本篇是第一篇介绍 PA1.2, 在初次体验了红白机的乐趣之后, 又来整相对硬核的东西了, 本节核心聚焦在 C 中的汇编上.
0x00. 前言
汇编对绝大部分同学来说可以理解为噩梦, 基本是完全不想看或学习的存在, 但是巧的是 PA 课程比入门汇编要难得多, 加之汇编对理解计算机原理和 C 又有莫大帮助, 所以不管喜欢与否, 都得把它捡起来. 这里针对课程需要, 重点回顾:
- 回顾简单的内存模型 (结合 OS 会更好)
- X86 Linux/Unix 下的经典汇编, 它和 OS 关系也紧密
- C 内联汇编
- 课程所需
RISC-V下的汇编指令 (可能单独拆分)
PS: 有条件的同学可以对着 CSAPP 书补补, 会有极大帮助, 或者说 CSAPP 应该是一本当之无愧适合所有计算机科学的同学都必读的书, 虽然 SICP 可能名气更大也更被推崇, 但是 CSAPP 的确是最打基础和全面认识计算机的一本了..
0x01. X86汇编
X86 汇编常见 intel 写法和 AT&T 写法, Unix 下通常使用后者, intel 标准语法简洁点, 寄存器不用加
%, 也不带l等后缀, 大体都能理解, 运算方向二者相反, 详细建议参考一下经典文档, 把例子自己写一下基本就清楚了, 后续会在代码里注释为了加深理解和记忆, 例子中可能交错出现, 但不会混用, 也不会大写~ 何况后面的 RISC-V 汇编语法又不一样
0. 内存模型
在冯诺依曼体系里最关键的两个器件就是 CPU(计算) 和内存(存储), CPU 一条条的执行汇编指令, 会产生很多中间的临时结果需要存储, 最直接的就是放在各种寄存器中,但寄存器造价高 & 数量非常有限, 只能存储极少数据.
另外, 一个稍复杂的程序都会涉及到判断/跳转/循环等操作, 这些操作需要有序执行, 就需要有地方来存储执行的步骤等基本信息, 那大部分就在内存中存储, 它也是 OS 中 “进程内存管理” 的一部分. 简化起见, 先只关注程序运行过程中的存储空间/模型. 为了方便理解, 一般都是画一个内存 Stack 简图, 假设划分了一段地址连续的内存, 然后往里面存取值. 并根据是否主动申请划分为堆和栈两类:
- 用户/程序主动申请/释放的内存空间, 一般在 heap 上 (malloc, new, free)
- 程序运行自发申请的空间, 一般放在 stack 上 (临时变量, 函数执行帧等)
然后堆和栈使用内存的时候方向相反, heap 从低地址→高地址分配, 而 stack 从高地址→低地址分, 然后在图中体现就是, stack 在一段内存的底部(起始), heap 则在一段内存的顶部(结束), 但实际上二者的使用方式差别挺大 (我觉得先分开来理解是更好, 画在一起给人的感觉 heap 也像一个栈了) 简单起见, 在初识汇编的时候可只管 stack 的存在:
假设一段内存就是 stack 专用的, 然后它从高地址→低地址去放元素. 也就是说高地址是栈底, 最先进入的元素放在这, 然后后续新增的元素地址逐渐降低 (看起来又像是一个倒着的 stack, 如下图所示, 底部的实现可去掉其实..)
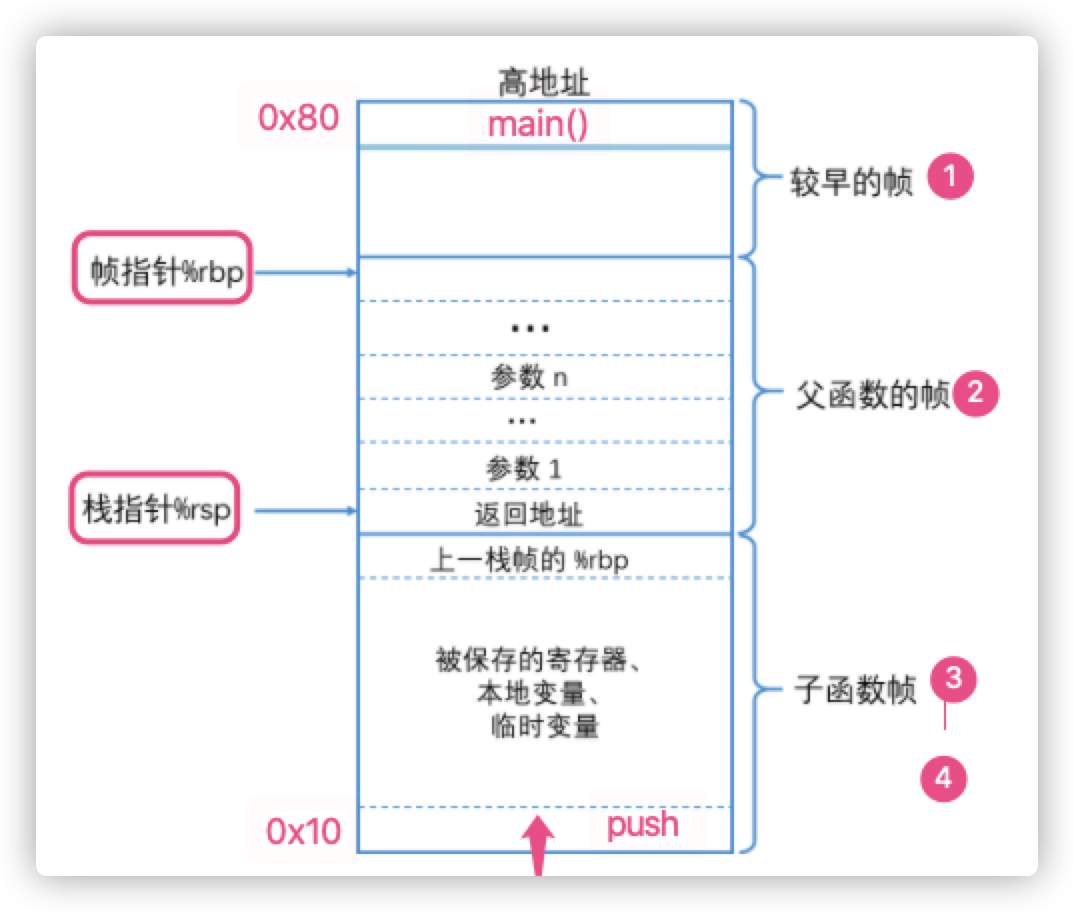
注: 关于内存 stack 的图画法不一, 有些å把高地址画上面, 有些把低地址画上面, 有些把 Heap 和 Stack 分开, 有些又画在一起, 没理解时直接看文章很容易混淆, 实际只是侧重点/理解角度不同导致. 所以一定要自己动手画图并对者汇编代码来确认.
1. Demo
简单的定义一个 32 位下两数相加的 c 程序, 然后它的简化后汇编核心: (x64 下一般把 e 换成了 r, 比如 esp –> rsp)
1 | # 修正自 RYF 的例子, 采用 intel 语法. (Unix/Mac 下操作顺序相反) |
大体在 stack 上的内存使用是:
- 给
_main函数建立一个 frame, 然后把 stack 当前地址写入地址寄存器 esp 中
附 CSAPP 书中的整数寄存器实际结构截图: (可以从这也看出 rbp –> ebp 的低位兼容关系, 采用 AT&T 语法)

在 x64 环境下, 看到 exx 的寄存器, 实际也应该就是 rxx 寄存器的低32位兼容使用, 就算指定 eax, 实际也多是用的 rax
这里 rbp/ebp 就是 frame pointer, 简单说类似 *cur (当前帧地址), 而 rsp/esp 就是 stack pointer, 简单说类似 *start (首地址), 所以它两组合就确定了一个 frame 的首尾地址, 对它们的操作也是最频繁的.
2. 常见指令
这里列一下常见的 asm 指令, 其它用到时查手册, 为简单使用 intel 写法 (略去 % ), 大部分是全称缩写, 记全称即可理解
push & pop: 压/弹帧
1 | push 1 # 把 1 压入栈中 (占4B?) |
mov/lea: 赋值 / 赋地址
1 | # 使用最多的汇编指令, 等同于 = (赋值符号) |
add / sub / cmp : 算术指令
1 | # 最常见的是加减法, 结果保存在首个寄存器 |
call: 调用函数(地址)
cmp/jmp / jnz / jz: 比较 & 跳转(地址)
1 | # cmp 全称 compare? 它会对两个参数做减法 |
ret / leave / int: 结束中断等
1 | # ret -- return, int -- interrupt (软)中断指令 |
如果看到一个汇编指令比较陌生但表义清楚, 很可能它是组合封装的指令, 并非默认自带, 检查查阅即可, 无需纠结.
3. 常见声明
实际在 Unix 中我们编译了简单的 c 代码后, 查看汇编会发现有很多奇怪的部分, 不用太紧张, 大部分也不用太关心, 常见 ELF 格式的汇编文件有如下 . 开头的特殊指示字段(asm directive):
.text表示只读可执行的代码段.data表示可读写的数据段.global表示当前段入口函数
x. 汇编神器
传统查看汇编的方式一般基于 objdump 和 gcc -g 编译的汇编, 在不同平台不同语法, 特别是 ARM/Intel 阵营都需要了解后, 对比起来会十分费劲, 掌握了基本的查看代码和汇编映射后, 推荐一个在线的神器工具方便多平台/语法快速对比代码和汇编, 效果如图:
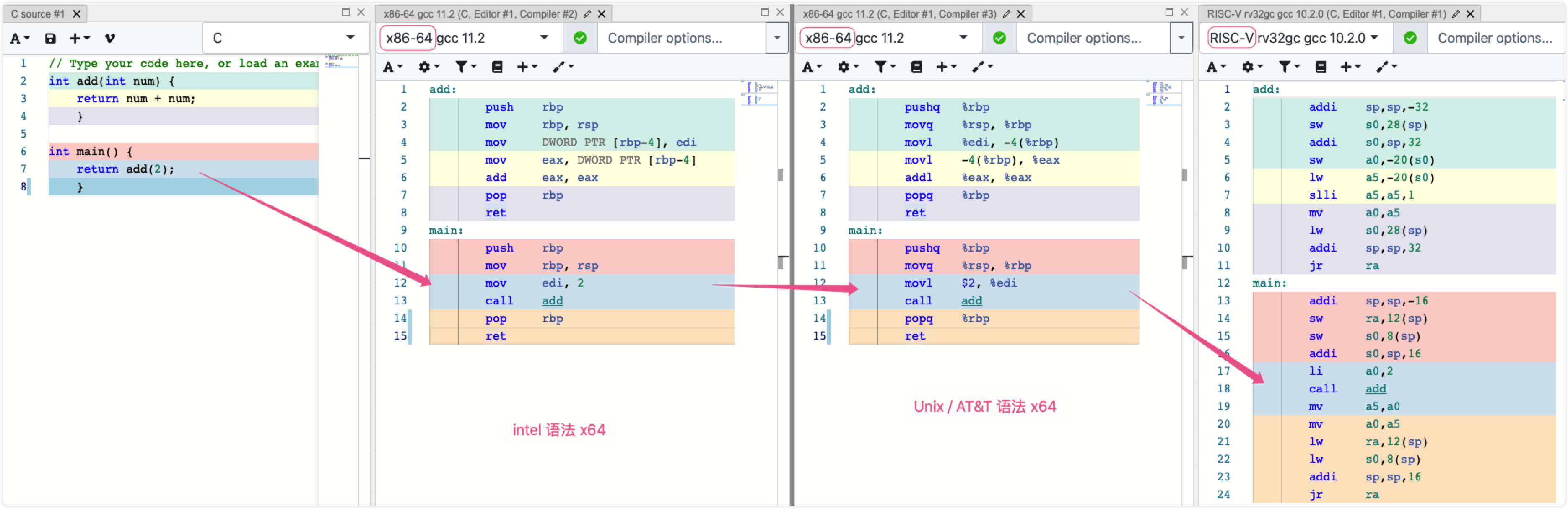
它并非仅支持 C系, 而是支持大部分语言, 而且 UI 很简洁优雅, 值得尝试. (其他强大功能可自行探索~)
0x02. 内联汇编
不管啥语言, 内联汇编的好处无需多提, 只在硬件/性能相关度高的地方嵌入汇编代码, 同时保证开发速度与性能, 在 Linux 内核代码体现的淋漓尽致. 但计算机世界并没有 AI, 内联汇编并不是听起来这么简单好操作的, 往往比纯汇编要复杂的多.
以 C 为例, 常见的内联汇编格式是引入 __asm__(asm code); [也可直接 asm() ], 且因为引入寄存器后通常还要与普通变量进行交互, 所以它常见的完整/扩展格式是 __asm__(asm code : outPara : inPara : registers); 后三个部分都可选, 没有就留空 : 即可. 看起来不复杂
但是实际大家直接看到实际的内联汇编的时候, 第一感觉就是 “WTH?” 因为在第二 ~ 第四个参数, 都有一堆限制符缩写然后各种符号叠加, 裸看自然觉得像天书, 但别担心, 循序渐进看就正常多了, 先看看简单例子:
1 |
|
基本语法看经典文档. 然后这里补充一下文章没细说的:
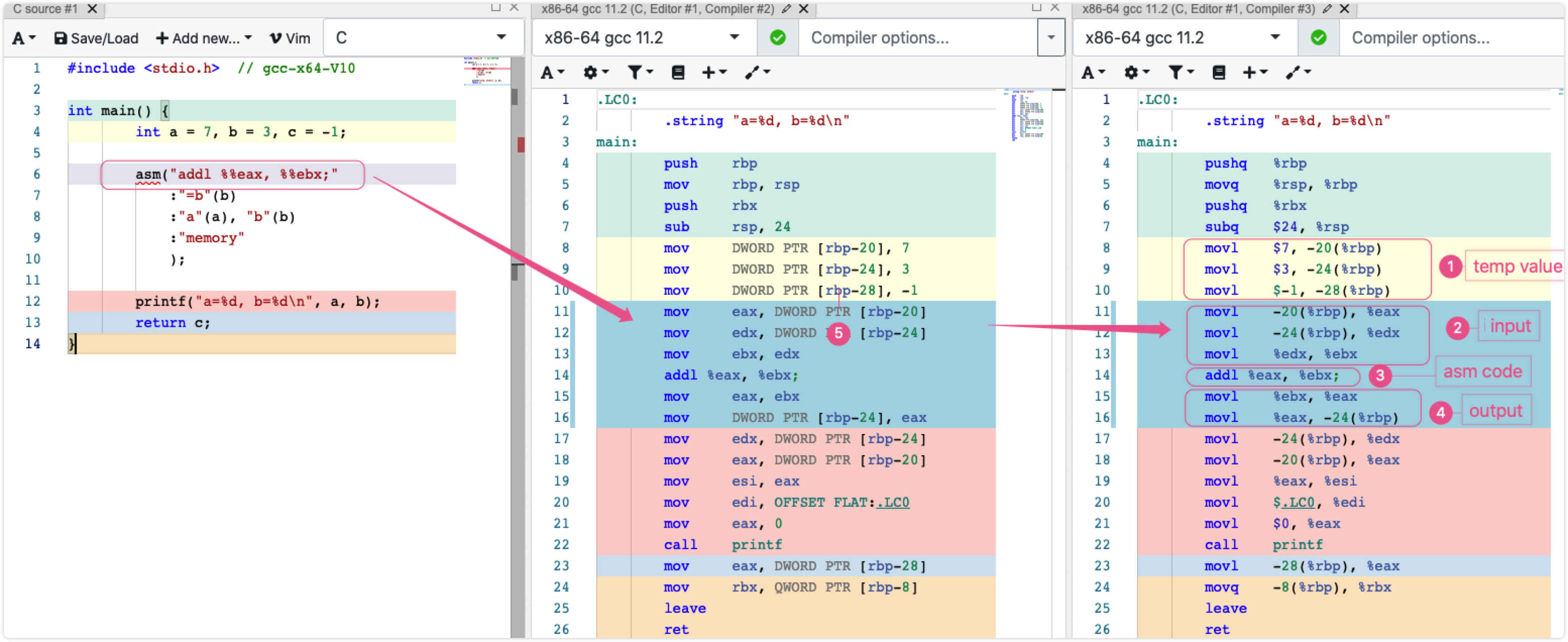
- 第一个就是汇编命令, 只不过多行的时候要么用
;分隔, 要么需要不好看的\n\t, 我一般习惯前者.. (下图③) - 第二参数确定改变哪些原有 C 变量的输出值, 简单说就是 asm 里影响的寄存器, 需要把哪些搬到 asm 外 (下图④)
- 第三个确定哪些 C 中的参数要用来做输入值 (下图②)
- 第四个参数一般就标记哪些寄存器需要保留
另外, 如果在上一节里对 eax/rax 的关系还不清楚, 那借助内联汇编其实可以更好的理解这个过程, 以及理解寄存器的使用, 定义a, b, c 这种常量, 会存在寄存器里么? (并不会, 整个过程看一下下图的代码对比就更加清晰了)
另一个会让人一头雾水的地方就是第二第三个参数里的约束字母/约束符, 我这为了理解方便特意换成了和变量一致的, 实际大家看到的时候可能比较奇怪而感到懵, 这里就说常见/常规的情况, 首先语法是 "x"(param), 这里 x 一般是约束符, 后面括号里的是 C 代码里的参数, 后者很好理解, 我需要哪些作为输入输出, 前面的是啥呢? 记一下常见 3 类即可:
- r: 动态分配可用寄存器 (不固定, 最常见)
- a/b/c/d: 对应
r/eax ~ r/edx寄存器 (给某个参数绑定一个确定的寄存器, f 表示浮点专用) - m: 表示变量自己的内存地址
那么用 r 和 a~d 有啥区别呢? 全自动分配和指定是不是一样呢, 其实还是有区别的, 虽然不影响最后结果, 看看汇编映射图:

两个关键区别, 一是 rbp 指针从 -20 变成了 -4, 另一个是用 r 代替后, 减少了不必要的 ebx 寄存器, 从而减少了几次不必要的 mov 操作, 这里就会想, 为啥之前我给 a 和 b 指定 eax 和 ebx 寄存器, 编译器还是会有个 edx 做中间变量呢?
另外在输出的时候有一个=r 这样的 = 出现, 它其实是一个输出专用修饰符, 常见 = 和 & :
- =: 修饰数只可写 (write only)
- +: 表示后面的数可读可写
- &: 表示在 asm 生命周期内, 都可以被删掉或重新使用的数 (结合例子理解)
- %: 修饰数可以和下一个数互换 (结合例子)
0x03. RISC-V 指令集
要知道完整的 X86 汇编是很多也很复杂的, 不同厂商可能都有各自的一套语法和标准, 对新手来说应该算是很不友好的, 所以 pa 课程核心使用的是大名鼎鼎的伯克利开源的精简指令集, RISC-V (读作: risk-five).
官方文档分为了两部分, 上册是非特权 ISA, 下册是特权 ISA, 如果打开手册看到目录感到不适应, 请深吸一口气, 要做的 x86/arm ISA 通常比这厚一个数量级(10X)以上. 而 RISC-V 是相对最友好的现代 ISA 了.

1. 简介
RISC-V 的主要目标包括: (节自官方手册)
- 提供一个真实的原生硬件 ISA 实现, 而不是模拟器或二进制翻译器.
- 避免成为 “过度设计” 或大包大揽的 ISA, 但尽可能保证灵活性
- 基础版可以用作教学, 扩展后可以用于工业级应用开发
- 32位/64位的版本都可用于 OS/APP/硬件上
- 支持并行多核处理器, 以及异构处理器
- 支持变长的指令设计 & 可选的密集指令(dense instruction)用来提速
- 可完整支持虚拟化, 用于虚拟机开发
- 采用一种简化的特权体系(privileged arch)设计
- 在非特权体系中, 在结构上尽可能避免对特定芯片产生依赖, 保证最大的灵活性
参考资料: