“What I cannot create , I do not understand (不能自己实现的东西, 说明你还没真正理解它)”
“Know how to solve every problem that has been solved (在这基础上, 学会理解 每一个已被实现的东西)”
很多时候看大家Blog的开头都会放一张图, 我因为一直很难找到应景的图, 所以基本没放过, 今天真是觉得这张来自费曼 前辈最后一节课的图实在太适合了, 也以此表示对这些钻研科学的人的尊敬,
新年的第一个新计划, 开始一个中长期 的DIY (回炉)系列 ,参考前辈们自己重新把整个计算机的常见底层组件 自己实现一遍, 语言应该主要使用 C/Go/Python ,以巩固和加深对很多之前使用过的技术的理解.当然三分热度是不行的, 所以选择会有的放矢. 最近看了不少的分布式和存储和图的内容, 而在几乎所有应用软件中, DB可能是最复杂的一个, 那么我们就从自己动手实现一个DB开始, 深入的理解 :
“How dose a database wok?”
0x00.前言 作为一名合格的技术汪, 应该对所用的东西尽可能的理解, 那么何谓”理解 “ , 开头的费曼前辈没有直接给出答案, 但给出了一个排除. 那除了自己能实现之外, DB这个前后端都离不开的必备软件之一究竟有哪些核心点我们需要实现呢, 不妨一起来思考以下几个问题:
What format is data saved in? (in memory and on disk)
When does it move from memory to disk?
Why can there only be one primary key per table?
How does rolling back a transaction work?
How are indexes formatted?
When and how does a full table scan happen?
What format is a prepared statement saved in?
What’s the difference between B+ Tree & LSM Tree?
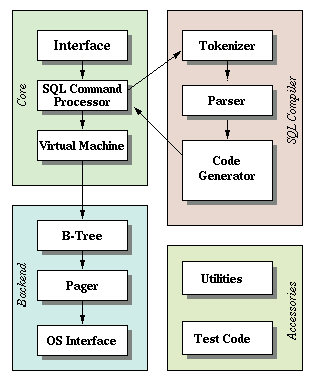
这里, 我们通过参考动手实现mini-sqlite 来理解Database的核心理念, 看看在自己实现之后, 能否解答上述的问题? 先看看sqlite 官 方的整体结构图:
一次查询需要经过的核心步骤—-自顶而下是 : 分词器 --> 解析器 --> 代码生成器 (前端) --> 虚拟机 --> B树 --> Pager --> OS接口 (后端) , 这里把DB本身也分为两个部分, 前端可以简单理解为, 用户输入SELCET * FROM table 语句, 转换为DB可读的二进字节码的过程, 后端则是实际的数据寻址和优化, 这样简单把它分为两块来实现.
PS: 后续的代码皆是VScode用C编写(Clang+MinGW-w64), 强烈建议参考VScode for C/C++ (Recommend) 配置, 后续不再说明, Win上推荐gcc一些,clang有奇怪的错误..
0x01.入口 上手当然是得平滑一些, 常见的DB都会提供一个类命令行的界面, 本质是一个死循环, 不断的判断是否有输入和命令执行, 然后打印输出结果, 类似我们的bash ,这个在计算机中有个专有名词REPL (read-execute-print loop) ,并且假设它就是我们程序的入口, 那先来段代码? 注意这里C的输入参考多种输入说明 , 在win上没有getline() 函数, 只能自己实现….或者用fgets() 改一下代码. [下面的代码]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 #include "stdio.h" #include "stdlib.h" #include "string.h" #include <errno.h> #include <stdint.h> typedef struct { char *buffer; size_t bufferLength; ssize_t inputLength; }InputBuffer; InputBuffer* newInputBuffer () { InputBuffer *inputBuffer = malloc (sizeof (InputBuffer)); inputBuffer->buffer = NULL ; inputBuffer->bufferLength = 0 ; inputBuffer->inputLength = 0 ; return inputBuffer; } void printFormat () { printf ("db -> " ); }ssize_t getline (char **lineptr, size_t *n, FILE *stream) { size_t pos; int c; if (lineptr == NULL || stream == NULL || n == NULL ) { errno = EINVAL; return -1 ; } c = fgetc(stream); if (c == EOF) { return -1 ; } if (*lineptr == NULL ) { *lineptr = malloc (128 ); if (*lineptr == NULL ) { return -1 ; } *n = 128 ; } pos = 0 ; while (c != EOF) { if (pos + 1 >= *n) { size_t new_size = *n + (*n >> 2 ); if (new_size < 128 ) { new_size = 128 ; } char *new_ptr = realloc (*lineptr, new_size); if (new_ptr == NULL ) { return -1 ; } *n = new_size; *lineptr = new_ptr; } ((unsigned char *)(*lineptr))[pos ++] = c; if (c == '\n' ) { break ; } c = fgetc(stream); } (*lineptr)[pos] = '\0' ; return pos; } void readInput (InputBuffer* inputBuffer) { ssize_t bytesRead = getline(&(inputBuffer->buffer),&(inputBuffer->bufferLength),stdin ); if (bytesRead <= 0 ) { printf ("Invalid input\n" ); exit (EXIT_FAILURE); } inputBuffer->inputLength = bytesRead - 1 ; inputBuffer->buffer[bytesRead - 1 ] = 0 ; } int main ( int argc, char const *argv[]) { InputBuffer *inputBuffer = newInputBuffer(); printf ("Sqlite starts...\n" ); while (1 ) { printFormat(); readInput(inputBuffer); if (strcmp (inputBuffer -> buffer,".q" ) ==0 ) { exit (EXIT_SUCCESS); } else { printf ("Command '%s' is unsupported , exit plz~ \n" , inputBuffer->buffer); } } }
写完你可能会觉得, 就一个入口就要写这么正式呀, 其实除开自己实现的getline() , 其它是符合良好的开发习惯的, 而且后续还会有其他作用. 完全理解每一行之后就开始进入第一个核心了.
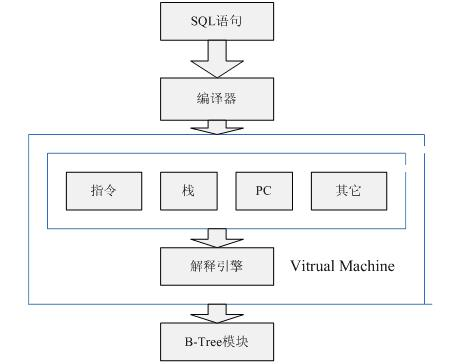
0x02.VM和SQL编译器 看标题挺唬人的, 这里说的SQL编译器其实并不复杂, 主要就是分词器 + parser + CG (如下图)的组合, 而这里说的VM(虚拟机)和大家理解虚拟化的虚拟机差的很远, 在这主要是执行 SQL语言转化为DB能识别的机器代码(bytecode.作用类似JVM); 同样, 而且我们实现的都是最精简(原始)的版本, 所以代码也很短 , 必须彻底搞清楚每一行.
可以看到我们在0x01 中已经实现了”interface + cmd processor” 的模子, 然后开始读取正式命令, 走到SQL编译器层了, 最后把结果返回再传给VM执行, 流程还是非常清晰的. (流程还需要反复推敲思考, 比如为什么不把编译器和VM放一起, 直接编译完就执行呢? 答: 1.解耦,各司其职 2.常用查询可缓存提速 )
同样的道理, 我们回顾刚写好的main(), 里面还不支持除了exit外的任何命令, 那么也应该从最基础的开始逐步去实现 , 先优化一下之前的系统命令, 再加点关键字~
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 typedef enum {int main ( int argc, char const *argv[]) { InputBuffer *inputBuffer = newInputBuffer(); printf ("Sqlite starts...\n" ); while (1 ) { printFormat(); readInput(inputBuffer); if (inputBuffer -> buffer[0 ] == '.' ) { if (doSysCMD(inputBuffer) == EXECUTE_SUCCESS) { continue ; }else { printf ("Command '%s' is unsupported .. \n" , inputBuffer->buffer); } } Statement statement; if (prepareStatement(inputBuffer,&statement) == EXECUTE_SUCCESS){ break ; }else { printf ("Keyword '%s' is unsupported .. \n" , inputBuffer->buffer); continue ; } executeStatement(&statement); }
需要注意的是, 因为C没有异常处理机制(使用error code机制, 类似go也优先使用..), 所以我们这里更好的做法应该是用枚举去实现错误码, 而不是写大量int的-1,0,1,2...然后配合N个if-else .不过既然不是面向初学者, 那我们就借此顺便回顾一下, 异常和错误的区别和优劣 : (附带assert–断言)
接着我们把doSysCMD() 修改为返回枚举实现一下:
1 2 3 4 5 6 7 ExecuteResult doSysCMD (InputBuffer *inputBuffer) { if (strcmp (inputBuffer -> buffer,".q" ) == 0 ){ exit (EXIT_SUCCESS); }else { return EXECUTE_FAILURE; } }
上面这些改动是很好理解的, 那么接下来关键就是prepareStament() 和 executeStatement() 这两个函数了, 以及到底什么是Statement ? 这个可能在各种SQL连接器里都经常看到的词 ,可能大家都是照着一敲, 很少去深入思考,从抽象出的层面来看, Statement 主要做了存放SQL信息, 然后把这个信息传给VM的功能, 那它到底需要什么成员呢? 还是不太清楚, 但是至少我们知道这里可以存放SQL的信息, 那先抽象一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 typedef enum { typedef struct { SQLType type; }Statement; ExecuteResult prepareStatement (InputBuffer *inputBuffer, Statement *statement) { if (strncmp (inputBuffer -> buffer, "select" , 6 ) == 0 ){ statement -> type = SELECT; return EXECUTE_SUCCESS; } if (strncmp (inputBuffer -> buffer, "insert" , 6 ) == 0 ){ statement -> type = INSERT; return EXECUTE_SUCCESS; } return EXECUTE_FAILURE; } void executeStatement (Statement *statement) { switch (statement->type){ case SELECT: printf ("do select..\n" ); break ; case INSERT: printf ("do insert..\n" ); break ; } }
这样做完 , 我们就实现了一个SQL编译器和VM的模型, 这个时候再来看看sqlite的完整实现: (附 一张sqlite-VM的单独图:)
可能你会说这也太简陋了吧, 连个实际的操作都没有, 都是model, 没有看到实际的数据, 那接下来, 我们就要实现0x02图中的backend 的部分, 当然先来实现in-memory 的单表存储库吧.
0x03.In-memory Backend 之前在图里, 其实你可以看到每个图基本最早实现的都是in-memory 的版本, 然后再考虑如何落盘, 不过即使是纯内存模式, 也需要一步步来构建, 否则整个体系也会很复杂, 我们先加以限定条件:
写入 : 只支持尾插的方式插入一行数据 (e.g. insert 1 admin passwd )
查询: 只支持查询所有数据 (也就是直接select就显示所有)
只实现一个固定基本的单表 (比如下面这样的user表)
column
type
id
int
usrname
varchar(32)
passwd
varchar(255)
通过这个描述, 我想大家就不会觉得很迷茫了, 就是写一个固定格式的数据 –> 存到内存 –> 最后全部读 出来 ,那首先就得实现我们之前留空的prepareStatement()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ExecuteResult prepareStatement (InputBuffer *inputBuffer, Statement *statement) { if (strncmp (inputBuffer -> buffer, "insert" , 6 ) == 0 ){ statement -> type = INSERT; int propsNum = sscanf (inputBuffer -> buffer, "insert %d %s %s" ,statement->id,statement->usrname,statement->passwd); if (propsNum != 3 ){ return EXECUTE_FAILURE; } return EXECUTE_SUCCESS; } if (strncmp (inputBuffer -> buffer, "select" , 6 ) == 0 ){ statement -> type = SELECT; return EXECUTE_SUCCESS; } return EXECUTE_FAILURE; }
上面很简单的读取好了, 但是可以想下, 如果直接把每行数据的信息直接丢Statement 中, 那后续修改维护都会很不方便, 所以可以回想一下, 各种XDBC 中都有一个单独的Row 对象专门处理, 并且我们也发现所有的错误码都是一个枚举值并不合适, 思考一下后, 可以得到新的结构体:
1 2 3 4 5 6 7 8 9 10 11 12 const uint32_t NAME_MAX_SIZE = 32 ; const uint32_t PASSWD_MAX_SIZE = 255 ;typedef struct { uint32_t id; char usrname[NAME_MAX_SIZE]; char passwd[PASSWD_MAX_SIZE]; }Row; typedef struct { SQLType type; Row row; }Statement;
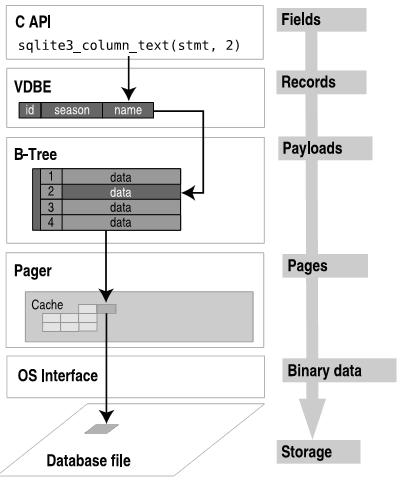
现在就有一个成型的固定表的感觉了, 但是要想起之前sqlite的backend结构图, 数据可不能这样直接的丢在内存中, 它需要一个单独的结构来存储,常见使用B树/LSM的结构, 比如sqlite使用Btree来存储, 如图:
那我们要手写一个B树么? (那不是有了Yin的实力, 所以我们这老实用数组代替), 就算是用数组存储, 也需要再做不少具体的限定:
每个page存尽可能多的行 (并且紧凑存储)
page只允许按需分配 (且直接使用内存块)
指向page数组的指针长度固定
对了, 如果不太理解这理的page 是什么意思, 可以参考一下page介绍 和底层分析 . 简单来看, sqlite中一个DB对应一个磁盘文件 (db-file), 文件中的数据被分为若干个大小相同的page, 然后这些page的关系再由如B树 来存储 (整个磁盘文件可以理解为一个page数组 ,缓存之后再说.) 首先来优化设计一个”紧凑的 “行结构 ,然后利用memcpy(void *st1, const void *str2, size_t n) 从str2复制n个字符到str1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #define sizeOfColumn(Struct,Column) sizeof(((Struct*)0)->Column) const uint32_t ID_SIZE = sizeOfColumn(Row,id);const uint32_t USRNAME_SIZE = sizeOfColumn(Row,usrname);const uint32_t PASSWD_SIZE = sizeOfColumn(Row,passwd);const uint32_t ROW_SIZE = ID_SIZE + USRNAME_SIZE + PASSWD_SIZE;const uint32_t ID_OFFSET = 0 ;const uint32_t USRNAME_OFFSET = ID_OFFSET + ID_SIZE;const uint32_t PASSWD_OFFSET = USRNAME_OFFSET + USRNAME_SIZE;void serializeRow (Row *source ,void *destination) { memcpy (destination + ID_OFFSET,&(source->id), ID_SIZE); memcpy (destination + USRNAME_OFFSET,&(source->usrname), USRNAME_SIZE); memcpy (destination + PASSWD_OFFSET,&(source->passwd), PASSWD_SIZE); } void deserializeRow (void *source,Row *destination) { memcpy (&(destination->id), source + ID_OFFSET, ID_SIZE); memcpy (&(destination->usrname), source + USRNAME_OFFSET, USRNAME_SIZE); memcpy (&(destination->passwd), source + PASSWD_OFFSET, PASSWD_SIZE); }
上面内存复制的时候, 具体的地址 ,和复制大小 如何得来一定要仔细思考清楚, 就是当一个紧挨着的数组想, 复制的都是地址 , 实际的对应表应如下所示:
column
position
size (bytes)
id
0
4
usrname
4
32
passwd
36
255
total(row)
/
291
这样设计完, 你就能得到了一个自己设计的紧凑行结构, 并可以把数据内容进行转换了, 然后我们就开始规划我们的核心Table(表结构)了, 从上面的概率中我们知道一张表实际是由一个page数组 , 然后每个page又由若干行 构成, 所以来简单设计一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 const uint32_t PAGE_SIZE = 4096 ; const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;const uint32_t MAX_tPAGES = 10 ; const uint32_t MAX_tROWS = MAX_tPAGES * ROWS_PER_PAGE;typedef struct { void * pages[MAX_tPAGES]; uint32_t rowNum; }Table; void * rowPosition (Table *table, uint32_t rowNum) { uint32_t pageNum = rowNum / ROWS_PER_PAGE; void * page = table->pages[pageNum]; if (page == NULL ) { page = table->pages[pageNum] = malloc (PAGE_SIZE); } uint32_t rowOffset = rowNum % ROWS_PER_PAGE; uint32_t byteOffset = rowOffset * ROW_SIZE; return page + byteOffset; }
这里可能是第一个需要好好思考的地方, 怎么去分page, 怎么去构造table, 怎么去获得行的位置,包括这样写是否合理, 有没有什么问题? 需要认真推敲一下, 然后不知不觉我们已经把基本的读写表操作的组件 实现的差不多了, 再回顾一下之前的留空, 是时候组合起来了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 ExecuteResult executeInsert (Statement *statement,Table *table) { if (table->rowNum < MAX_tROWS){ Row *insertRow = &(statement->row); serializeRow(insertRow, rowPosition(table,table->rowNum)); table->rowNum ++; return EXECUTE_SUCCESS; } return EXECUTE_TABEL_FULL_ERROR; } ExecuteResult executeSelect (Statement *statement,Table *table) { Row row; for (uint32_t i = 0 ; i < table->rowNum; ++i ){ deserializeRow(rowPosition(table,i), &row); printRow(&row); } return EXECUTE_SUCCESS; } void printRow (Row *row) {printf ("User:[%d, %s, %s]\n" , row->id, row->usrname, row->passwd);}ExecuteResult executeStatement (Statement *statement, Table *table) { switch (statement->type){ case SELECT: return executeSelect(statement, table); case INSERT: return executeInsert(statement, table); } return EXECUTE_FAILURE; }
这样, 基本的读写就完成了, 我们最后就是把上一节中的main()函数予以升级, 然后初始化新的核心Table 结构了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 Table* initTable () { Table *table = malloc (sizeof (Table)); table->rowNum = 0 ; return table; } typedef enum { EXECUTE_SUCCESS, EXECUTE_FAILURE, EXECUTE_PARAMETER_ERROR, EXECUTE_TABEL_FULL_ERROR, EXECUTE_UNSUPPORT_CMD }ExecuteResult; int main ( int argc, char const *argv[]) { InputBuffer *inputBuffer = newInputBuffer(); Table *table = initTable(); printf ("Sqlite starts...\n" ); while (1 ) { printFormat(); readInput(inputBuffer); if (inputBuffer -> buffer[0 ] == '.' ) { if (doSysCMD(inputBuffer) == EXECUTE_SUCCESS) { continue ; }else { printf ("Command '%s' is unsupported .. \n" , inputBuffer->buffer); } } Statement statement; switch (prepareStatement(inputBuffer,&statement)){ case EXECUTE_SUCCESS: break ; case EXECUTE_PARAMETER_ERROR: printf ("Syntax error,plz check ur input again(params' type & amount)\n" ); continue ; case EXECUTE_UNSUPPORT_CMD: printf ("Keyword '%s' is unsupported .. \n" , inputBuffer->buffer); continue ; } } switch (executeStatement(&statement, table)) { case EXECUTE_SUCCESS: break ; case EXECUTE_TABEL_FULL_ERROR: printf ("Table is full, wait del..\n" ); break ; } }
最后, 因为篇幅原因, 完整的代码 我就不在文章再丢了, 放在Github-DIY 上, 目前还有点小bug, 写入执行到memcpy() 的时候就会报段错误…..
1 2 3 printf ("%p ,%p, %p " , &(source->id), &(source->usrname), &(source->passwd));输出 : 000000000061F CF4 ,000000000061F CF8, 000000000061F D18
第一篇差不多完了, 待年后继续我们的探索旅程…
参考资料:
Deep understanding sqlite (Recommend) Let’s build a simple DB Build-Your-Own-X How dose a db work -En How dose a db work -Zh Designing Data-Intensive Applications-Zh Architecture of SQLite VScode for C/C++ (Recommend) typedef in C (PL) char * in C (PL) Debug segmentation fault