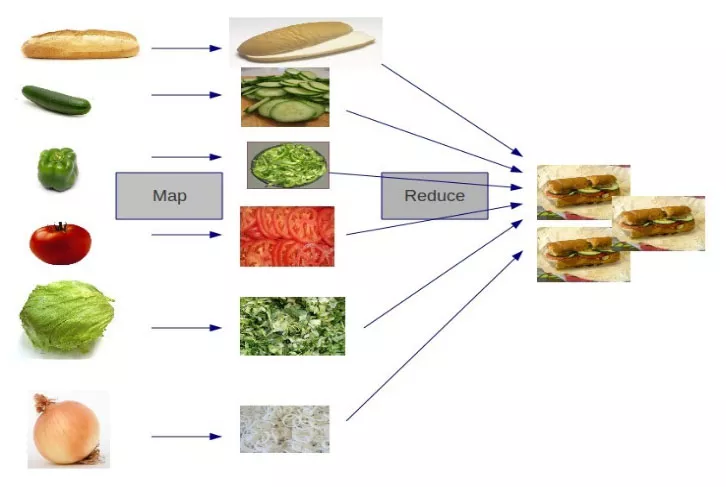
从这图,我直观的感觉就是两个. map做多个物品的拆分/打散, 然后reduce负责把它们加工整个(也就是拆&聚的过程). 这个理解对么? 接着再来看一个实际例子图:
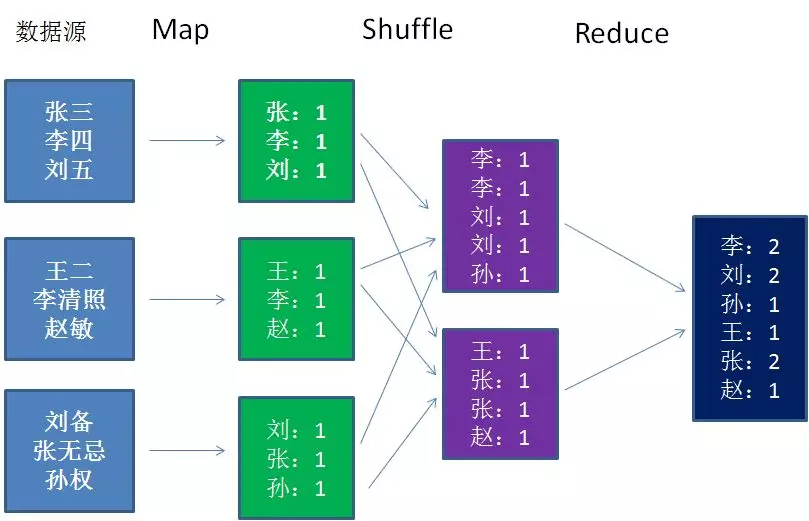
然后演化到实际的大数据生态中:
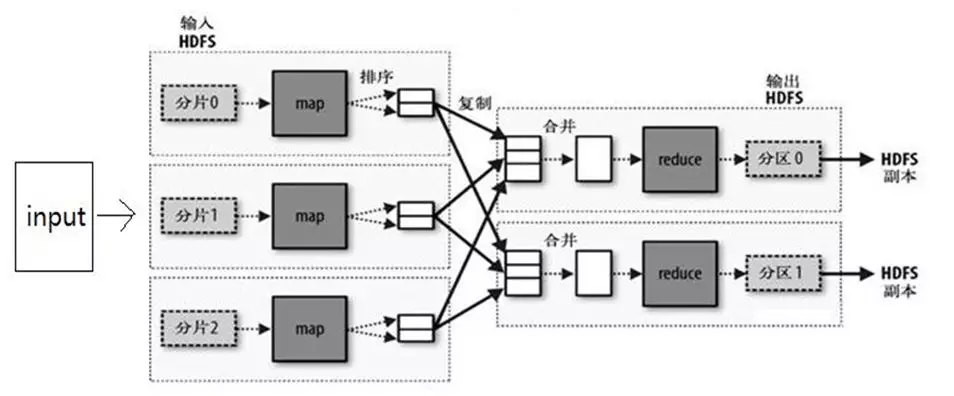
待继续更新,因为这里要结合一下实际编程中的使用和它后续的进阶Spark等…所以有时候就没单独抽时间写先.
0x01.函数式编程
之前一直就觉得整个Map-reduce , λ(lambda) ,和Stream(流式编程) 之间有很明显若隐若现的关系, 但是由于整个Big data 和PL的体系发展没明白, 所以一直都是零散的点学习. 直到后面补充了很多相关的历史和知识, 知道了PageRank 和搜索引擎的来源. 再结合参考文章中的data parallel 串联理解 , 才能真正比较好的理解MR. (还是得先理解一下FP)
待续… 之后拆分为单独的部分
0x02. MR Paper
大致清楚了MapReduce的参考, 也就是它的前世之后, 再来看看Google04年发的这篇论文, 下面内容基于已经读过大致文章, 然后说一下再怎么具体让自己更好的理解MR.
0x04. 调度
因为运行计算任务, 就像进程运转一样, 一定需要一个调度器(Scheduler), 所以一般看完计算模型本身, 也需要看看相关的调度原理和机制, 当然这是一个单独的篇章, 只是现在没空写, 就放一起, 之后再拆分.. 建议也是不局限于某个具体的系统, 而是从你见过的各种调度环节去对比思考. 这样看的会清晰很多.
- Linux调度 (单机, OS层面)
- Yarn调度 (分布式, 任务)
- Mesos (分布式, ?)
- Borg/K8s (分布式, 容器)
0x05. IO
这里主要讨论不同IO模型, 从是否同一时间发生来说:
- 同步
- 异步
此篇没有更新了, 建议大家参考文尾列的参考材料, 感觉就写的挺好了, 之后实践一下 MR, 光看效率很低.