在提升性能指标的路上, 缓存(Cache)占据了非常重要的地位, 从硬件到软件层面都是如此, 那么在图(Graph)里, 我们核心关注图的读写性能, 那缓存的设计, 以及它的合理使用就显得更加重要了. 接下来学习一下
Hugegraph中的缓存实现.
0x00. 前言
1. 简介
缓存本身也是一个比较容易在计算机各层混用的名词, 但是实际上很多人觉得 缓存 = 内存 , 或者Buffer = Cache , 这种理解是有很大问题的, 学习Huge的缓存设计之前, 可以看看这几篇帮助构建一下Cache的基本体系 (后续说的都是软件缓存).
然后之后有空 ,会接着补一下Guava 包中实现本地缓存的经典方式, 并对比一下和Huge 里实现的区别. (都是单机缓存 ?)
2. Huge的缓存
首先Huge的缓存设计思路采用的是经典的 LRU 淘汰模式, 也就是每次从缓存中把最长时间没人访问的数据T出去, 它和LFU最大的区别就在于. LRU根本判断条件是时间. 而LFU判断根本是使用次数.
当然, LRU也是一个大的分类, 可以结合一些其他的条件综合实现, 从而获得更好的缓存命中率, 比如相同时间删除数据大小更大的, 以及”使用时间+次数” 的LRU-K. , 或者是FIFO+LRU 的双队列实现, 详情可以参考一下LRU多种实现的对比 .
在Huge里有一个单独的cache 包, 里面有1个Cache 接口 + 3个封装 + 1个RamCache实现. 三个封装分别是:
- CachedSchemaTransaction (缓存图的Schema信息)
- CachedGraphTransaction (缓存图的点边数据)
- CacheManager (缓存管理器)
那么这样看整个设计就很清晰了: (估计)
- “接口+实现”负责实现缓存本身
- 点/边数据通过缓存管理器调用CachedGraphTransaction的方法进行缓存
- Schema数据通过缓存管理器调用CachedSchemaTransaction缓存.
- CacheManger类似一个守护进程, 每隔一段时间去观察/更新一下缓存状态
接下来就是验证一下猜想是否正确的吧..
补充: 包下还有一个CachedBackendStore 看起来原本是用于缓存图的数据, 但是目前已弃用.
0x01. 结构
先看缓存本身的实现, 再看如何调用. 在Huge里, 定义了一个Cache 接口, 确定之后缓存实现所需的方法 (如下图) :

可以看到核心就是缓存的CURD操作, 以及设置一些核心参数(缓存大小, 过期时间), 然后接着看看唯一的实现类RamCache的设计吧: (先看看概览图)
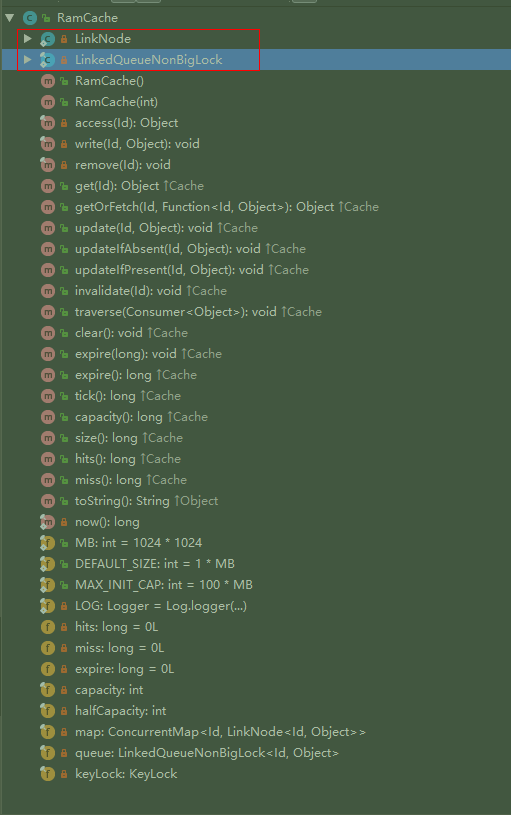
- 初始化一个map, 一个队列: (核心结构)
- map是 <100MB (
100*1024*1024个)的ConcurrentHashMap<Id, LinkNode<Id, Object>> - 队列是自己实现的的双向链队列 (名为
LinkedQueueNonBigLock<Id, Object>, 其中每个节点(LinkNode)都带有当前时间戳)
- map是 <100MB (
- 缓存的本质某个对象的Id和对象本身. 但是要注意的是, 这里Id除了常见的点/边Id, 还有比如某次查询对应的
QueryId,这样重复的查询, 就无需去缓存中多次查找每个点边, 而是一次把整个Query对象都取出来. - 通过包装的两个类来间接调用缓存的增删改查方法, 通过守护进程定时清理过期缓存.
整体的实现思路就是: 双向链表 + Hash表(加速查找), 类似的组合结构是LinkedHashMap, 然后除了默认的队满淘汰, 还带上了一个定时器, 定时淘汰超时的缓存.
0x02. 核心代码
先看看缓存最核心读写实现 (修改本质是覆盖写, 删除就是出队, 不单独说了~) :
1. 写入缓存
以下是精简后的核心过程.
1 | private final void write(Id id, Object value) { |
这里其他过程都很清晰, 就是如果其他线程同一时间写入, 则导致出栈元素为空时, 为何要清空整个map. 这里还不太理解… 待确定
2. 读取缓存
1 | private final Object access(Id id) { |
这里跟标准的LRU的区别就在于设置了一个halfCapacity . 原本LRU每次读取都会在链表里移动这个元素到队尾, 如图所示:

当然, 这里因为使用了Map记录了数据的前后指针, 所以移动也可以认为是O(1)的, 无需遍历链表. 这里的优化是: 设定当缓存还算充裕(多于一半)的时候, 退化为FIFO… 不去重新移动和计算队列, 也不加锁, 这样读取效率理论上会提高一些. 不过具体比例不确定.
之前接口里其实有一个方法名比较奇怪, 名为tick() (Tick-Tok) , 我想了想, 翻译为定时操作….可能比较合适? (时钟滴-答的循环)
在LinkNode 的结构里, 每个节点初始化的时候都会携带一个当前时间戳, 它就是在tick() 函数中被用来计算过期时间的, 然后它又是CacheManager 初始化的时候调用的, 借助Timer对象后台执行, 达到定时检查缓存是否过期, 以及移除过期对象的效果 :
1 | public long tick() { |
至于双向链队的结构, 除了加了一个自己封装的KeyLock 锁对象, 其他暂时没看到有什么特殊设计, 就不单独讲数据结构了.. 有兴趣可以参考源码1,源码2
0x03. 图使用缓存
上面已经把Hugegraph中的缓存设计和实现大体说完了, 这里再举个具体的例子, 比如之前说的K步邻居查询, 或者某条gremlin查询后, 在Huge里是如何缓存的? 当然这里其实只是一个函数调用了.
以K步邻居核心过程, 查某个点的所有边为例, 最后会调用queryEdgesFromBackend() , 这种操作都是属于GraphTransaction ,而这些都在CachedGraphTransaction 中进行了重写, 例如下面就同时展示了读写缓存在图里的使用方式:
1 |
|
至于Schema的缓存读写, 大体也是类似的, 细节稍有不同, 就不重复说了. (gremlin缓存的例子待补, 还没看)
0x04. 总结与展望
A. 小结
总体来说, Hugegraph里的缓存设计是实现了传统的LRU的淘汰策略, 并做了一些小改进, 然后缓存过期通过原生的Timer 定时检查并剔除的, 那么我们之前的假想, 如果想通过内存(空间)换时间. 就等于是给了一个非常大的HashMap ,而Java在处理一个如此大的HashMap对象的时候, JVM在内存管理应该会变得很难处理, 也容易出现问题.. (待确认)
所以如果想在Huge里比如用很大(100G+)内存来做缓存, 可能还是用redis/memcache 这样的分布式缓存, 或者存储自身的缓存要好的多, 图本身则可以用来缓存更结构化的数据, 例如:
- 图的Schema信息. (缓存命中率极高, 频繁)
- 图的Query/Path/Traverser信息. (比如上面的例子, 但是不缓存实际大量的点边数据)
- 子图信息 (…如果之后支持子图相关算法, 包括社群发现, Pagerank迭代的时候复用?)
B. 展望
缓存算法策略里最常见的就是LRU和LFU, 一个按访问时间排序, 一个按访问次数排序, 一般认为 LFU 的特性更适合离散/随机化的场景, 感觉图的遍历(大部分业务)应该是比较符合这种场景的, 实际使用来看, LRU的缓存命中率极低 (<1%), 这使得我不禁思考, 是否应该默认使用 LFU 作为缓存策略, 或者其他更适合随机读场景的策略呢?
另外还有几个可以改进的地方:
- 使用堆外缓存, 避免JVM管理超过32G的巨型Map.
- 使用多级缓存
- 使用分布式缓存, 多个Server间可以共享(类似Redis)
更新: 最新版本的 hugegraph, 已经同时将上述1/2改进部分实现, 默认会使用 OHC 来堆外管理大缓存, 感兴趣的话可以看新的源码.
参考资料:
主要见前言-简介部分, 其它参考Hugegraph源码实现.