上一个说了图数据库的个性化 rank 算法, 这里再说一下更加常见的 Path 接口的 crosspoint API, 用来求两点的交点
0x00. 前言
首先 crosspoint 核心是求两点の相交点, 那么先得搞清楚它和共同邻居的差异, 给一个简单的图例:
graph LR a-->b-..->c-->d a1-->b c-->b
共同邻居:
- a/a1 和 c 的共同邻居是 b , d 和 b 的共同邻居是 c
- a 和 d 没有共同邻居 (超过了 2 跳)
Crosspoint:
- a 和 c 的交点同样是 b, d 和 b 的交点也是 c
- a 和 d 的交点是 c (区别)
那为何 a 和 d 的 crosspoint 是 c 而不是 b 或 [b, c] 呢, 就需要看看代码这里的逻辑了 (应该是有 bug, 期望应该会返回[b,c])
0x01. 问题定位
简单分析了一下, 问题大概分为两个部分, 一个是直接通过 bug 复现 case 来推测的, 没有提前终止环路, 比如图中就 a<–>b 两个点, 设置了很大的深度, 它一直在重复的遍历没有终止; 另一个就是, 就算是存在环路没有终止, 在点数很少的情况下也应该很快走完几千甚至几万跳才对, 所以大概率说明深度增大时, 遍历的性能也发现了显著的下降, 而环路只是让这个本质问题更加明显了而已.
1. 环路未提前终止
这个问题初步的解决办法就是遇到环路则提前结束遍历 (early stop), 但是由于当前的设计里没有办法检测图是否已经全部遍历完, 提前结束的做法虽然可以很快检测到环 , 但是会丢失更大深度的路径, 等于是只取了最短路径, 而没有返回全部路径, 也就等于修改 paths 的语义, 并不是很好的做法.
1 | public PathSet paths(Id sourceV, Directions sourceDir, |
上面的 findCycle 标记就是新增的, 这样可以使得发现环路则立刻跳出停止, 那么遍历的逻辑里, 主要是在添加 paths 时检测
1 | public boolean forward(Id targetV, Directions direction) { |
修改如上, 思路就是双向 BFS 遍历时判断是否和起点/终点重合.
2. 深度 & 耗时
从 Arthas 的 monitor 可以很直观的发现, 单个 path-api 查询触发的递归linkPath()执行次数多达 30w/s, 而一次查询可能要触发几千万 ~ 上亿次的执行, 那么时间按照换算, 自然也就是 30s ~ 300s 了, 如下图所示:
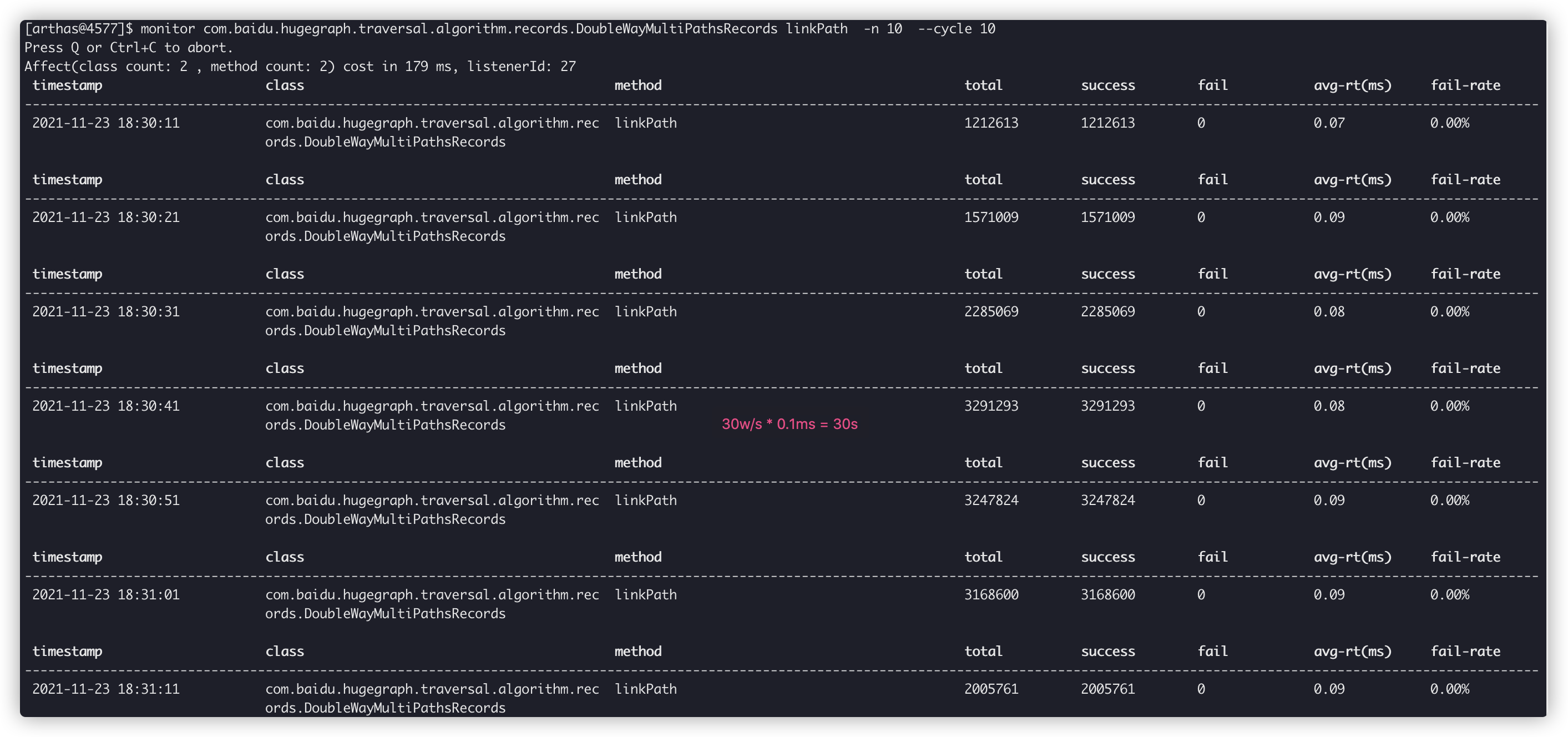
3.
0x02. 源码分析
首先要弄清楚现在的遍历思路, 那两个核心的数据结构需要了解, 一个是 DoubleWayMultiPathsRecords, 另一个是 Path
1. DoubleWayMultiPathsRecords
这是一个双向的
0x03. 问题分析
1 | // GET 请求即可复现问题 (10s 左右) |
输出当前的火焰图
graph LR %% a->d->c->e 会被丢弃 c-->e a-->b-->c-->d-->e a-->d %%a-->f-->d-->e
图数据库性能瓶颈分享