Hbase是大数据生态分布式现在的主流存储, 而它有一个高级功能可以实现代码逻辑的执行, 称之为协处理器(coprocessor), 这次尝试通过它, 看看能否实现图数据库计算的下推 (从而实现分布式计算的效果), 这是第一篇介绍背景和使用.
0x00. 简介
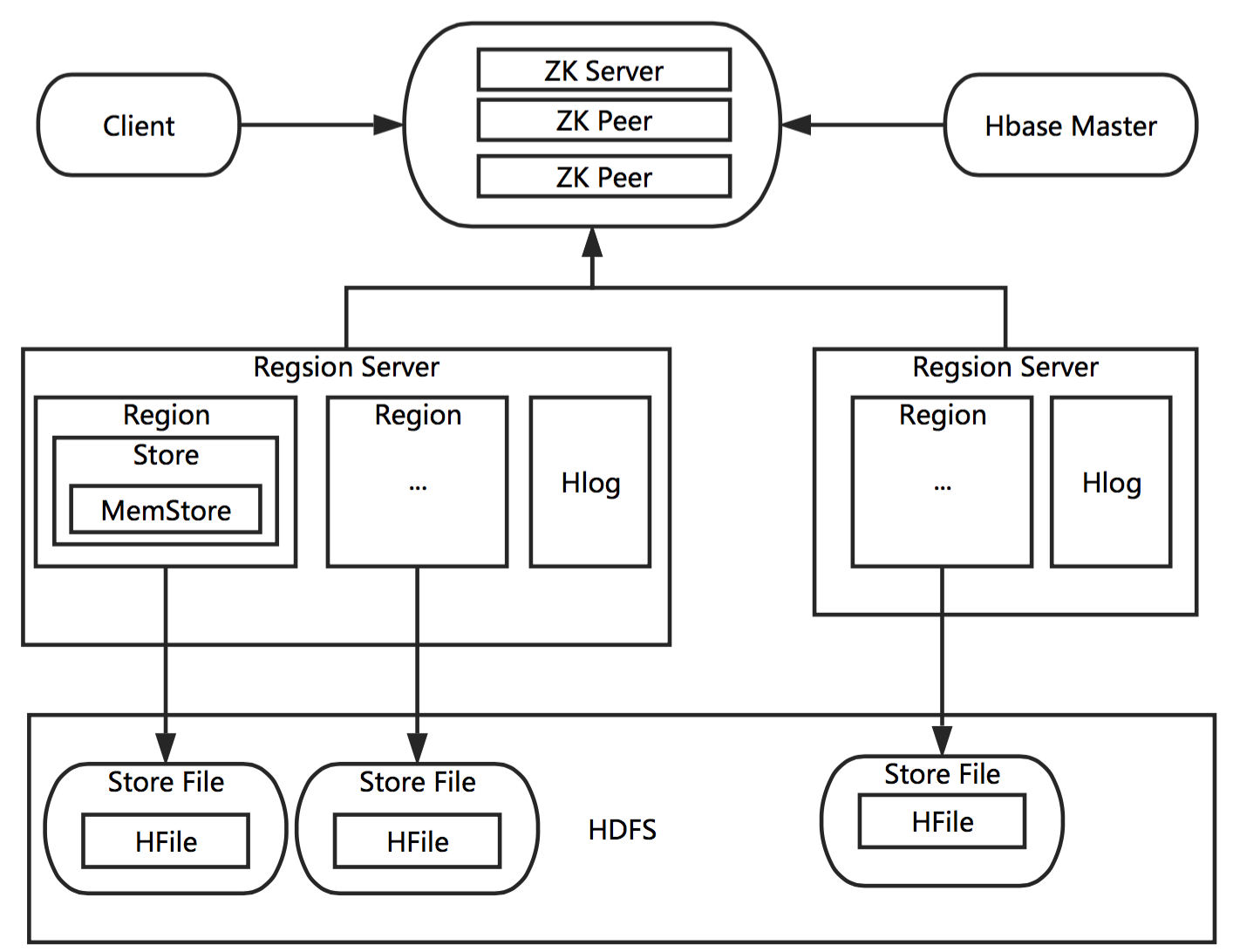
前言附上一张简洁的Hbase 全貌结构图:
然后在关系型DB中, 我们有学习过**”存储过程”** 和 “触发器” 的概念, 前者常是后端把一系列固定的操作下沉到DB层面, 降低RPC次数, 并且易于复用, 后者我觉得更像一个钩子(虽然我基本没用过它.. ) 以上二者在Hbase中的体现, 就被统称为”协处理器“ (coprocessor) . (推出于0.92版之后)
上面说的是类似点, 那不同之处呢? 从单词上可以看出一个它有一个前缀co , 那也就是不同于传统关系型DB的的地方, 它的”存储过程”代码是可以分布式执行的(在每台server上), 甚至有负载均衡 + 请求路由这样的功能, 和MR(Map-Reduce)有不少相似之处:
类似的, Hbase把协处理器划分为了两种:
- 类存储过程执行代码: endpoint 协处理器
- 类触发器: observer 处理器
我们目前关注的自然是第一种, 也就是后面主要说的都是endpoint 的设计和使用. (不过有些时候是需要二者结合的, 虽然核心还是endpoint)
补充:
- 开发环境基于
HDFS3.x + Hbase2.x, 低版本可能有许多不同的地方(因为JDK版本也有大差别了), 注意甄别. (网上绝大多数文章基于0.x/1.x版本, 切勿照套) - Hbase2.0的核心读写实现可以参考NoSQL漫谈Hbase系列, 毕大写的真的很好. (这是对应的PPT合集)
0x01. 结构
1. 整体模型
endpoint 底层使用protobuf实现, 不过在了解底层之前, 先得对协处理器有个整体的认识, 这里先引用一张官方Blog的图:
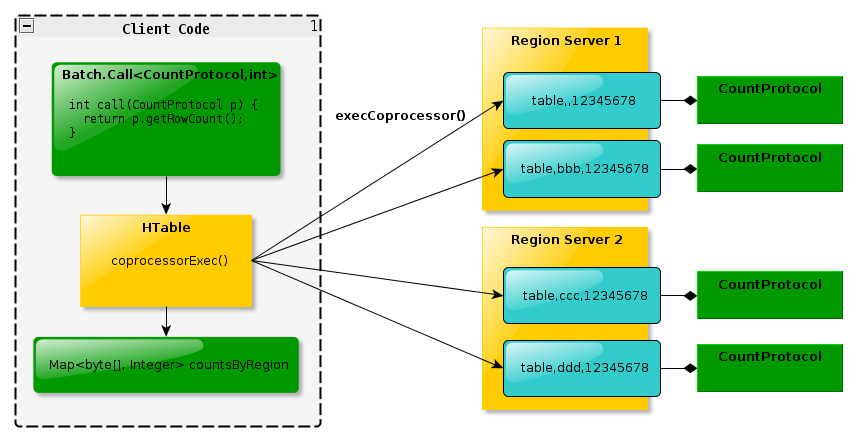
其实这个模型也很类似Map-Reduce的模型, 不过需要注意的是, 在多个Region Server (后面简称RS)上分别计算之后的值并不会返回给Hbase-Master(后面简称HMaster), 而是直接返回给Client, 在Client做聚合/处理操作, 最简单的例子就是统计所有服务器上最大的一个数值, 那么就是每个RS算完之后返回一个最大值给Client, 再找出最大值.
3. 加载方式
协处理器有静态/动态/API三种加载方式,官方介绍了前面两种, 这里汇总一下全部写法..
静态加载: 通过在
hbase-site.xml里添加字段, 实现启动时全局影响, 多个类可以用,分隔.1
2
3
4<property>
<name>hbase.coprocessor.user.region.classes</name>
<value>org.apache.hadoop.hbase.coprocessor.AggregateImplementation</value>
</property>使用
hbase-shell针对某个特定表开启. 三步走: (测试推荐, 简单快捷)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 1.disable当前表
hbase> disable 'tableName'
# 2.1加载写好的协处理器类 (通常是hdfs路径,priority可省)
hbase> alter 'tableName',METHOD=>'table_att','coprocessor'=>'fullJarPath|fullClassName|priority|args|'
#实际写法例如:
alter 'huge_test:graph_v',METHOD=>'table_att','coprocessor'=>'/home/test/hbase_cop-1.0.jar|coprocessor.server.ReadRSEndpoint||'
#如成功, 会提示Updating all regions with the new schema... All regions updated. Done
# 2.2删除协处理器 (二选一)
hbase> alter 'tableName',METHOD=>'table_att_unset',NAME => 'coprocessor$1'
# 3.enable当前表
hbase> enable 'tableName'
# 可以desc看看
hbase> desc 'tableName'我们实际编程里也可以考虑使用第三种, API直接调用 (注: 注释部分为
Hbsae1.x版本API,很多方法已经过时, 但考虑兼容还是保留一下)
1 | // 添加Hbase协处理器 (Adaptor for Hbase2) |
开启如果成功, 在Hbase的前端页面Table Description 中应该可以看到对应内容 (命令下desc 同理)
4. 实现步骤:
- 定义一个接口文件
EndPointXxx.proto用于自动生成接口定义类EndPointXxx.java. - Server端编写一个类实现协处理器接口, 打包上传.
- 动态加载实现好的协处理类
- Client端调用协处理器, 使它开始工作
4.4 Client调用协处理器
这里比较关键的是第四点, 也就是如何在Client使用协处理器. 这里主要通过HTable 的coprocessorService 来实现, 而它有三种入参选择(需要理解区别) :
调用单个Region的协处理器, 标准Hbase-RPC调用
调用多个Region, 但不使用回调(callback)
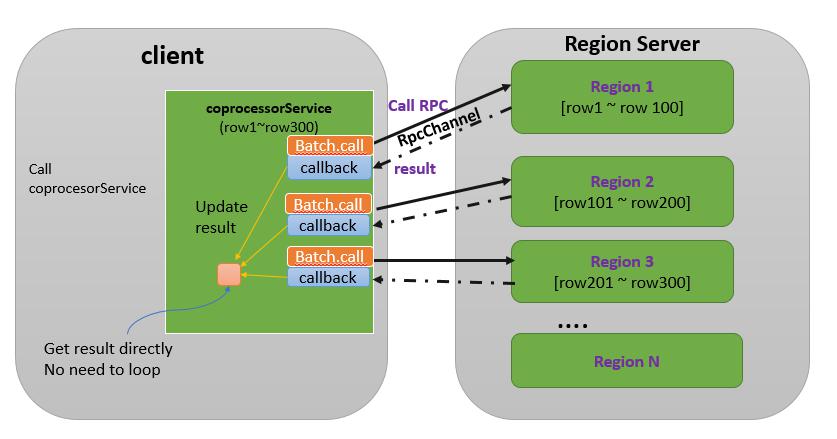
(常用)调用多个Region, 且使用回调(callback), 参考下图:
然后,如果是访问多个RS(RegionServer), 还可以使用更高效的batchCoprocessorService , 这样访问一个RS的多个Region就只需要一次RPC, 而上面的调用方式, 访问每个Region都需要一次RPC, 理论上我们应该使用的是这种方式, 参考如图: (待确认?)
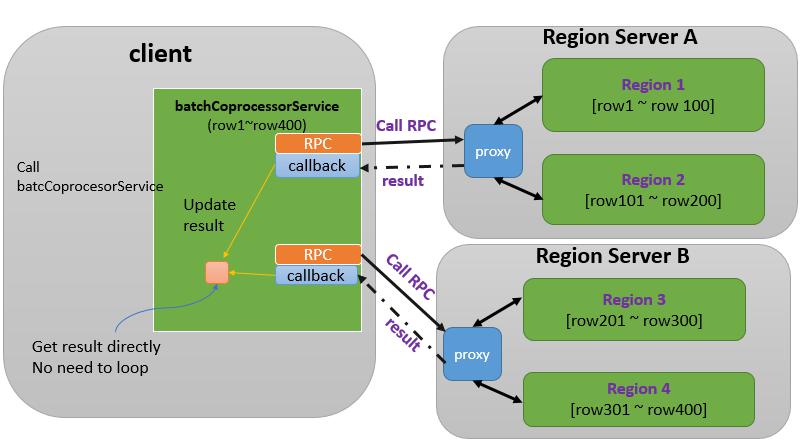
但是关于下面batchCoprocessorService的资料少的可怜, 所以先按常见的默认写, 再对比看看现在是不是这样吧(图引自Hbase1.x版, 新版实现和区别待确定) ,
待代码确认补充
0x02. 准备
因为协处理器的使用依赖一个框架, 所以在看看多个RegionServer之间能否互相访问读取数据之前, 我们先得做好准备, 这样之后就可以专注于开发了.
PS: 之后再考虑实现两个简单好理解的demo, 一个是统计所有节点总行数, 一个是统计某个最大值?
首先构建一个合适的pom 文件, 注意Protobuf Hbase官方使用的非最新3.x的版本, 所以请使用protobuf2的语法. (下面是可参考的依赖, 注意包版本)
1 | <properties> |
最后编译的插件自行补充, 我就不单独贴了(网上或者书上说需要依赖hbase-server ,或者protobuf , 或其他依赖都可无视..因为没有一个是基于Hbase2.0的 )
然后就是把protobuf用起来也并不艰难, 核心就三步:
- 定义一个合适的
.proto文件 (如何写参考官方文档和Hbase-protobuf-example) - 使用protobuf编译器编译它生成对应的java文件
- 使用Java的protobuf-API包去进行读写
官方demo学习
最新版的Protobuf使用非常简单, 下载解压包Protobuf后, 编写一个proto文件, 然后一行命令编译就行. 无需再做其他操作. (Mac也可以用Maven方式编译)
先看看官方提供的Examples.proto 写法: (头部不声明的话, 默认使用的是proto2的语法, 变量须有两个关键字)
1 | option java_package = "org.apache.hadoop.hbase.coprocessor.example.generated"; |
新建两个文件夹, 例如input 和 output , 前者存放proto 文件, 后者存放编译后生成的java文件. 然后在protobuf-3.7.1 目录下执行一行命令 :
1 | protoc -I=../input --java_out=../output ../input/Examples.proto |
目前来看, Hbase2.x上是不建议一起打依赖包的, 会发生奇怪难以定位的包加载冲突问题, 导致协处理器甚至无法正常加载, 直接打裸包就正常 (网上说打依赖包可能适合旧版本..)
1 | mvn clean install #可不用-Dmaven.test.skip=true |
然后把包上传到HDFS目录, 方便之后从API或HShell读取
1 | hadoop fs -put hbase-cpr1.0.jar /home/test |
0x03. 运用
然后再试着跟图本身进行结合, 从图的表里直接读取数据. 并且尝试把RS自身当成一个客户端, 从而每个RS可以自由访问其它RS上的数据.
1.编写protobuf文件
新建文件命名为ReadRS.proto ,然后根据需要, 思考我们要哪些方法, 传入哪些参数, 接受哪些返回值. 参考官方文档, (zh-version.), 下面是个我写的实际例子:
1 | option java_package = "protobuf"; |
写完用上面protoc 的命令就可生成一个ReadRSProtos.java文件放进项目的protobuf包下了, 然后创建一个Server
2. 编写Server程序
这里其实就是编写协处理器的执行核心, 叫Server 是为了方便和Client 对应, 好理解一点. 比如我们要写一个ReadRSEndpoint类. 到时候让Hbase加载它, 让Client可以调用到, 这里放一下核心的代码, 完整代码可参考git. (这里为了更多的体验Cop的功能, 把几个功能都综合写了一下 , 也是方便对比和查看区别)
1 |
|
3. 编写Client程序
同样, 这是client端接受和发送请求的核心部分:
1 | public void readRS(final Table table, String... strs) throws Throwable { |
更新: 由于内部 sec 要求, 文章开放后移除了与图数据库 + hbase 实现 kstep 下推的相关代码 (详见公司内分享及代码)
0x04. Q&A
1.更新了协处理器的内容覆盖上传, 为什么还是执行历史代码?
更换jar包的版本是最靠谱的做法:
每次修改了协处理器打包时, 更新一下版本比如V1.0 –>V1.1 . 可能是Hbase自身缓存可能就会出现类似问题? 很蛋疼
2. Win上运行的时候提示Hadoop环境不存在
参考此文, 实际上这个报错你不管一般也没什么本质影响, 而且我也很不建议在win的环境安装Hadoop … 但是那一大堆的报错实在糟心, 有什么办法解决么?
我发现可以通过设置巧妙利用log4j绕开它…让那一大堆报错不输出, 而不是浪费时间去配Hadoop环境变量 , 个人做法如下: 使用log4j需要一个对应的配置文件, 来设置相关日志参数log4j.properties, 我们修改日志输出为OFF ,就不会抛出那一大堆的错误/警告了.
1 | #添加/修改这一行就行 |
3. protobuf中设置List属性的时候报错
这里注意几点:
- list的属性, 不要使用
setXxx(index, value), 这样直接使用会报数组越界, 应使用add(value) - list的属性, 不要设置
null值(add(null)), 这样序列化的过程会有NPE(空指针)报错导致需要重新打包, 所以就算是测试也别传任何空进去.
参考资料: