这篇其实应该是很早去接触的,如何使用Apache的Tinkerpop框架提供的gremlin语言去遍历一个图.与之对应的是传统E-R关系数据库的SQL语法, 或是各种自造的DSL—XQL
当然,首先我们应该简单了解TinkerPop到底是什么, 才能更好的理解Gremlin. 好比理解SQL之前得先理解什么是Database(Mysql)
19.4更新: 推荐Hugegraph几个作者写的深入理解gremlin系列(20+篇) , 按单个语法进行具体分析解释, 是目前中文分析里最好的~
19.5更新: 如果觉得只是入门, 不想细看, 可以看看这篇Gremlin常见用法总结
0x00.TinkerPop自述

先来张不错的Gremlin的Logo图,TP(TinkerPop)是图计算框架. 如图可以看出,TP就如同一个大健身房,里面有大量的器材(功能),好比一个生态系统. 一下了解它的全貌是很困难的事, 不妨跟着这个绿小人gremlin—TP中最主要的公民的活动一起来看看.( 顺便吐槽一下官方故事文档,上手显得很高深的感觉..也可能是我get不到英文故事的点)
待补充… (我还没看明白故事的主线..) 后面发现TP的东西太多了,单拆出来了. 见此
0x01.实践
建议Linux下进行,Win不单独说明. 下载启动gremlin控制台,通过它我们来学习使用gremlin: (不要觉得直接, 因为这种东西先上手*找下感觉,*再去看故事就会轻松不少.. )
1 | #注意下载地址随你访问IP会选取最佳,如果下载过慢请更换源,包大约107MB |
启动一个gremlin-console其实就像启动一个mysql命令行进程, 这里先用官方内置的TinkerGraph (一个极简的内存图db-推荐).那么接下来, 试着从0开始构建一张图↓
首先, 图是点和边的集合 , 那最简单的完整图就是**两个顶点,一条边** . 比如这样的:

1号顶点—> 3号顶点 我们把顶点往外扩的边9称为出边. 出点指向入点, 大家可能会觉得这个听起来不好记忆. 那我想一个比较和谐的比喻: 1是男生, 3是女生. 男生追求女生需要付出很多,所以叫out.. 女生得到了东西,所以是in …
言归正传,上面的顶点和边除了1,3,9 三个id一样的主键之外,没有任何属性名和值, 自然不是一个合格的图. 那我们给它加一些属性,比如: 人发明了(一定含金量的)软件 ,并给人名字和年龄的属性. 如图:

这样就构建出了一个完整的图模型了,那我们接着在gremlin控制台来实现这一过程:
1 | #用内置的TinkerGraph-db创建一个空的图对象 |
上面通过三条语句创建两个顶点一条边,下面来看看遍历上图的思路 :
Q: 我想知道: A开发了一个什么样的软件? 分析一下这个查询的步骤:
- 在图中找到A这个人.
- 顺着
develop这条边找到另一个顶点software.- 查找
software的属性,从而得到想要的描述.
可以看出跟普通句子的主谓宾补一样, 边通常在中间充当一个关系的角色. 而属性是各种补充.而gremlin也是类似这样的逻辑 :
1 | #首先从所有顶点中通过name找到A这个人--顶点 |
这个看起来很简单, 那么我们开始构造一张复杂的图, 这里我们用Tinker工厂内置的一个图, 回到刚的命令界面,先初始一个Modern 图. 然后试着遍历它.
1 | #初始化一个graph对象,已经包括了6顶点6边. |
通过上面的操作,你大概能构想一下这个modern图的结构么? 它的完整的结构是下面这样的:
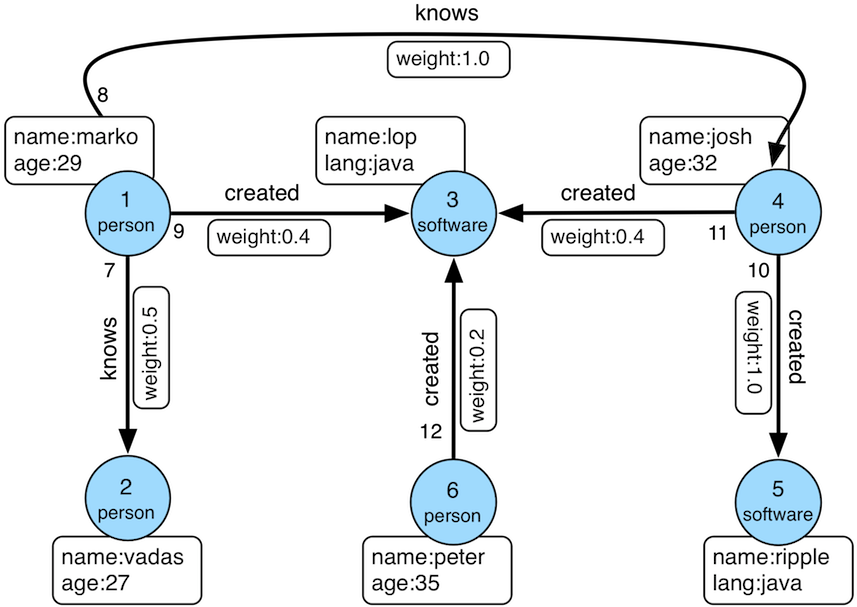
看到这个图可能会觉得直观,但是会觉得复杂. 各种属性名,顶点名,编号,边关系和方向看一下就晕了. 这就需要尽可能的熟悉图的结构, 接下来再来看看基于一个真实数据集的操作:
1 | #来自Wikipedia的网络投票数据集. 7k顶点 + 10万边 |
0x02.Gremlin语言
不管是SQL/CQL 还是Gremlin, 我们都可以归为是一种DSL.那么目前图db一般就分为两大类. 一类是类SQL/C的,一种是类函数式/流式(Gremlin).
因为DSL其实属于PL范畴, 我之后也只能从个人使用体验来评价优劣. 具体的文章可以参考一下文尾[2]的八个对比参考点 , 以及目前很火的TigerGraph的对比paper下载.
表面来说,Gremlin的函数式写法是比较符合简单需求下图的思考逻辑的 ,以一个graph为起点,然后去寻找周围的边和顶点. 但是复杂的情况下Gremlin也会显得很冗长..
0x03.什么是图计算?
根据TP官方定义, 图计算=图结构+遍历过程. 照例先上图:
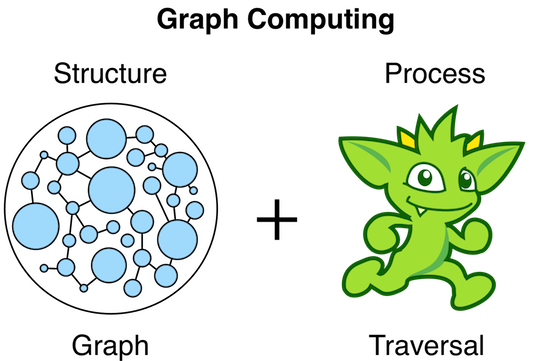
可能要说,这画的上面玩意,遍历是什么还是不知道啊.而且遍历一个有结构的图不是等于没解释么…. 带着这个疑问,等待之后的更新文章..
后面发现其实说图计算,应该是说在线的数据处理计算而非单纯的遍历. 上图中的结构是由点、边和属性定义的数据模型; 图数据的处理是基于图结构进行分析—-图处理的典型方式称为遍历。
比如什么呢? 举例一下:
最短路径 (包括全最短路)和连通性
这里的最短路算法其实多用于社交网络中的**六度空间理论 ,也就是说这个算法主要是针对路径<6的图模型使用的. 而非传统意义上任意两点**之间的最短路算法. 应用例子
为什么不采用
Dijkstra? 传统Dj的算法复杂度是O(mnlogn), 其中m为边数, n为顶点数. 在亿级的图规模上 , 还要考虑分布式导致的网络访问代价和IO代价, 它的优势基本就很小了. (并且要求*无向图)
K-core算法
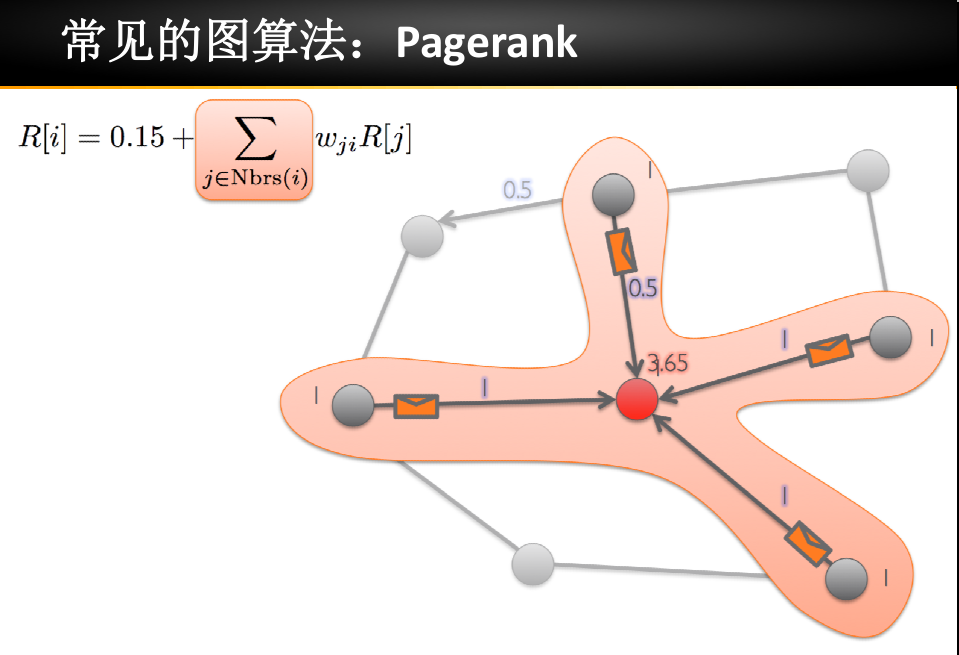
PR(page rank)算法
比如我们在Google搜索”janus”,有千万个结果, 如何对页面结果排序的算法
关联预测
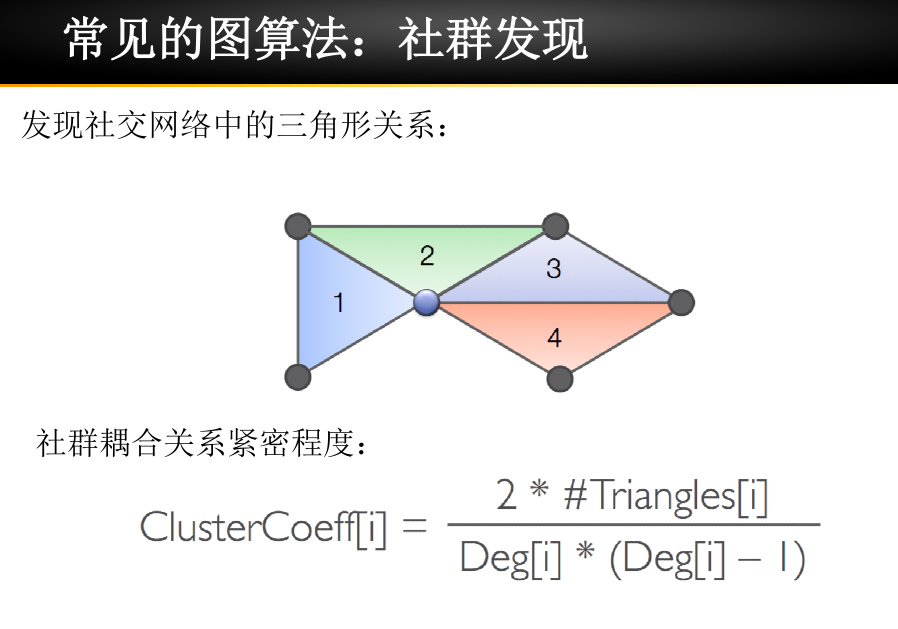
三角计数/社交紧密度
用来计算图中三角形的个数,可以分析出哪些子图关系更紧密, 衡量社群耦合关系的紧密程度(weibo,whatsapp已使用)
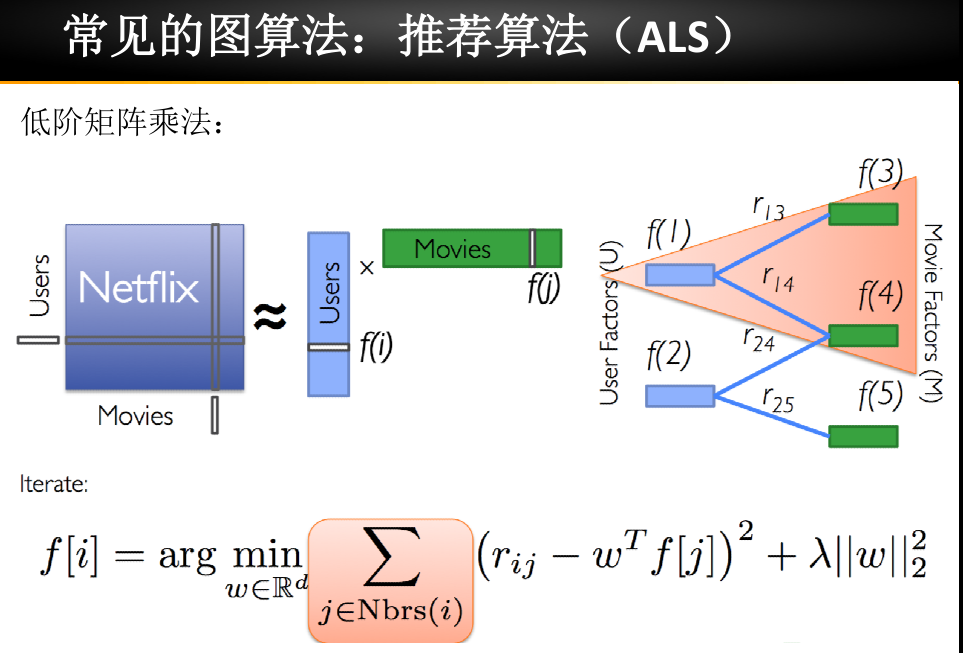
随机游走的实时推荐算法(ALS)
这是一个矩阵分解算法: 比如购物网站要给用户进行商品推荐,就要知道哪些用户对哪些商品感兴趣这时,可通过ALS构建一个矩阵图,在这个矩阵图里,假如被用户购买过的商品是1,没有被用户购买过的是0,这时我们需要计算的就是有哪些0有可能会变成1 (比如下图是Netflix使用的流程)
等等…还有一些没太看听过的~ 参考如图.
0x04.补充资料
有一些比官方文档写的人话许多 ,并且和 JanusGraph串联起来的handbook . 这对你快速上手和加深理解有许多帮助:
- gremlin图快速上手 (推荐) 补: PDF下载链接
- 19.04更新: 推荐Hugegraph几个作者写的深入理解gremlin系列(20+篇) , 按单个语法进行具体分析解释, 是目前中文分析里最好的~