这里记录一下图服务相关的机器磁盘选型. 包括SSD 的基本原理介绍, 如何测试磁盘性能, 如何简单选择合适的磁盘搭配 (结论是建议1SSD[主] + 2HDD[副本])异构存储
说明: 后续补充了一些个人学习笔记, 可能用词和底层原理不一定准确, 有问题请及时联系改正, 有好的参考也可以补上
0x00. 磁盘背景
HDD和SSD的原理对比:

HDD:
- HDD用N/S极代表0/1, 要读取数据,首先磁头需要摆动到相应的同心圆上,这又称为seek(寻道), 大概需要
7-15ms, 而随机寻道, 就成了HDD最大的性能瓶颈之一. 它基于温彻斯特的热学架构. - 磁盘寻道完成后,仍然还会转一段时间,这个过程可以称为潜伏(latency)
- 最后,当数据块滑过磁头的下方的时候,才能被取走,这个耗时大概在
2-7ms,这个时间跟磁盘转速有关, 所以谈HDD的性能时, 转速这个指标是很重要的.
10.23更新: 以上讲的HDD的原理还非常的简略, 但是我找到了一个讲原理非常不错的PPT, 分享给大家, 建议有空可以认真看看, 有问题欢迎交流, PPT下载地址
SSD:
大家都知道SSD比HDD要快得多, 但是快在哪呢?
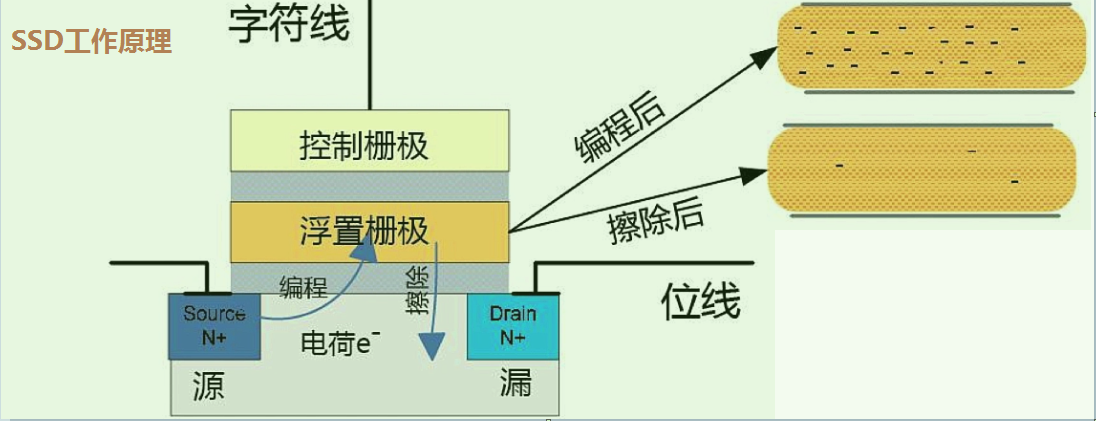
- 固态不同之处是它采用的nand flash芯片, 没有机械架构
- 图中其中的浮置栅极相当一个小电池,有电荷的时候处于导电状态(表示数据0), 无电荷时呈现截止转态(表示1).
- 通过控制栅极往其中充电,就可以把1转为0,这就是写入操作
- 要想从0转为1, 就好比乘船逆流而上要额外动力,需要在浮置栅极下面加一个20v偏置电压,把电荷拉出来,这就是特殊的擦除电路.
SSD磁盘的读写:
首先要明白, 到了闪存芯片时代, 严格来说, 已经没有传统的Sector (扇区)这种物理定义了, 实际的名称换成了Flash页(page)
但是对OS(操作系统)而言, 它是不需要关心底层块设备的物理单位的, 所以它还是用统一的logic sector 来标识/兼容, 很多人常说的固态磁盘4K扇区对齐, 扇区是说的逻辑意义上的名称, 因为说4K页(page)对齐又容易与OS的页概念混淆, 所以就成了目前这种尴尬的局面…. (但是我们得要搞清楚来龙去脉)
所以切勿用传统文章中谈磁盘(HDD)的概念照套入SSD, 很多都是不严谨或错的, 也不要把SSD自身的page/block 概念和OS中的混淆, 但我们可以简单认为SSD中的page, 近似为我们理解的磁盘最小操作单位 –> 物理扇区就行了
然后就是弄清SSD内部的关联关系, 一个SSD盘有多块flash芯片, 每个flash芯片有多个block, 每个block又是由多个page组成的, 如图所示:
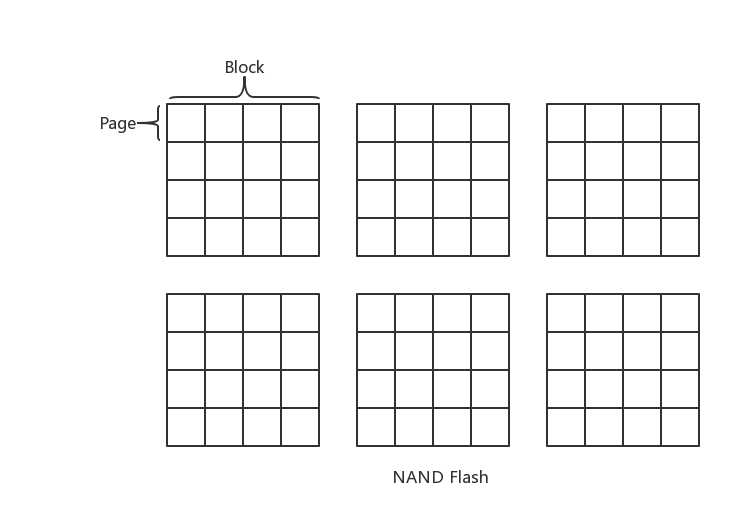
然后抽取某个block, 它是由多个(通常)是4K的page组成, 红色标识为损坏的page.
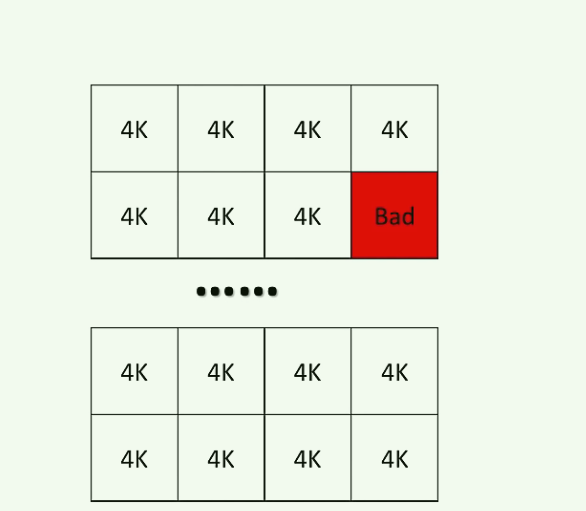
- 写是4k为单位, 一个个page写(n个4k), SSD有专门的磨损均衡控制器, 避免某个page被频繁访问. (OS里一般也是4K为一个page)
- 擦除必须是以块(block)为单位, 一般是1MB大小, 只能整体的进行擦除, 这个代价很高(所以SSD必须记得4k对齐) –> 比如如果想只更新10字节的数据, 是不能直接做到的
- SSD也有垃圾回收机制(GC), 在SSD空间较小的时候, 因为此时容易频繁触发GC (整理碎片**), 写放大效应会非常严重, 所以好的SSD都会有**预留空间
注意 : 不同厂商flash芯片不同, page/block容量不一定相同 (只能说SSD通常是4K)
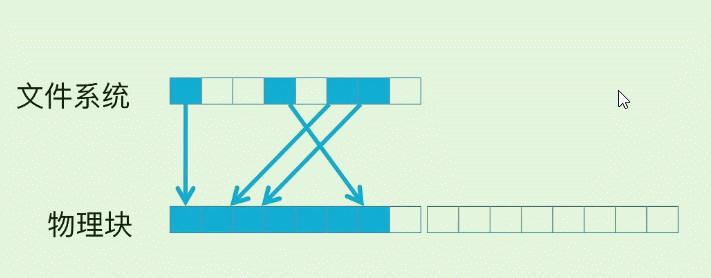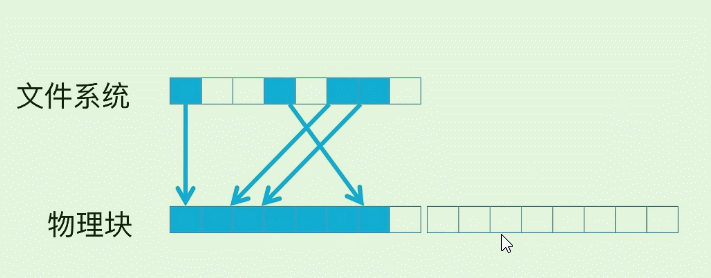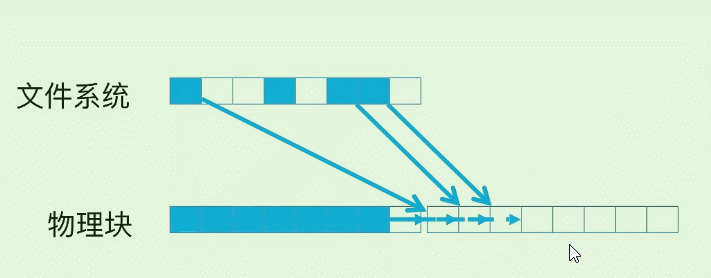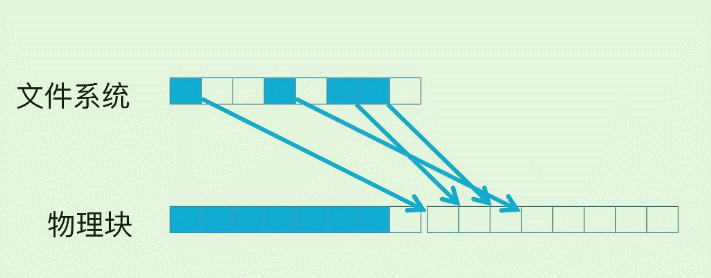
我们常用SSD就是随机读, 但是数据有冷热, 如果我们反复读取一个page, 那么这个hot page 会很容易损坏, 所以在FS(文件系统) –> 磁盘物理快之间存在一个映射. 使得SSD的修改操作实际按下面的方式在进行: (蓝色块为已存在数据)
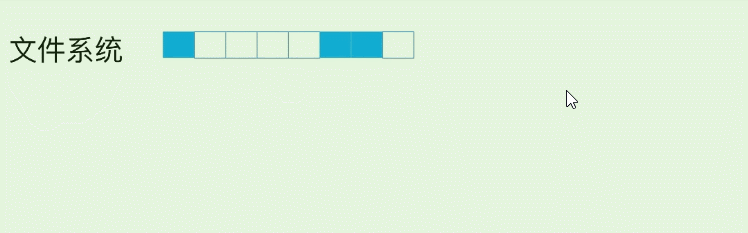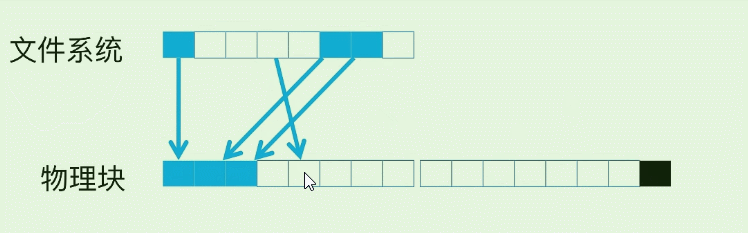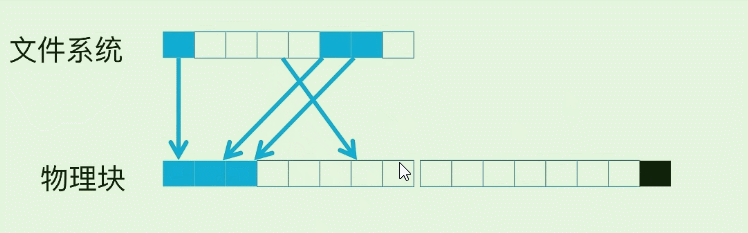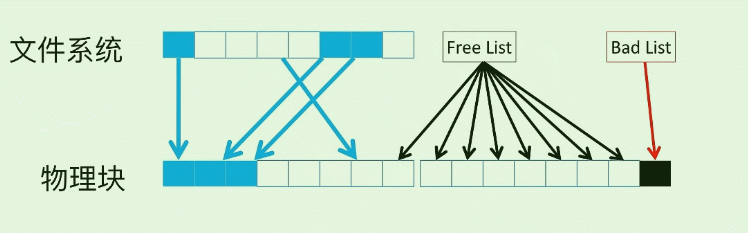
以第4个白色块为例, 假设它已经写入数据(变为蓝色 ), 然后之后每一次的修改. 并不会擦除旧数据, 而是先写到了下一个物理page, SSD控制器修改映射关系就可以了.
而在FS和SSD物理块之间的映射表, 就称为FTL(Flash Translation Layer), 它为了实现这种控制管理, 常有两个List管理:
- Free List 管理空闲的page (白色方块)
- Bad List 管理有损坏的page (黑色方块)
通过这种地址映射的方式, 每次读写都是通过逻辑地址算出物理地址, 而不用和HDD那样机械寻道+潜伏了… 节省了大量时间, 从而极大提高了随机读写的速度. 但是需要注意的是, 大量的更新操作, 对SSD的寿命是影响较大的.
写入放大效应
再回到上面那个问题, 如果想更新仅仅10字节数据, 之所以不能直接做到就是因为, 写入操作(1-->0)是容易的, 而更新相当于(0-->1), 这在SSD中须先大面积擦除(比如1MB的块空间), 显然代价太大, 那么实际要达到这个效果, 还是利用传统的 “读 -> 改 -> 写”的方式, 先从SSD中读1个4K的page到内存修改, 再写入到下一个4k的page.
那么实际只更新了10字节数据, 却花了总8K的IO, 这种大量的IO浪费就是写入放大效应的体现了, 如下动图所示:
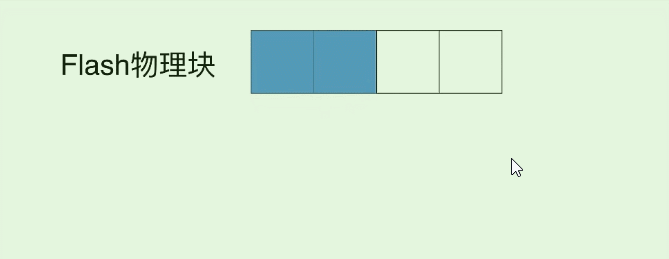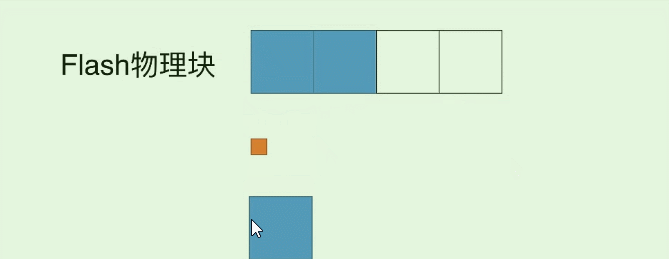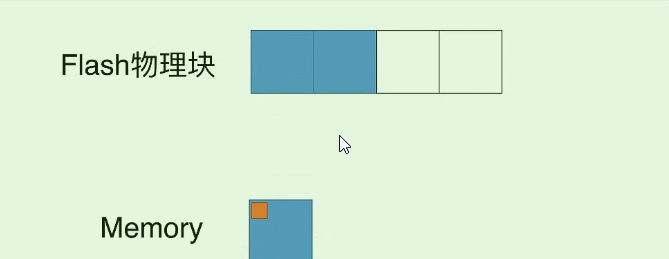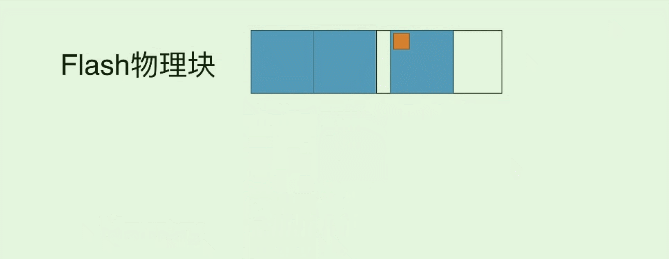
除了8K的IO, 这次更新实际还导致1份数据存在了两个page中 (之前的page是旧数据), 我们又称它为**”脏页(面)”, 而如果读到这个脏页的数据, 就称为“脏读”** (也就是读到了过时的数据) ,那么如果我们反复改写这个10字节的数据, 就会出现许多的脏页, 自然我们就希望清理一下它们, 那么实际在SSD中是这样做的:
- 比如修改第四个蓝块3次, 它就多了3个脏页. 导致原本的块空间利用率变低.
- 我们想把第一个块擦除, 但是块里还有其他4个page是有数据的, 那就必须先把这四个page的映射修改, 移动到空白的块的page里
- 最后再整体的把第一个块擦除掉. (整体类似JVM的”复制-删除”的GC模式)
这样的GC机制显然是可以很大提高SSD的磁盘利用率的, 但是同样它也有个隐患, 就是上面提到的—-当SSD空间很小的时候, 会出现极端的写入放大, 就算只写入几k的数据, 也会触发多次GC, 而每次GC都是1读1写1擦, 直到清理出充分的空间, 才会写入这几k的数据, 如下图是SSD剩余空间和写耗时的对比 :

所以就算是设计结构和性能远胜于HDD的固态硬盘, 也需要理解它大体的运行机制和原理. 才能避免出现这种隐藏的性能问题.
补充: 新硬件, 类似Intel和镁光合作的3D-Xpoint奥腾系列, 整个原理/设计以及性能跟SSD基本不相同, 关于它我只简单从intel的公开文中了解一二, 就不在这说了, 感兴趣的同学可以自查一下, 如果之后有机会接触, 我再单独写个笔记吧.
性能指标:
- IOPS (每秒磁盘读写次数—>
I/O per second) - Latency(延迟): 简单可以理解为处理每个请求的时间.
- Throughput(吞吐量) : 简单说可以理解为并发数, 某个服务1秒能接受的请求数.
传统HDD和SSD在这三个指标上的差别都非常大, 但是SSD成本比HDD高不少, 所以要根据具体场景合适的选择/搭配.
0x01. 基础信息
A. 硬件信息
查看磁盘的原始信息有时候也是很不容易的事, 比如最简单的, 这盘是机械还是固态, 多少的转速, 什么接口, 接口的版本, 使用的协议… 都可能很大影响实际的体验, 有一些集成好的命令帮你查看:
1 | # 准确信息还是要查官网 (通过型号) |
不过需要注意的是, 较新的硬件(3D-Xpoint, 或者Flash卡类的). 通过smartctl 很可能是无法直接识别的, 需要另外用单独的驱动/命令来识别.
B. 分区对齐(4K/nK)
这里一是说一下概念, 二是SSD的页(扇区)对齐的意义远比HDD大得多, 所以不管是Linux还是Windows下, 都应该让它分区对齐 (闪存写入/GC特性所致)
磁盘使用之前, 必须得先分区 ,然后格式化. 比如以前经常听到说把新买的电脑磁盘分成4个盘, C/D/E/F盘, 在这C/D/E/F就可以理解为把一个磁盘分成了多个”区” 它们的扇区分布其实是接近连续的, 如图所示:
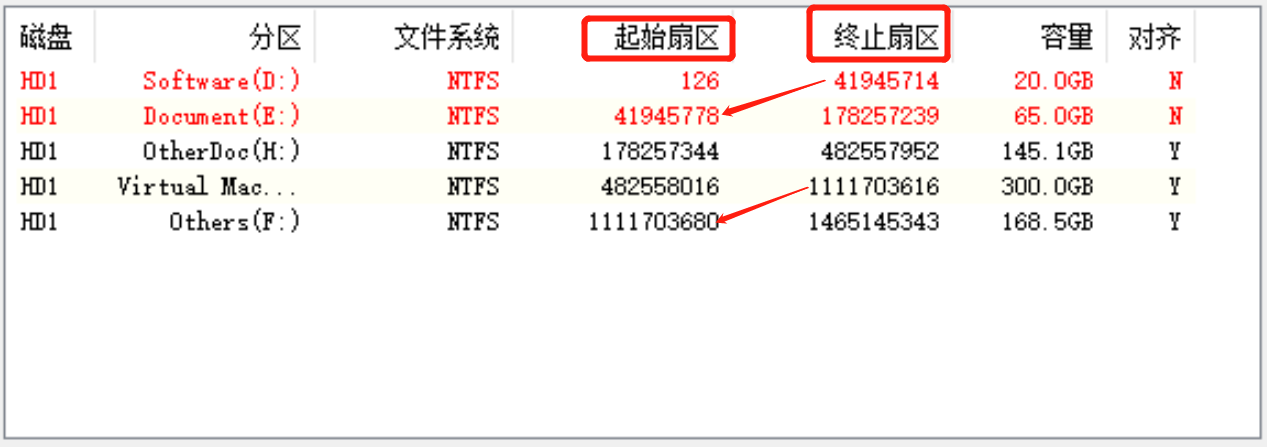
这里分区的可以简单理解为从磁盘空间划分出一大片连续扇区, 格式化则是进一步对这片扇区管理规划, (一般多与文件系统结合, 本质也是在初始化FS), 格式化完成后才能正常存储文件.
在格式化过程中, 如果是Windows的文件系统, 就有了一个新的概念—-“簇(cu)“, 这是之前对一大片连续扇区从头到尾的一个分组, 并顺序的编号, 如图所示:

如果熟悉Linux的同学, 可能就会发现这个”簇“很像Linux中常说的block , 它是文件系统操纵数据的最小单位(是一个抽象), 虽然我不确定二者是否完全等同, 不过从定义来看的确很相近. 它遵循FS的规定, 一个簇/block最多只能存储一个文件, 并且它必须是逻辑扇区的2n倍. 举个例子, 假设一个簇/block是2K, 存储以下三个不同大小的文件 ,它的实际存储占用可能是:
- 存储1字节的A文件, 它必须占一个簇/block, 也就是实际在磁盘里占了2K的空间
- 存储2K的B文件, 它正好占一个簇/block, 此时文件大小和磁盘占用空间2K相等
- 存储3K的C文件, 它必须占两个簇/block, 此时实际在磁盘里占了4K的空间
关于FS的设计这里就不多叙述了, 学习FS的时候再细说, 这里接着说分区+格式化后的两个问题:
- 为什么簇/块需要分区对齐, 它是和谁对齐, 不对齐会怎样 ?
- 如何对齐 ?
首先回到最开始的磁盘分区, 它从整个磁盘中划分一大片连续扇区, 但是这个起点是可以设置在某个任意编号的逻辑扇区的, 那如果设定的起点是从3号逻辑扇区开始的话, 就会出现如下所示的情况:

这样你会发现每个簇的开始和结束位置, 都和物理扇区是错开的, 也就是大家通常说的分区未对齐, 这样会有什么问题呢?
还是用之前的例子, 我要读/写1字节的A文件, 本来它由于远小于一个簇/block的大小, 就造成了很大的读写放大, (读写2K), 如果FS的分区还没有对齐, 那理论上无优化就需要读两个物理扇区 (比如扇区 0 + 扇区1), 造成可能4K读写的更大放大, 在读写小文件的时候性能损耗尤为明显.
那么显然, 让分区的起始位置随意设在一个逻辑扇区上是不合理的, 我们应该在格式化磁盘的时候, 设置分区起点与某个物理扇区对齐, 而为什么大家常说4K对齐, 只不过是因为大部分传统SSD和新的HDD默认是4K为物理扇区单位, 但是理解了原理之后就明白, 这个值是随物理扇区大小改变而改变的, 完整点说就是”分区起点与物理扇区对齐“ , 而由于分区多是文件系统/OS层面做的, OS操作的单位是逻辑扇区, 所以检测磁盘分区是否对齐, 就用它的 “起始值” % “物理扇区大小” 看是否为0就可以确定了. (方法参考磁盘信息查看)
0x02. 性能测试
这里要注意的是, IOPS-wiki怎么去定义, 怎么测试差别是非常大的… Wiki写的比较全面, 并附有常见的IOPS指标(当然仅供参考) .
速率测试工具:
dd (自带工具, 适合简单测试)
hdparm ( 测试读和缓存速度, 需单独安装, 更精准方便)
fio (全面测试磁盘性能, 时延/iops等, 推荐, 但需要注意每次读写的大小设置很可能不是4K)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35# cent上安装,fio的详细参数很多,需要查文档
sudo yum install -y epel-release #安装EPEL库
sudo yum install -y fio
# 1.测试随机读,不过数值比实际场景看似乎要高不少,可能需要进一步细化参数..
# 在当前磁盘测试目录下4k随机读50G文件测试 (超时时间120s)
fio -bs=4k -ioengine=libaio -iodepth=8 -direct=1 -rw=randread -runtime=120 -numjobs=1 -norandommap -randrepeat=0 -group_reporting -name=randread -size=50G -lockmem=1G -filename=./testRead1
# 2.顺序读
fio -filename=./testRead1 -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=512k -size=100G -numjobs=30 -runtime=1000 -group_reporting -name=mytest
# 3.随机写
fio -filename=./testWrite1 -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=4k -size=10G -numjobs=30 -runtime=1000 -group_reporting -name=mytest
# 4.顺序写
fio -filename=./testWrite2 -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=512k -size=100G -numjobs=30 -runtime=1000 -group_reporting -name=mytest
# 5. 混合随机读写
fio -filename=./testReadWrite -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=4k -size=10G -numjobs=30 -runtime=100 -group_reporting -name=mytest -ioscheduler=noop
# 备注: 常用参数说明
iodepth=8 # 默认1,读写文件的深度,暂时不确定
direct=1 # 测试过程绕过机器自带的buffer (不走内存)
rw=randwrite # 测试随机写的I/O
rw=randrw # 测试随机写和读的I/O
bs=16k # 单次io的块文件大小为16k, 随机读一般设为4k
bsrange=512-2048 # 同上,提定数据块的大小范围
size=5g # 本次的测试文件大小为5g
numjobs=30 # 本次的测试线程为30
runtime=1000 # 测试超时时间为1000秒,如果不指定则一直将5g文件写完为止
rwmixwrite=30 # 混合读写测试模式, 写占30%
lockmem=1g # 只使用1g内存进行测试
nrfiles=8 # 每个进程生成文件的数量为8
zero_buffers #用0初始化系统buffer
group_reporting # 汇总结果,显示每个进程iops (python写的快速测试磁盘IOPS性能的脚本. 优先推荐) 使用最简单,
./iops /dev/xx就能测这块磁盘(建议加-t 10参数)
效果如下图: (4T-HDD)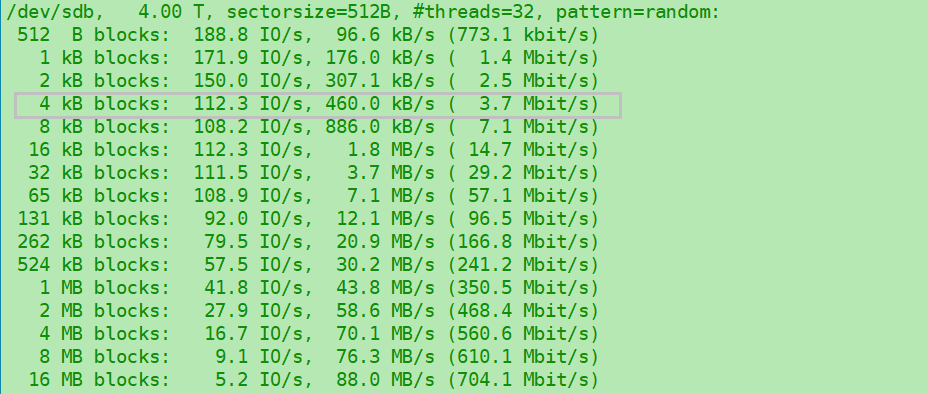 \
\
对比容量300G的12年intel SATA3-SSD, IOPS都是接近百倍的4k差别. (可以看到SSD原生4K单位物理扇区, 而HDD通常是512B)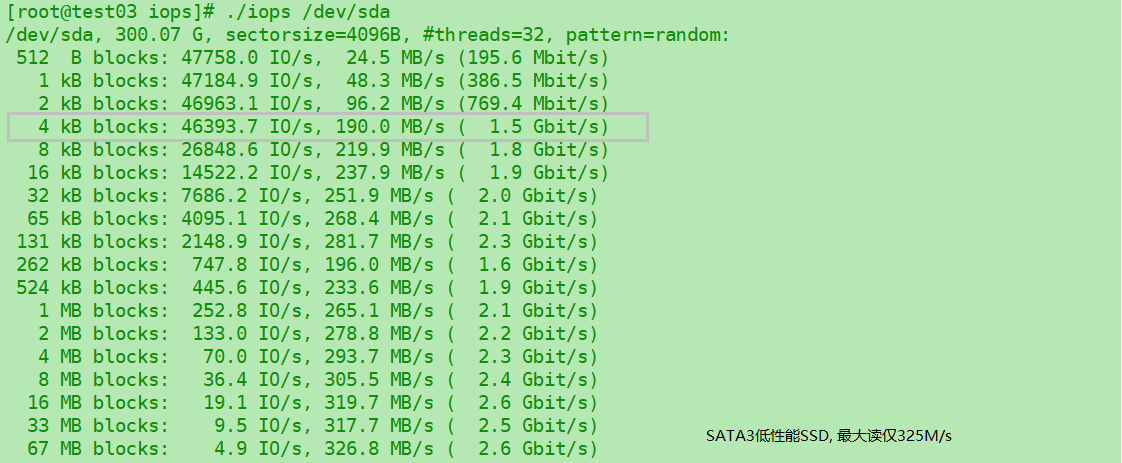
对比1T容量的17年Intel SATA3.1-6Gb/s 的SSD :

最后, 对比2T的PCIe接口的flash卡, 时延这里没有体现, 但是吞吐差别接近10倍, 而且中等大小文件的IOPS也比普通SSD高的多.
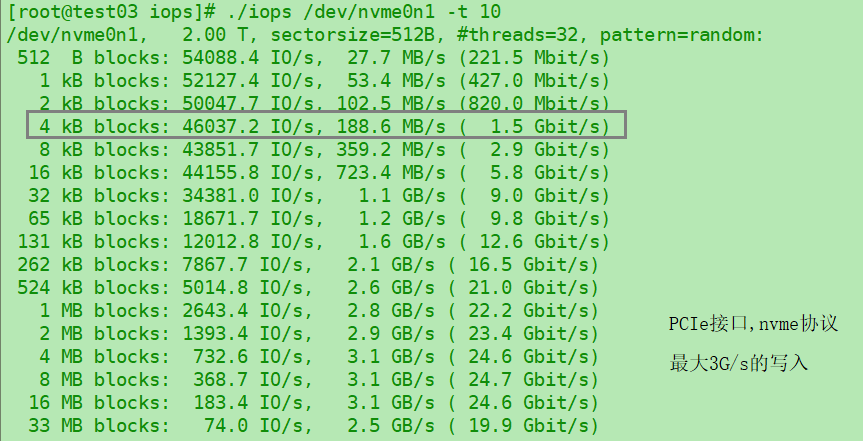
这里有个比较关键的地方, 就是我们实际读数据的时候, 是不是都按4K来计算? 大家都知道OS设计中一般是以4K为page的单位, SSD也是以4K为最小的page单位去读的, 但是这是不是意味着我们要随机读一段40K的数据, 就一定需要分开读10次page呢? 显然不是..
所以实际测试里, 我们需要特别关注程序本身, 到底是一次读多大的数据? 很可能并不是4K, 而是24K, 64K, 甚至128K… 这样做IOPS测试的时候, 就一定需要全面的考察一下, 而不是直接用fio测4k的读写, 得出的结论可能是有巨大偏差的 (普通SSD在4K和64K随机读相差了10倍的IOPS..)
更新: Hbase测试, 应该以64K为每次读的block单位对比, 而不是4K为大小.
补充 : fio也有一个可视化版本, 但是我觉得有点麻烦而且没啥必要.. 其他可视化的磁盘性能输出可以参考磁盘性能分析
0x03. 监控与分析
1. 磁盘监控三板斧:
- iostat : 一般个人常用
-cdmx 5的组合参数, 5s刷新一次. 观察整体磁盘使用情况.
1 | iostat -cdmx 5 |
- iotop : 定位哪些进程在使用磁盘 (本质是python从
/proc中获取进程IO信息.) - ioprofile : 又称
pt-ioprofile, 本质是strace进程然后进行IO分析, 用于更进一步定位使用磁盘的线程在读写什么文件.
(可选)dstat : 查看网卡/磁盘/CPU汇总信息 (彩色)
2.磁盘信息查看
因为看FS的时候发现磁盘和文件系统. 以及Linux/内核源码自身都有一些混用的概念, 所以需要区分一下..
硬盘: 最小存储单位是”扇区“ , HDD之前每个扇区默认是512字节, SSD常见4K, 这是物理定义存在的 (又称
physics sector, 物理扇区). 在磁盘驱动/固件中一般还会定义一个逻辑扇区的概念, 这才是上层服务能操纵操纵的最小单位.OS: 这里有几个关键点, 有问题请及时通知修正~
- 首先, 操作系统不一定有磁盘, 但它仍有一个”逻辑扇区“ (Logic sector)的定义/接口, 或者可能称为
Logic Block, 这里就混用了”block“ 和 “sector“ 的概念, 大家要注意甄别.. 它默认值一般是512字节的倍数, 但为了兼容旧磁盘, 一般取的512字节, 所以你会发现SSD盘物理扇区4K/16K, 逻辑扇区仍然是512字节, 也就是说从OS来看, 磁盘们(HDD/SSD)的扇区大小都是一样的. - 其次, 操作系统也不一定有FS, 但是它也有一个自身的
block定义, 比如在Page --> Buffer --> Block这个映射关系里, 最后block对应的是Linux自身的, 并非FS定义的, 只不过在有FS的时候, 它一般就取的FS的block size (存疑?)
- 首先, 操作系统不一定有磁盘, 但它仍有一个”逻辑扇区“ (Logic sector)的定义/接口, 或者可能称为
- 最后, 通常要求
sector size ≤ block size ≤ page size(这说block和page说的是OS层面的)
- FS: 文件系统有很清晰的
block定义, 并且这一定是逻辑上的抽象, 它是一个软件映射层的概念, 默认值一般是1K/4K, 这个值是指FS操纵数据的最小单位, 你读/写1字节, 文件系统也最少需要读/写一个block大小(4k), 但这个并不是真正的读写放大, 别混淆了.
注意: 新的HDD磁盘可能也是4K为物理扇区单位的(硬盘协会更新了标准, 但是不一定都采用了), SSD则已经到了16K为page单位(此时就应该是16K对齐), 所以文章中说的/画的图以后也很可能会过时, 大家切勿照搬硬套, 得与时俱进. 但只要搞清楚了它们的本质和来龙去脉, 再自己查/测一下确定就没啥问题
然后Linux上有个非常不错的命令blockdev来查看详细的这种磁盘相关信息, 还能查预读大小, 都是很关键的IO细节参数.
1 | # 查看/dev/sda设备的逻辑扇区大小 |

然后还有个常见的查看所有盘以及汇总信息的fdisk 命令
1 | # 查看所有磁盘汇总信息 |