上一篇介绍完了 GraphScope 整体的结构和对应的一些文章, 随着官方 V0.8/0.9 版的发布, 更新了不少内容, 这里会分别 尝试单机和 K8s 上手实测, 有理解不当的地方随时可以交流反馈
施工 ing
0x00. 前言
这篇讲一下快速上手 graphscope 以及了解一下它具体启动后的结构和资源使用情况, 分单机和 k8s 两种模式, 侧重在后者 (集群模式)
官方把单机模式称为 stand-alone, 在有 python3 的环境就能直接使用, 一起看看, K8s 的使用方式官方封装了 helm 包管理, 可以一键的部署到 k8s 中, 也挺方便.
注: 此文随着测试不断会进行更新, 行文逻辑和上下文后续会重新梳理, 前期可能有些凌乱, 麻烦理解~
0x01. 准备工作
这里先说单机的部署使用, 后续集群部署中 K8s (包括 kind)的步骤也不会提及, 主要聚焦 GS 本身. 参考官方的文档至少这些环境需要准备好:
1. 单机部署
要求挺简单, 因为大部分都被官方自己安装打包了, 有一个高版本 py 就行了:
- Unix 的环境 (我这是 Cent7.x)
- Python3.7+ & pip 19+ (注意 py3.6 不兼容, 需替换)
1 | # 1. 默认装个3.8吧以免后续升级版本低了 |
可以看得出整个 gs 依赖的库版本都是比较新的, 也可以避开不少历史遗留包袱, 然后由于环境准备的确是相当简单一键化, 下一步就到了导入数据的地方了, 官方内置了一些图, 你也可以导入自己的数据
1 | import graphscope |
默认的 v6d 的日志似乎保存/tmp/vineyard.INFO. 不过这里单机版缺少不少文档和信息, 目前感觉过于黑盒, 也不清楚如何起内置的 Jupyter 前端交互访问, 仅通过 python-client 访问感觉有些迷茫, 就先搁置一下(等后续再看看), 先着重看看集群模式
2. 集群部署
官方这里目前仅介绍了 K8s 方式, 那就直接参考即可, 下面我们假定已经有了一套稳定可用的 K8s 环境, 我这使用的是 V1.15, 因为后续要使用 helm, 也请自行参考相关文档确认对应版本 (对号入座), 在有了 helm + k8s 环境后, 基本准备工作就做完了, 下面主要说一下 helm 相关的配置使用, 想看看 graphscope 的 chart 具体说明可见此
1 | # 根据文档安装对应版本的 helm, 就一个二进制文件 |
我们可以从 values.yaml 中看到默认的配置和一些用户可调设置:
1 | # Default values for graphscope. Declare variables to be passed into your templates. |
然后上面这些变量在 ./template 文件夹的 yaml 文件中会当参数被直接使用, 目录下有几个相关的 k8s 配置文件, 分别是 coordinator.yaml, service.yaml, role_and_binding.yaml, 由于篇幅所限大家可自行查看完整版, 我这就不单独列了. 如果想自行修改相关配置, 修改后可参考文档配置
然后安装完成后, 可以在 k8s 的 dashboard 界面的 default namespace 里找到 gs 的相关服务:
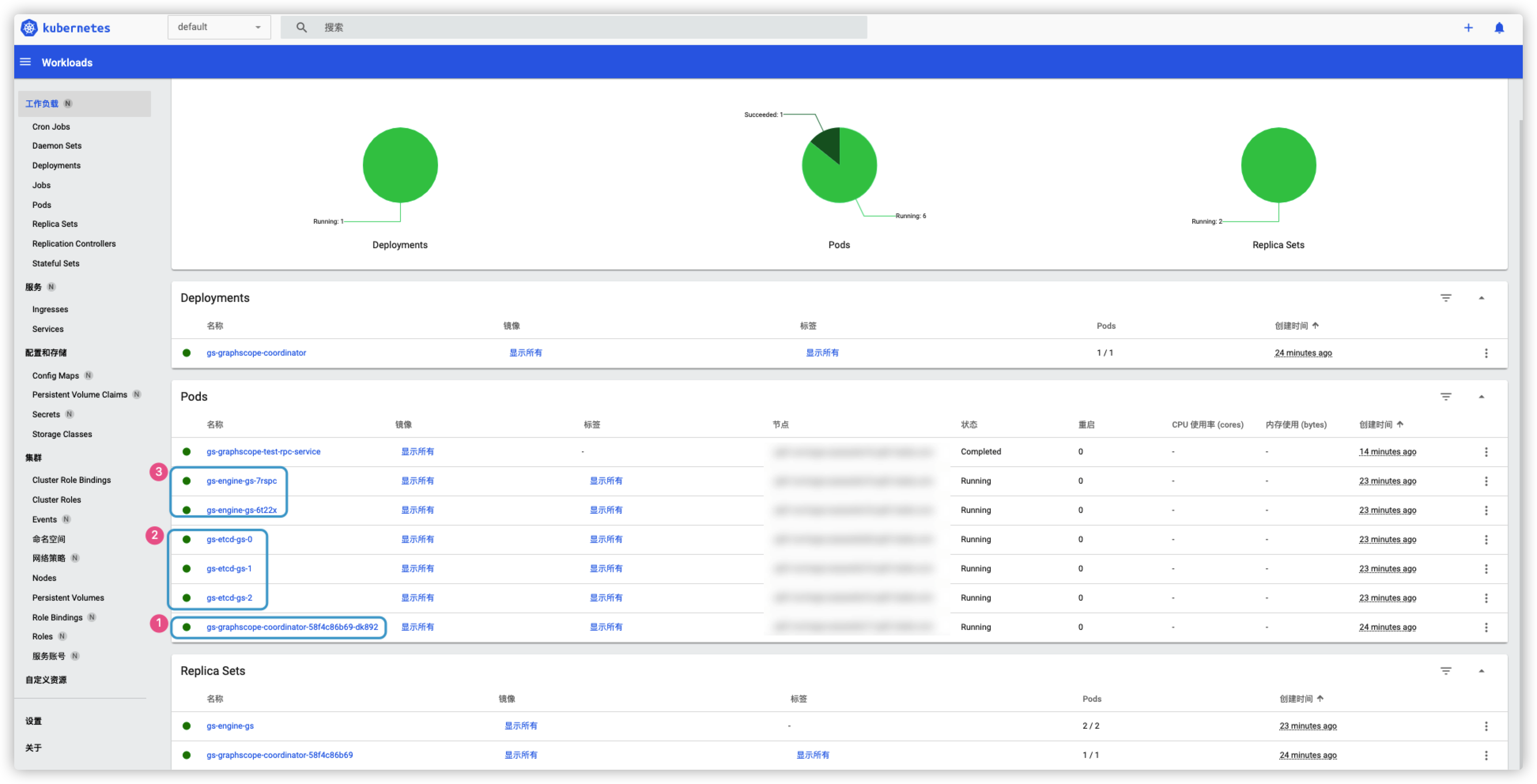
如果长时间卡在 cooperator 初始化容器, 可能是 k8s 集群资源不足或者其他情况, 别着急重启 Deployment 或删除, 删除最好使用 helm uninstall/del 来统一执行, 这里大家初次使用 helm 容易有 2 个困惑的地方:
- 如果集群已经启动, 修改了
values.yaml后如何更新 (可直接 kubectl 修改配置文件, 可查阅 helm 文档) - 如果集群没启动, 直接用修改后的
values.yaml启动后找不到名字 (ReleaseName), 不知道如何管控集群 (见下)
1 | # 0. 你可以先 pull 拉取包, 然后解压修改 values 配置, 这里的 releaseName 就是随机生成的一个编号 |
然后有几个问题需要确认一下:
- 修改挂载路径的例子是不是针对 kind 这种单节点虚拟集群来说的, 因为它也就一台机器, 所有 k8s node 也能共享访问, 而真实的 k8s 集群里, 如果只是单纯修改 gs-client 所在机器(假设是 k8s master 节点), 那其他 node 应该是不能访问的吧.
- 真实 k8s 集群中, 是否需要用户手动使用 pvc (然后底下是 nfs) , 或者 s3 等其他方式来做 (如果是, 可以补充一下相关文档)
- py脚本中直接修改路径后, 如果配置有问题会长时间卡住, 缺少输出信息和具体报错提示.
- python 封装的内置数据集的自动下载和导入是如何直接灌到 v6d 中(不依赖 pvc/NFS 等方式的), 普通用户如何这样导数据
- 大量的数据有 BulkLoad 的方式或单独接口么 (还是目前只有 Loader 这个单点在线导入组件)
PS: 如何系统的查看日志/监控等属于 K8s 集群通用内容, 这里也就不单独说了(需要也可以通过 helm 安装配置 ELK)
0x02. 具体运行
A. 数据导入
1. 公开数据集
这里要导入实际的测试数据, 结合 Jupyter 来交互式的运行查询
1 | # 在本地的 /graph/data 下存储 ogbn 测试数据 (总 130w 点边) |
然后官方也提供了其他常见的测试数据模型 (如 LDBC), 并封装好了 python 的自动安装脚本, 可以参考例子中 ogbn 的导入方式使用 py 一键导入, 也可以参考自行进行修改调整, 详细的 Python-API 可能会参考
1 | import graphscope |
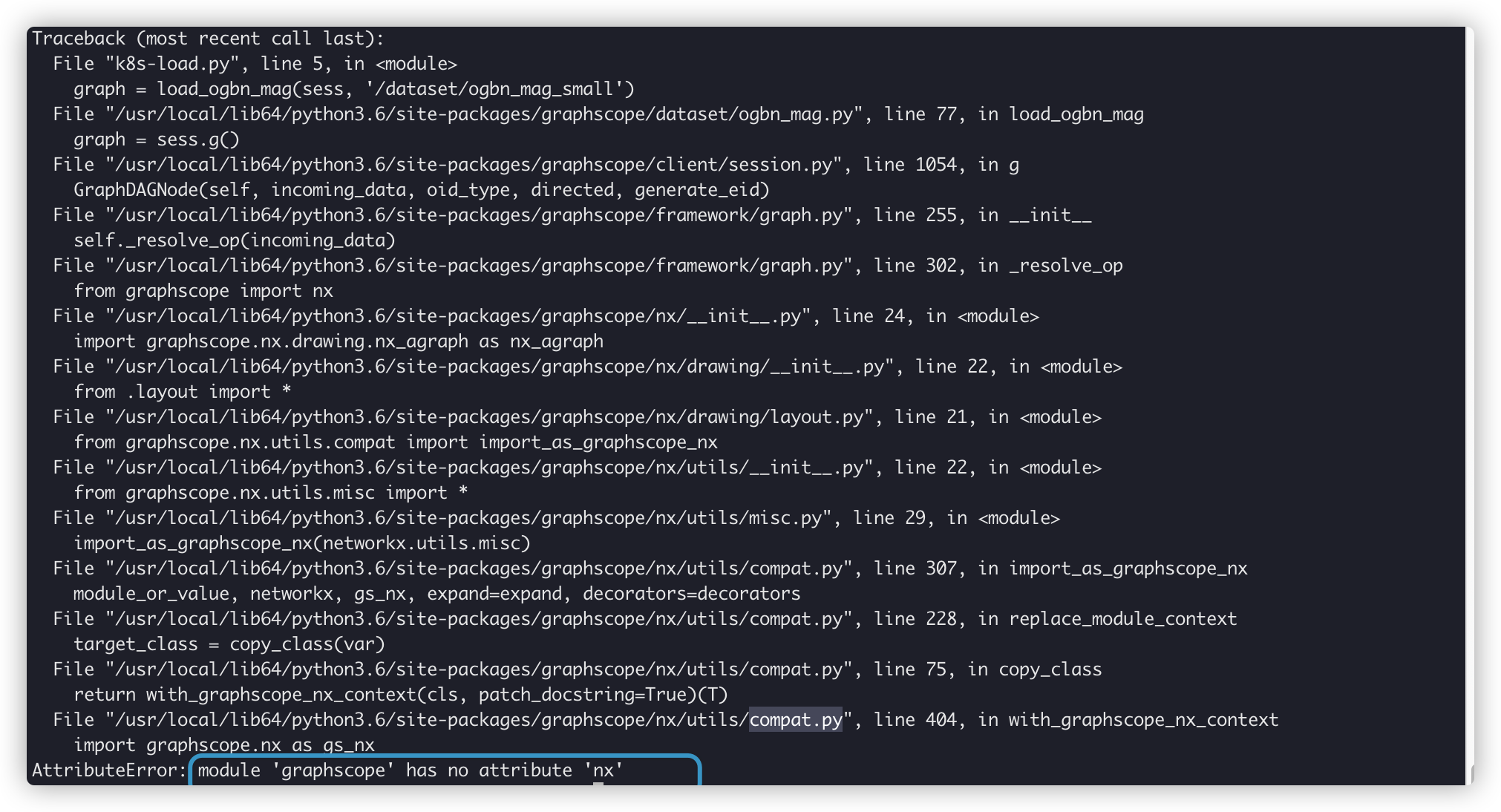
不幸这里直接报错卡住了, 提示找不到 graphscope.nx, 官方回复是 py 版本 <3.7 导致的, 已经在文档的准备工作那增加了 py3.8 的安装和准备. 这部分之后移到单独的问题 list 里 (outdated), 重新安装了 py3.8 和对应的环境之后, 执行内置的数据导入脚本, 又卡了几分钟, 然后报了新的错, 内容较长就贴在一个 gist 里了.
重新调整了一下 pod 资源配置和 py 的导入脚本之后, 得到了新的报错, 执行返回的确快了许多(之前会卡许久)
1 | graphscope.framework.errors.AnalyticalEngineInternalError: '"ArrowError occurred on worker 0: ArrowError occurred on worker 0: |
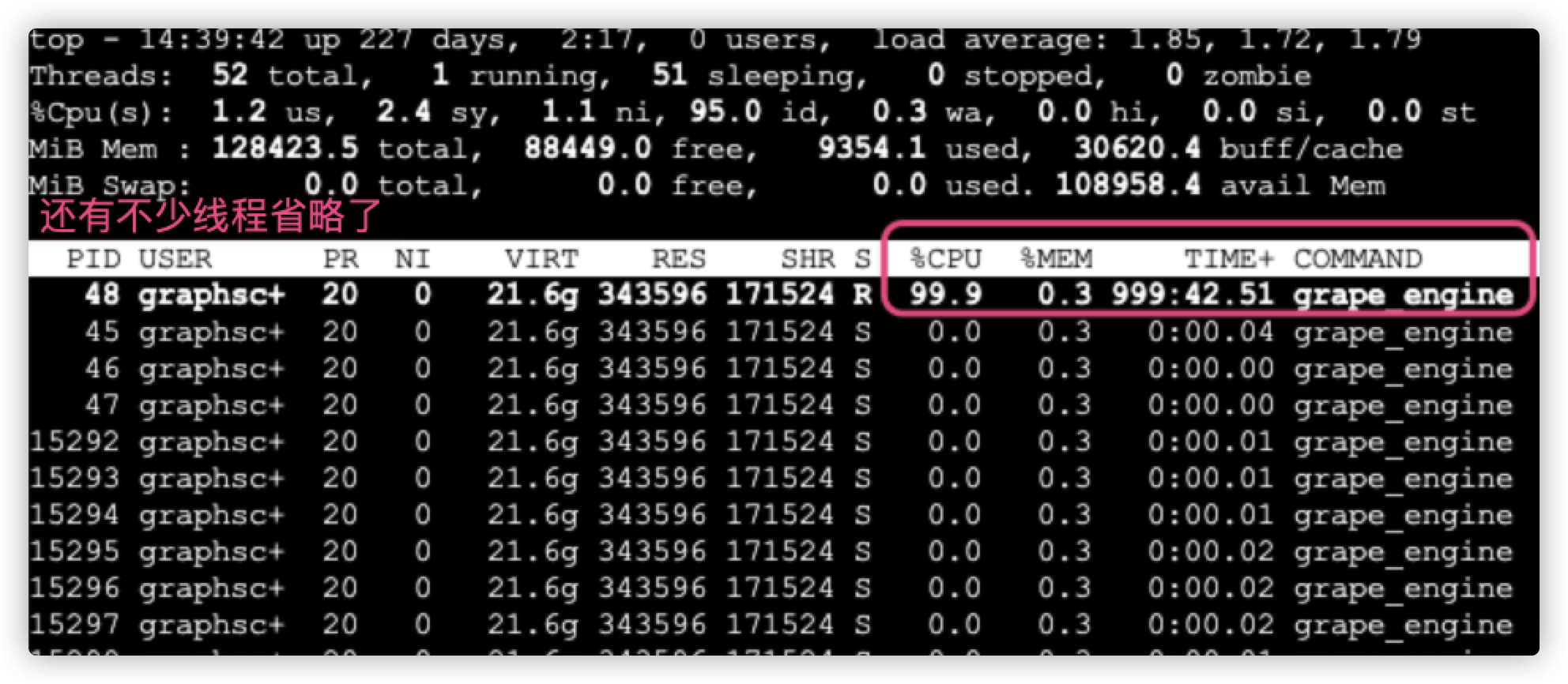
导入出现了卡住问题, 当然这里也不确定是卡了还是在忙, 但是不解的是为何只有一个线程干活.
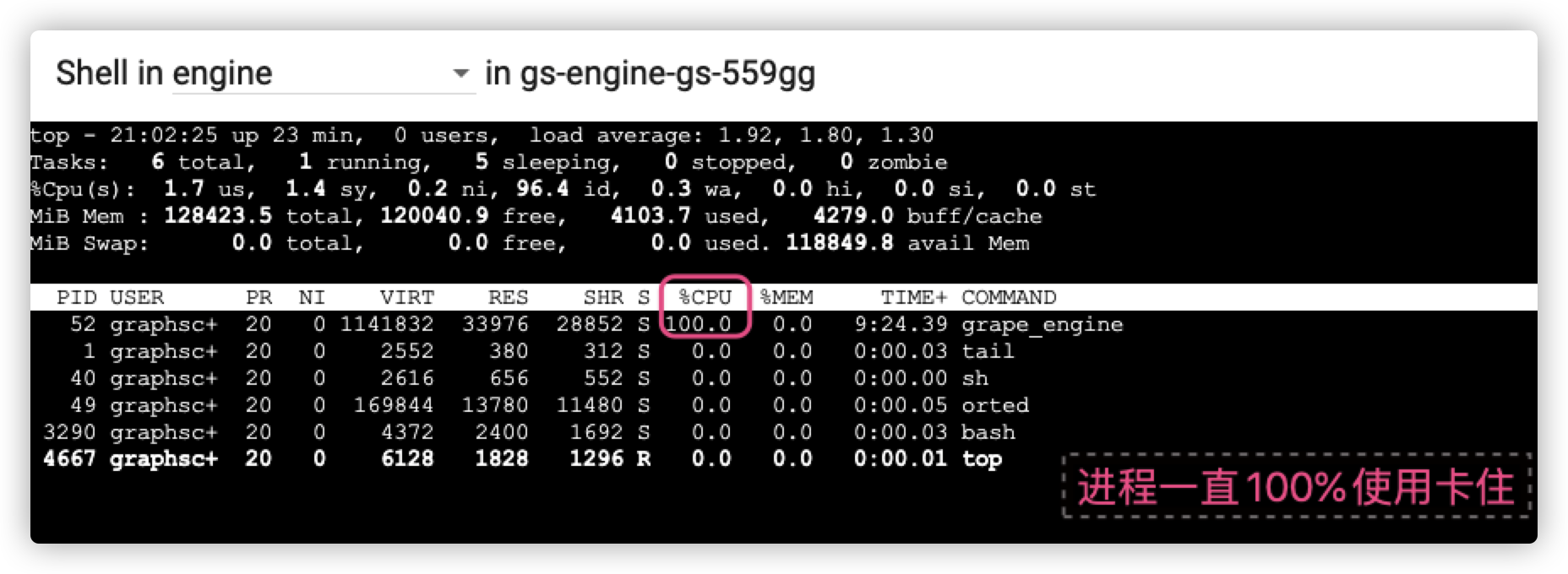
此时 pod 内加载的进程:
最后看了下代码和报错, 我尝试自己手动在容器里下载一下数据然后解压试试:
1 | # 分别进入 engine container 的 bash, 手动创建文件夹, 然后下载解压原始数据 |
然后你可以在 coordinator 的日志里看到类似的导入信息 (这里我尝试导了两次)
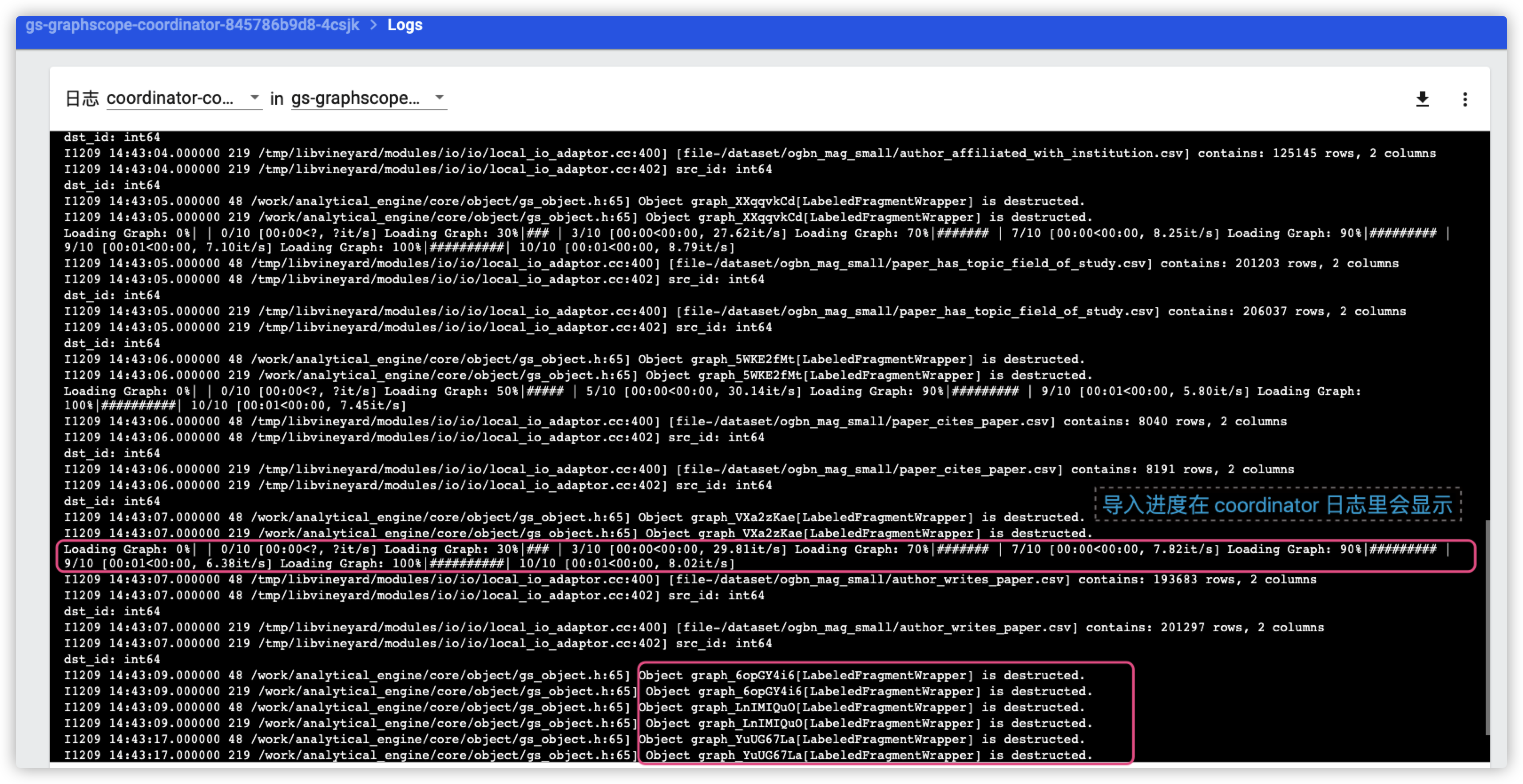
2. 私有数据集
显然很多时候具体测试会使用自定义的数据集, 就需要来自行定义图的点/边 schema 结构以及数据映射/解析, 这里官方给出的方式仍然是通过 Python-API 来实现
1 | import graphscope |
然后 gs 还提供了一些进阶的 schema 设定, 这里选取用户可能比较关注的一些特性:
- 如果边的 sourceV 和 targetV 不存在, 自动根据边数据生成对应点 (以及vLabel?)
- 支持同一名称的边 label 被多次使用 (重点)
- 自动推断点/边文件的属性类型 (也可自指定)
- 支持全图设置有向/无向图
下面再说一下 gs 内置的 loader 组件, 它应该也是上述简单例子的实现, 完整支持 file/hdfs/s3/oss 多种常见的文件存储, 然后数据导入官方说是由 v6d 负责, 用了fsspec 来做各种格式/参数解析, 应该兼容和扩展性还是比较全的:
1 | from graphscope.framework.loader import Loader |
B. TP 查询
上面的数据导入成功后, 就正式开始了 graphscope 体验旅程了, 这里就先按官方数据集, 来看看 TP 查询如何进行:
1 | import graphscope |
11
1 | [cluster:377]: Create GIE instance with command: /home/graphscope/.local/lib/python3.8/site-packages/graphscope.runtime/bin/giectl create_gremlin_instance_on_k8s /tmp/gs/gs/session_izynzsgw 4422182077725296 /tmp/graph_w1UFK8u2.json gs-engine-gs-d4wqq,gs-engine-gs-ks94z engine gs-graphscope-coordinator |
C. AP 查询
0x03. 整体结构
由于单机版本封装的太完整, 所以几乎完全不知道里面在做啥, 还是先从 K8s 集群版本来看看把. 先看看官方文档的:
Kubernetes 上的一个 GraphScope 实例包含:
- 一个运行 etcd 的 pod,负责元信息的同步 (应改为一组/3个 pod ?)
- 一个运行 Coordinator 的 pod,负责对 GraphScope 引擎容器的管理 (以及可选的 jupyter 前端)
- 以及一组运行 GraphScope 引擎容器的 ReplicaSet 对象 (每个 pod 由 engine + v6d 两个 container 组成)
Coordinator 作为 GraphScope 后端服务的入口,通过 grpc 接收来自 Python 客户端的连接和命令,并管理着图分析引擎(GAE –> Grape?)、 图查询引擎(GIE –> Gaia?),图学习引擎(GLE –> graphLean?)的生命周期
简单来看, 似乎 coordinator 类似一个 gs 的 常驻 master 节点, 负责初始化其他组件和调度分发任务, 可能也能管理运行时环境, 然后核心的 engine 里分两个 container, 一个是计算容器, 负责分析/计算/AI等, 按需启动, 貌似 grape 进程卡住时会常驻; 然后 v6d 对应的是存储功能, 应该是常驻进程, 这里以 pod 为单位, 大概推测了一下整体的结构 (仅推测)
graph LR %%subgraph k8s cluster a(coordinator - Master) --RPC--> b(etcd - PD) a ==RPC==> e %%-.RPC?.-> d(storage - v6d) subgraph gs-engine-pod subgraph v6d-container d(vineyard) end subgraph engine-container e -.IPC.-> d d -.IPC.-> e e(GSE - OLAP) f(GIE - OLTP) g(GLE - AI) end end b-.RPC.->e %%end
其中 IPC 代表进程间通信, 我原本以为数据是存在 v6d 的容器内, 然后通过 IPC 共享给 engine 的进程, 但是经过官方提醒发现并不是, 官方说是 v6d 里只存储了少量元信息, 数据是保存在 engine 的内存里 (所以生产配置应该把 engine 给大点内存才对?), 为何可以这样做呢? 有点懵, 看来之后得看看 v6d 这里的实现方式 (还能把数据放在其他容器内么.. 这样的话直接把 v6d 也放在 engine 的 container 里似乎也行?)
其他组件通信主要应该是 RPC, 然后省略了一些 etcd 可能有的箭头指向, 完整的等具体官方结构图为准吧. (Jupyter 容器也在 coordinator 的 pod 里, 因为可选就不单独画了)
0x04. 已知问题
这里汇总一下测试和上手中发现的小问题, 大多是文档或者提示类的, 先记录一下, 有些不一定可以稳定复现.
- dataset 页面的示例里
from graphscope.dataset import load_cora最后应该改为load_cora_graph, 函数调用同 - 修改 values 文件后, 直接通过
helm install -f values.yaml graphscope/graphscope --generate-name, 出现helm del xx成功后, 发现只有 coordinator pod 删除了, 其他服务和 pod 都没有删除/关闭的问题, 不知为何 (目前手动删了), 似乎能稳定复现 (但是直接 install 模板的是可以全删的) - Helm 安装启动 Jupyter 后具体如何使用, 这里可以链接个文档和官方的 playground 关联一下 (或者考虑把模板内嵌到容器内, 启动后就内置, 现在是一片空白, 不熟悉 jupyter 的同学需要有个文档参考)
- 导入数据时 grape-engine 会长时间卡住, 然后 py 那边也不报错卡着.. 目前自己重启了 pod, 但是发现好像自己重启或删除 pod, 虽然 k8s 会立刻重建一个新的, 但是 coordinator 却无法感知导致出现问题.. (这是预期的么)
- 那 4 发生的时候, 只能直接
helm del gs然后重新安装了么…还有什么办法来让部分 pod 重启或者增减呢 - 使用官方内置数据集导入可能会出现没有自动创建文件夹和下载的情况, 原因未知 (目前我的做法是自己进入 pod 手动模拟操, 官方已经在讨论区解释了
12月10新增:
针对官方之前提的: 目前 Helm 部署方式依赖提前创建的 role 和 rolebinding 来删除创建的资源,这个创建了嘛?
A: 我尝试先
kubectl create -f role_and_binding_diy.yaml单独创建 role, 然后再使用helm install gs -f values.yaml graphscope/graphscope创建 helm 的集群, 发现没有作用. helm 还是会自己创建另一个名字的 role, 先把 role/binding 写为同名的, 则 helm 创建时就会马上报错… 感觉好像有点奇怪 (如下图).
测试时挂载数据最简单的方式是在 K8s Node的节点上 scp 批量分发一下数据, 然后直接通过本地方式挂载..
0x05. 疑问点
给 engine pod 假设 10 核的最大资源, 导入数据后, grape_engine 一直只能使用 100% 近乎是单核心, 为啥? 其他线程没有干活看起来. (不太理解), 另外导入完后 grape 进程一直 100%. 持续时间也很长 (符合预期么?)
如何复用导入的数据和 session? 理解应该是导入了一次数据之后, 后续的 ap 和 tp 查询应该都能复用这份内存中的数据, 而不需要重新导入了?
0x0n. 小结
最明显的感觉是不管是单机还是集群模式, 大部分的交互和原理都挺黑盒, 用户只能一键使用和调API, 如果步骤中出现任何报错, 都容易迷茫或手足无措~
更新: 这里建议默认打开把 coordinator 的日志输出的选项, 这样至少命令行不会是一片空白卡着了.
未完待续
0x0n.更新补充
这次回看我把这篇的目标定成“可复制”:从命令流水升级为标准 runbook。
- 版本锁定:K8s、Helm、GraphScope、镜像仓库与数据集版本。
- 一键执行:安装、导入、校验分成独立脚本,减少人工误操作。
- 验收口径:服务就绪、样例数据导入、查询结果一致性三类检查。
- 排障分流:环境、依赖、配置、数据四类问题对应日志入口与处理动作。
后续我会把“常见报错 -> 定位命令 -> 修复动作”整理成表格附录,这样这篇可以直接拿来当团队排障手册。
flowchart LR
A["环境与版本检查"] --> B["部署 GraphScope"]
B --> C["导入样例数据"]
C --> D["执行查询/算法"]
D --> E["结果校验"]
E --> F["失败分流排障"]
待核验:基于当前版本重跑全流程并补齐关键日志、命令差异与修正点。
参考资料: