这次开始分析JanusGraph的读流程和源码细节上 ,强烈建议先看看JanusGraph的写入流程分析, 以及Schema创建分析之后, 再来看读. 并建议看看精简实现的TinkerGraph是如何实现读的, 大体框架上是相同的(源自Tinkerpop的接口), 文章后续拆分为顶-中-底 三篇详细分析.
ps:这部分文章有不少还没有上传,后续慢慢调整后补上.
0x00.整体流程
首先从大流程上说, 整个JanusGraph的读分为三个部分:
- 通过Tinkerpop的
gremlin的查询语句转换为Janus看得懂的通用语法 (TraversalStrategy)
- Janus解析语句并进行加工 (包括筛选, 排序, 序列化等–Traversal?)
- 通过多次RPC请求后端的DB, 并进行交互, 最后的处理结果返回给
gremlin. (Backend-query)
同样, 整个过程从代码层面看很繁杂, 全览之后画了一个图, 方便大家快速理解查看. (因为步骤其实比图上复杂很多, 所以很多细节没有详细描述, 特别注意索引的使用. 原图也开放在processOn, 欢迎一起改进更新.)

其中序列化 / 反序列化的地方因为多处使用, 就没有单独写到方法内容中. 并且其中的过程也都根据重要程度进行了抽象和精简, 后续再来一一分析.
0x01.Traversal分析
A.数据结构
先来看看Tinkerpop在顶层定义的Traversal<S,E>接口,继承了Iterator<E>, Serializable, Cloneable, AutoCloseable接口.
Traversal表示对Graph的定向遍历,是所有遍历的基本接口.它可以有很多实现和继承,它的实现都可被视为特定域的图描述语言(比如我可以用顶点-边-属性来描述一个图, 也可用学生-学校-专业来描述图)
Traversal以两种方式之一进行落地:
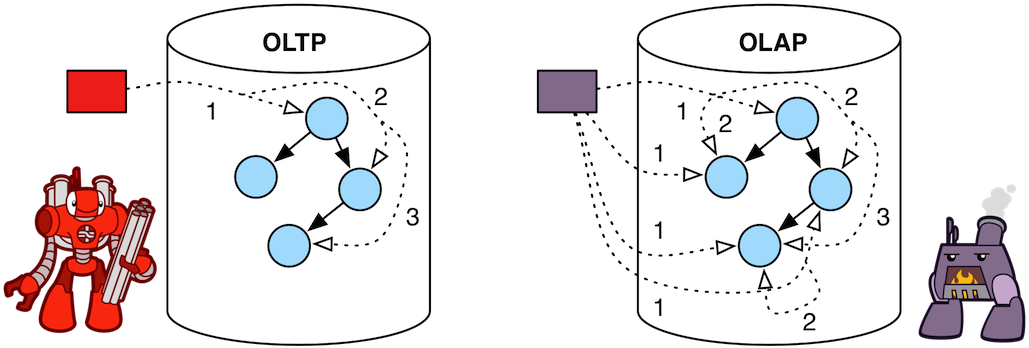
- OLTP遍历基于迭代器以DFS方式串行在单个JVM中执行(数据允许远程访问)
- OLAP遍历基于图计算以BFS方式并行在多个JVM(或多核)之间执行 (数据共享在特定结构中)
↓↓ 如下图所示, 可以看出两种搜索方式的路径和效率区别 ↓↓
然后注意还有个重要的TraversalSource (遍历源?)接口,它并非继承Traversal, 而有单独的作用:
TraversalSource用于创建Traversal实例,并且是一对多的关系. 遍历策略和图是遍历源的主要组成
withXxx() 方法用于配置遍历策略- 其它方法是在给定图和配置策略的基础上,生成图遍历
- 遍历源生成后是不可变的,因为配置链会产生新的遍历源(??)
B. Traversal策略
图读取的时候, 遍历策略是一个很重要的因素, 那首先得知道什么是遍历策略…以及有Tinkerpop自带哪些遍历策略. 帮助我们理解读取的整个过程和耗时.
TraversalStrategy –遍历策略是对每一次读进行分析处理的过程. 比如我要读取图中某个范围的顶点内容, 应该怎么去在图中更高效的走呢? 如果短时间内我重复查询, 是不是应该选取更好的策略呢? 这些都是遍历策略需要考虑的事 . 大体上, Tinkerpop提供5种策略, 依次执行:
- 遍历过程开始, 分析语法以及嵌套 (初次加工-Decoration)
- TinkerPop自带的路径/语法优化 (原有优化-Optimization)
- 图DB自身可添加的策略去优化图遍历 (自定义优化-Provid).
- 遍历完成后得到的数据 ,需要再次加工 (最后の加工-F).
- 过滤掉不合法或者重复的遍历结果, 结束 (完结前校验-V).
“工欲善其事必先利其器”, 首先这里介绍一下Gremlin自带的强大分析函数 explain()和profile(), 它能提供读取/查询时的遍历信息 (遍历策略, 索引命中时间, 查询步数等..) 举例如下, 比如某次查询语句:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| gremlin>
g.V().hasLabel('person').outE().identity().inV().count().is(gt(5)).explain()
====================>Traversal详细展开<====================
Original Traversal [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), IdentityStep, EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]
ConnectiveStrategy [D]
MatchPredicateStrategy [O]
FilterRankingStrategy [O]
InlineFilterStrategy [O]
IncidentToAdjacentStrategy [O]
RepeatUnrollStrategy [O]
PathRetractionStrategy [O]
CountStrategy [O]
AdjacentToIncidentStrategy [O]
LazyBarrierStrategy [O]
TinkerGraphCountStrategy [P]
TinkerGraphStepStrategy [P]
ProfileStrategy [F]
StandardVerificationStrategy [V]
Final Traversal [TinkerGraphStep(vertex,[~label.eq(person)]), VertexStep(OUT,edge), IdentityStep, EdgeVertexStep(IN), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]
|
注意以上都是实际遍历前的操作, 也就是说上述操作是没有接触到存储层(I/O)的, 可以称之为预处理操作, 而大部分XXStrategy 一般都源自一个顶层接口 TraversalStrategy .
自然我们想知道耗时, 首先通过profile()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| Gremlin >
g.V().out('created').repeat(both()).times(3).hasLabel('person').values('age')
.sum().profile()
==>Traversal 细项: JanusGraph在这里列的项更多更细,当然默认排版不太友好.看起来很费劲
Step Count Traversers 耗时(ms) 占比 %
==============================================================================
TinkerGraphStep(vertex,[]) 6 6 0.076 11.61
VertexStep(OUT,[created],vertex) 4 4 0.108 16.39
NoOpBarrierStep(2500) 4 2 0.050 7.63
VertexStep(BOTH,vertex) 10 4 0.045 6.86
NoOpBarrierStep(2500) 10 3 0.025 3.81
VertexStep(BOTH,vertex) 24 7 0.028 4.34
NoOpBarrierStep(2500) 24 5 0.030 4.62
VertexStep(BOTH,vertex) 58 11 0.040 6.15
NoOpBarrierStep(2500) 58 6 0.046 7.03
HasStep([~label.eq(person)]) 48 4 0.033 5.08
PropertiesStep([age],value) 48 4 0.042 6.37
SumGlobalStep 1 1 0.133 20.11
总计 - - 0.662 -
|
首先要注意, profile() 本身会影响计算遍历的准确时间, 所以比较需要控制在都使用了profile 函数的前提下.其次, 以上表数据为例 (Janus会更详细), 有一些列需要说明一下: (Step代表每次遍历的一个步骤)
- Traversal: 这代表图中任意点之间的一次遍历/查询过程. 是各种读操作的抽象之父…
- Traversers: 注意跟上面不同, 这个可以叫
遍历器 ,或者说遍历对象 (er结尾), 表示一次遍历中的当前状态. 这里的数字是经过当前Step的遍历器个数. 遍历器包含 : side-effect(副作用?...) , sack(麻袋?) ,bulk count , 历史路径…这些属性参数. (翻译无能…)
- Count: 给遍历器对象完整的计数 (怎么理解represent )
Step是什么, 它和Path区别?
Step在图服务中一般指的是遍历中的计算最小单元(而非生活中常说的步子) ,更好理解的解释是步骤, 每个Step接受一个元素对象作为入参, 加工处理后返回. 在一次Traversal中, 会有很多个步骤(Step), 它们就以流的方式加载, 并且产生一个延迟的加工计算链 (流式编程的显著优点之一)
而Path表示一次遍历(Traversal)中的某一条路径选择, 这个应该是最贴合我们日常说的”路径”的, 任何实现的XxxPath都有两个list : 一个是这条路径经过所包含的元素,另一个记录这些元素的标签名(比如person/age/name..) ,Path因为代表的是某条路径, 所以使用上比Step少很多
Traversers和Count的具体区别是什么呢? (简单理解是去重..)
首先 ,从数目上你可以发现count的数值总是≥ traverser的, 这是因为当两个traverser相同的时候, 可以合并为一个新的traverser , 这个新的traverser.bulk()的数值是两个合并前的traverser的和.
而Count参数代表所有traverser.bulk() 的总和, 所以它表示没被枚举的*”represented’ traversers*数量, 你可以认为它是包含重复的traversers的计数器, 所以它肯定大于等于traversers的数目.
最后就是profile()方法可以传入side-effect key 作为参数, 但是我还没搞清楚 side-effect 是个啥玩意….翻译的很拗口, 上面也有不少地方不是人话, 我都是自己捋了半天, 欢迎指点..
C. 查询细节
0x02.代码细节
看完了结构上和定义上的设计分析,接下来代码阅读可关注JanusGraphLocalQueryOptimizerStrategy和JanusGraphStepStrategy, ManagerSystem, StandardEdgeLabelMaker ,StandardPropertyMaker , StandardJanusGraphTx (这些可能随时更改更新) . 以及核心的query包 ,下面有各种查询的实现.
A.顶层
顶层的遍历策略/语法分析, 可以先看看策略部分, 有助你先大致了解一下不同读关键的区别. 首先上面说了有5大策略分类, 这些分类下又有大概总共30多个具体的策略, 那我们肯定不可能上手就去把源码细节啃一遍, 先举几个例子, 然后简单介绍一下每个策略. 下面介绍的是IdentityRemovalStrategy ,属于O
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| public final class IdentityRemovalStrategy extends
AbstractTraversalStrategy<TraversalStrategy.OptimizationStrategy> implements
TraversalStrategy.OptimizationStrategy {
private static final IdentityRemovalStrategy INSTANCE = new
IdentityRemovalStrategy();
private IdentityRemovalStrategy() {}
public static IdentityRemovalStrategy instance() {return INSTANCE;}
@Override
public void apply(final Traversal.Admin<?, ?> traversal) {
if (traversal.getSteps().size() <= 1)
return;
for (final IdentityStep<?> identityStep :
TraversalHelper.getStepsOfClass(IdentityStep.class, traversal)) {
if (identityStep.getLabels().isEmpty() ||
!(identityStep.getPreviousStep() instanceof EmptyStep)) {
TraversalHelper.copyLabels(identityStep,
identityStep.getPreviousStep(), false);
traversal.removeStep(identityStep);
}
}
}
}
=> g.V().has("age","15").identity().identity().xxx()
=> g.V().has("age","15").xxx()
|
好,接着说最简单的例子g.V().has('age','18') ,这种查询如果没有索引, 最慢需要O(n)的时间复杂度, 也就是把所有顶点都遍历了一遍.. 而有索引的时候, 只需要O(logn)的时间复杂度.
JanusGraph自身的策略在StandardJanusGraph的静态代码块部分就会最先加载, 你可以发现它有5个自定义策略 : (取自0.1.1版, 新版可能更多)
- 相邻顶点优选策略
- 本地查询优化策略 (常用)
- Janus自身的每步查找策略 (常用)
- 最短路径优化策略 (少)
- Schema查找策略 (少)
那么很自然, 我们发现前三个是常用的查询策略(特别是2&3). 看看代码是如何实现的, 具体是什么效果?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
@Override
public void apply(final Traversal.Admin<?, ?> traversal) {
if (TraversalHelper.onGraphComputer(traversal))
return;
TraversalHelper.getStepsOfClass(GraphStep.class, traversal).forEach(originalGraphStep -> {
if (originalGraphStep.getIds() == null || originalGraphStep.getIds().length == 0) {
final JanusGraphStep<?, ?> janusGraphStep = new JanusGraphStep<>(originalGraphStep);
TraversalHelper.replaceStep(originalGraphStep, janusGraphStep, traversal);
HasStepFolder.foldInIds(janusGraphStep, traversal);
HasStepFolder.foldInHasContainer(janusGraphStep, traversal, traversal);
HasStepFolder.foldInOrder(janusGraphStep, janusGraphStep.getNextStep(), traversal, traversal, janusGraphStep.returnsVertex(), null);
HasStepFolder.foldInRange(janusGraphStep, JanusGraphTraversalUtil.getNextNonIdentityStep(janusGraphStep), traversal, null);
} else {
final Object[] ids = originalGraphStep.getIds();
ElementUtils.verifyArgsMustBeEitherIdOrElement(ids);
if (ids[0] instanceof Element) {
final Object[] elementIds = new Object[ids.length];
for (int i = 0; i < ids.length; i++) {
elementIds[i] = ((Element) ids[i]).id();
}
originalGraphStep.setIteratorSupplier(() -> originalGraphStep.returnsVertex() ?
((Graph) originalGraphStep.getTraversal().getGraph().get()).vertices(elementIds) :
((Graph) originalGraphStep.getTraversal().getGraph().get()).edges(elementIds));
}}});}
|
关于JanusGraphLocalQueryOptimizerStrategy 的源码我的确不知道所谓的本地查询是什么意思….然后中间的操作大部分也都封装了, 等后续再看看..
先接着看看AdjacentVertexFilterOptimizerStrategy , 也就是相邻顶点优选策略..
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| @Override
public void apply(final Traversal.Admin<?, ?> traversal) {
TraversalHelper.getStepsOfClass(TraversalFilterStep.class, traversal).forEach(
originalStep -> {
Traversal.Admin<?, ?> filterTraversal = (Traversal.Admin<?, ?>) originalStep.getLocalChildren().get(0);
List<Step> steps = filterTraversal.getSteps();
if (steps.size() == 2 &&(steps.get(0) instanceof EdgeVertexStep ||
steps.get(0) instanceof EdgeOtherVertexStep) &&(steps.get(1) instanceof IsStep)) {
Direction direction = null;
if (steps.get(0) instanceof EdgeVertexStep) {
EdgeVertexStep evs = (EdgeVertexStep) steps.get(0);
if (evs.getDirection() != Direction.BOTH) direction = evs.getDirection();
} else {
assert steps.get(0) instanceof EdgeOtherVertexStep;
direction = Direction.BOTH;
}
P predicate = ((IsStep) steps.get(1)).getPredicate();
if (direction != null && predicate.getBiPredicate() == Compare.eq &&
predicate.getValue() instanceof Vertex) {
JanusGraphVertex vertex =
JanusGraphTraversalUtil.getJanusGraphVertex((Vertex) predicate.getValue());
Step<?, ?> currentStep = originalStep.getPreviousStep();
while (true) {
if (!(currentStep instanceof HasStep) && !(currentStep instanceof IdentityStep)) {
break;
}}
if (currentStep instanceof VertexStep) {
VertexStep vertexStep = (VertexStep) currentStep;
if (vertexStep.returnsEdge()&& (direction == Direction.BOTH ||
direction.equals(vertexStep.getDirection().opposite()))) {
TraversalHelper.replaceStep(originalStep,new HasStep(traversal,HasContainer
.makeHasContainers(ImplicitKey.ADJACENT_ID.name(), P.eq(vertex))),traversal);
}}}}});}
|
B.中间层
Janus接受到解析后的遍历策略, 然后进行处理和操作, 是最关键的部分, 这个部分称之为中间层.
首先看前两个, 也就是Janus自己遍历策略的实现, 这两个在一次普通查询中是必会调用到的,对应StandardJanusGraphTx中, 有个返回Iterator<JanusGraphElement> 的execute 方法,
1
| JanusGraphStep<S,E extends Element> extends GraphStep<S,E> implements HasStepFolders
|
C.IO层
IO层主要是分两个, 一个是面向Cassandra/Hbase , 一个是面向ElasticSearch/Lucene. 目前来看, 写入ES索引是写入的核心瓶颈之一. 读取的话, 要具体看查询语法, 以常见的精准匹配索引为例. 主要还是先关注Cassandra/Hbase 这种主存储的读速度, 包括RPC的次数. (因为他们不支持关联查询 ,也就是两张表得分开查, 而不能和SQL一样以A表的结果直接查B表)
0x02.关键点
1.顶点为中心的索引
这是JanusGraph/Titan不同于普通图的关键之一, 也是默认自建的一个索引. 那它到底是什么代码实现, 原理是什么, 这个必须得搞清楚.
2.RPC和序列化
要知道Cassandra/Hbase 这种列DB并不支持关联查询, 也就是说我从一张表A中查到了一个vid ,是不能通过vid直接去查表b的 ,而要通过后端重新发一次请求, 把vid作为参数传过来. 这里是通过序列化后的16进制位运算匹配的么?
每次插入新的顶点, 不管是否用户自定义的ID, 都会去搜一次么? 新的边数据的生成呢?
3.遍历逻辑
4.遍历策略
列一下常见的策略含义
- XxxGraphStepStrategy: 全局提取包含
has() 语法 , 以图中心索引的方式去查询
- FilterRankStrategy : 以耗时/耗空间 为指标筛选步骤(Step)
- InlineFilterStrategy: 内部筛选过滤器以提高它的紧凑性
- ElementIDStrategy: 元素ID策略控制图数据库实现的时候, 对ID的自定义性, 比如可以运行用户自定义字符串的ID, UUID等..
- EventStrategy: 控制遍历过程中的变化监察, 常见比如顶点/边/属性的CURD操作, 效果就是如果你开启了这个策略, 那么你通过gremlin对图进行CURD操作, 就会输出具体的信息(像日志一样.)
参考资料:
- Tinkerpop官方文档