HDFS读流程 之后, 继续阅读源码的写入流程, 大部分情况, 写入要比读取要复杂许多的(因为有错误恢复和追加写), 所以需要细心记录梳理
同样, 写入部分的源码也分Client, Namenode和Datanode三个部分来看, 先看看整体和Client的部分.
PS: 最后会做个串联全部写的 Slide(TBC), 经过”总-分-总”的流程之后, 才能真正的把HDFS的写流程弄清楚
0x00. 整体流程 阅读写源码前, 也需要先清楚读开始 提到的几个基本概念, 会经常用到, 这里不再复述, 之后讲技术内容, 尽量都会先提供一个自己参考/重画的概览图 (总结), 先有个总体的了解, 再说具体 (代码)细节.
同样先给一个我重画之后的写整体 流程图,如下所示: (附原高清图地址 , 有问题欢迎随时联系更新)
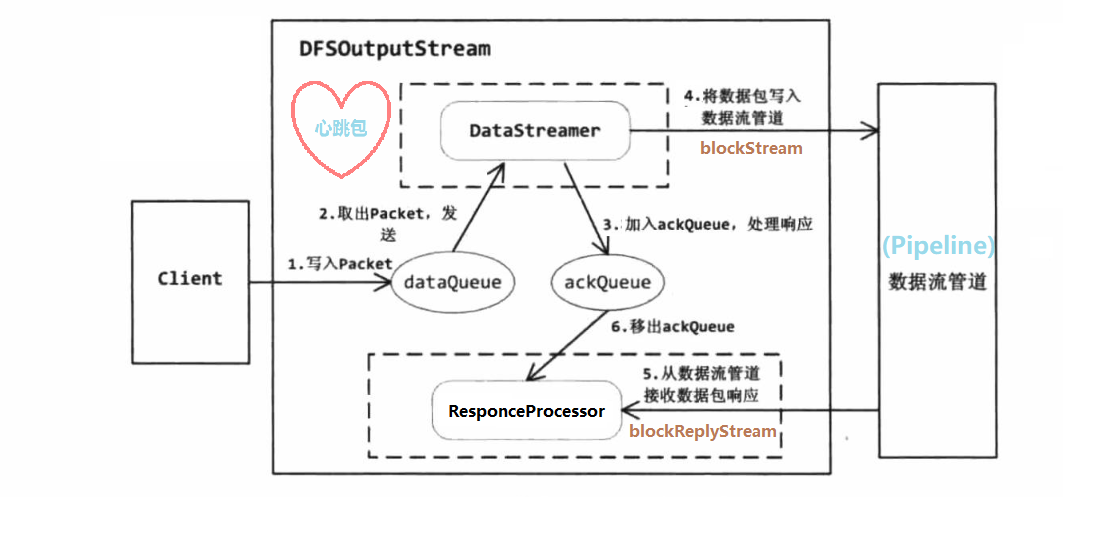
其中客户端 核心在create() 和write() 两个API调用中, 大体步骤如下:
新写一个文件, 先调用create() 方法底层去给NN发一个RPC请求, NN收到请求后会在FS的目录树对应路径添加一个空的 新文件, 然后记在editLog, 创建完成后返回FSDataOutputStream , 它调用DFSOutputStream 写数据
有了输出流对象之后, 核心就是调用write()方法, 在①中只是单纯创建空文件, 这里再开始申请新的数据块 , 以及传输管道, 成功后会返回这个块的所有DN节点信息.
通过传输管道把要写入的数据切分为一个个packet(约64K)大小发送, 然后在多个DN节点之间依次顺序传输, 然后逆序返回ACK 确认写成功, 最后客户端接收到正常ACK, 表示当前packet发送成功
如果DN接收完文件所有packet, 则会向NN汇报当前block信息
如果写满了一个block, client会接着再申请一个新的block, 直到所有数据传输完成
最后关闭流的时候, 送complete()-rpc 给NN提交文件的所有block, 确认DN已都完成块汇报后, NN确认当前文件写完成.
sequenceDiagram
participant C as Client
participant NN as NameNode
participant D1 as DN1
participant D2 as DN2
participant D3 as DN3
C->>NN: create(path)
NN-->>C: FSDataOutputStream
loop each block
C->>NN: addBlock
NN-->>C: pipeline(D1,D2,D3)
loop each packet
C->>D1: packet
D1->>D2: forward
D2->>D3: forward
D3-->>D2: ack
D2-->>D1: ack
D1-->>C: ack
end
end
C->>NN: complete
NN-->>C: success
0x01. 代码例子 接着来看常见的写数据的Client-API使用代码:
1 2 3 4 5 6 7 8 9 10 11 12 FileSystem fs = FileSystem.get(new URI ("hdfs://ip:port" ), new Configuration ());FSDataOutputStream outputStream = fs.create(new Path ("/test/writeFile" ));outputStream.write(new byte [4609 ]); outputStream.writeBytes("Test write data" ); outputStream.close();
可以看到, 类似读取流程, 从Client-API 层面来看是很简单的, 细节和对应发送的RPC都隐藏在封装下面. 接着看看
0x02. 写入准备 A. 整体流程 沿着刚才的大流程, 我们分几个部分一个个来说, 先来看看第一步的fs.create(path)的整体流程. 核心就是发RPC获得新文件初始化两个对象, 比较简单:
B. 代码细节
备注: 为方便阅读, 所有方法抛出的IO异常 都被默认略去, 所有日志打印/Trace 都被省略, 低关联调用 简化, 参数值均为HDFS3默认官方参数
FileSystem是我们程序的入口, 它有许多create() 方法的重载, 只传入一个Path 对象, 实际已经带了一系列的默认参数 , 实际调用如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 public abstract FSDataOutputStream create (Path f, FsPermission permission, // 文件权限 boolean overwrite, // 默认true (覆盖写) int bufferSize, short replication, long blockSize, Progressable progress); @Override public FSDataOutputStream create (final Path f, params...) { Path absF = fixRelativePart(f); return new FileSystemLinkResolver <FSDataOutputStream>() { @Override public FSDataOutputStream doCall (final Path p) { final DFSOutputStream dfsos = dfs.create(params...); return dfs.createWrappedOutputStream(dfsos, statistics); } @Override public FSDataOutputStream next (final FileSystem fs, final Path p) { return fs.create(params...); }}.resolve(this , absF); } public DFSOutputStream create (params..., // 之前介绍过的参数 InetSocketAddress[] favoredNodes, // NN首选节点列表,默认空 String ecPolicyName) { final FsPermission masked = applyUMask(permission); final DFSOutputStream result = DFSOutputStream.newStreamForCreate(this , allParams...); beginFileLease(result.getFileId(), result); return result; } static DFSOutputStream newStreamForCreate (DFSClient dfsClient, params...) { try { HdfsFileStatus stat = null ; boolean shouldRetry = true ; int retryCount = CREATE_RETRY_COUNT; while (shouldRetry) { shouldRetry = false ; try { stat = dfsClient.namenode.create(params..); break ; } catch (RemoteException re) { IOException e = re.unwrapRemoteException(exceptions...); if (e instanceof RetryStartFileException) { if (retryCount > 0 ) { shouldRetry = true ; retryCount--; } else { throwExcp("Too many retries because of encryption zone operations" , e); }} else throw e; }}} final DFSOutputStream out; if (stat.getErasureCodingPolicy() != null ) { out = new DFSStripedOutputStream (params...); } else { out = new DFSOutputStream (params...); } out.getStreamer().start(); return out; } } protected void computePacketChunkSize (int psize, int csize) { final int bodySize = psize - (PKT_LENGTHS_LEN + MAX_PROTO_SIZE); final int chunkSize = csize + getChecksumSize(); chunksPerPacket = Math.max(bodySize / chunkSize, 1 ); packetSize = chunkSize * chunksPerPacket; }
这是HDFS3.1.2的Packet完整结构的图 (基于低版图 修改, 低版个数 和数值 略有差别) :
附一下Packet的几个核心成员 的默认 值和含义:
名称
数值 (默认)
含义
psize
65536B (64K)
packetSizeMax的意思. 理论上可达65536B (64K)
csize
512B
每个chunk数据域的大小
checkSumSize
4B
每个chunk校验域的大小
chunkSize
516B
一个完整的chunk的大小 ( 数据域+ 校验域)
PKT_LENGTHS_LEN
6B
PacketLength和HeaderLength之和 –> 4 + 2
MAX_PROTO_SIZE
27B
packet头中走protobuf序列化的最大 占用(详见后文)
bodySize
65503B
一个packet的数据域部分最大值 (也称packet data)
chunksPerPacket
126
每个packet可以承载多少个校验块(低版127个)
packetSize
65016
这是当前实际传输 时每个packet的大小, 约63.5K
源码参考: HdfsClientConfigKeys (rel/release-3.1.2) 、hdfs-default.xml (rel/release-3.1.2) 、DFSOutputStream.computePacketChunkSize 。
经过上面的层层追溯, 从顶层FileSystem.create 到最后发送RPC请求, 以及初始化DataStreamer 这个后续传输数据的关键对象的脉络就很清楚了, 包括也能看出新版本HDFS在写文件的时候, 会根据是否开启EC, 进行不同的初始化操作.
上面是写入的准备工作 , 获得了一个空的文件, 初始化了两个关键对象, 接下来看看写入的核心write() 方法.
0x03. 写入数据 写入过程比较复杂, 简单可以抽象成 “发送packet –> 响应packet” , 然后拆分为几个大步骤, 拆分为几个模块去讲, 整体结构如图: (基于书中原图修改 , 修正了一些错误)
1. 创建Packet Packet是Client和DN间数据传输的最小单位, 它可以按是否携带数据域 分为两类:
普通数据包
特别功能包 (包括心跳包和空尾包)
先来看看普通数据包, 的数据结构 和序列化 部分有些变化, 所以基于之前的图重新画了一个新版本, 不然是对不上的
这里补充一下Packet头里经过PB序列化的字段含义: (每个字段的真实长度在PB中是类型长度**+1**)
名称
类型
长度
含义
offsetInBlock
long
8
packet 在 block 中的偏移量
seqNo
long
8
packet的编号,在同一个block中唯一
lastPacketInBlock
bool
1
是否为一个block 的最后一个packet
dataLen
int
4
记录chunk data的实际总长度 (dataPosition-dataStart)
syncBlock
bool
1
强制刷盘(写穿), 调用POSIX的O_SYNC标志
数据从IO流到Packet的过程需要清楚, 假设我们要写1025个字节的一个文件, 它至少需要占据3个chunk, 那么过程如下:
首先packet头变长 占据最多33字节, 那么实际写数据(checksum+data)是从33B 的偏移开始, 比如写了一个4B的checkSum1
然后紧接着写chunk data1, 它从(33 + 126 * 4) = 537的偏移开始写, 写满512B
同样的方式写入第二个chunk, 现在还剩下1字节没有写入, 它占据第三个chunk, 把packet头中的lastPacketInBlock设置为true, 再写了1B的偏移量之后, 剩下511B的空余会补0么? (待确定)
(补充 ) 虽然数据写完了, 但此时显然packet没有写满, 那从checkSum3到chunkData1之间还有一段未被使用 过的缓冲区, 那么在发送Packet之前做的空缺检查 (gap)会把chunkData整体前移,让checkSum3和chunkData1最终相邻(详见后文)
再来看看心跳包, 这里高低版本结构有所不同:
低版本 1/2里是使用Packet 类的无参构造方法表示心跳包, HDFS3中改为Packet类专供DN的BlockReceiver使用, 而客户端写数据专用DFSPacket 类, 它没有packet body, 只有packet header, 并通过seqNo (-1)来标识自己为一个心跳包, 比较简单. (文中如无特殊说明, packet都是 指的DFSPacket)
上面看完了前置所需的知识, 了解了packet的构造, 下面结合代码来看看实际的调用过程 :
之前我们通过create() 方法创建了一个新的空文件, 以及DFSOutputStream 这个输出流对象, 紧接着就是用它输出流去调用write() 方法了(继承自FSOutputSummer), 它将一定大小的数据(比如1025B)写入输出流一个缓冲区 中, 然后按上面的packet格式切分为多个数据包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 @Override public synchronized void write (byte b[], int off, int len) { for (int n=0 ;n<len;n+=write1(b, off+n, len-n)) {} } private int write1 (byte b[], int off, int len) { if (count==0 && len>=buf.length) { final int length = buf.length; writeChecksumChunks(b, off, length); return length; } int bytesToCopy = buf.length-count; bytesToCopy = (len<bytesToCopy) ? len : bytesToCopy; System.arraycopy(b, off, buf, count, bytesToCopy); count += bytesToCopy; if (count == buf.length) { flushBuffer(); } return bytesToCopy; } @Override protected synchronized void writeChunk (byte [] b, int offset, int len, byte [] checksum, int ckoff, int cklen) { writeChunkPrepare(len, ckoff, cklen); currentPacket.writeChecksum(checksum, ckoff, cklen); currentPacket.writeData(b, offset, len); currentPacket.incNumChunks(); getStreamer().incBytesCurBlock(len); if (currentPacket.getNumChunks() == currentPacket.getMaxChunks() || getStreamer().getBytesCurBlock() == blockSize) { enqueueCurrentPacket(); adjustChunkBoundary(); endBlock(); } }
到这里, 正常写流程的第一大步就差不多完成了, 接下来看更核心的发送过程, 发送过程重点讲DataStreamer的run()方法
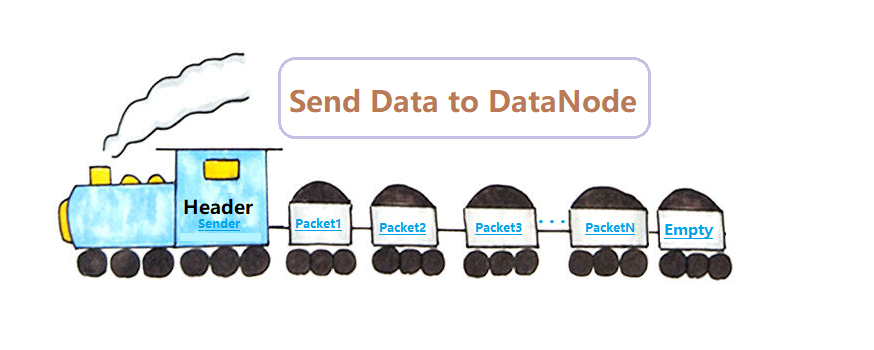
2. 发送Packet A. 整体结构 因为小于63.5K 的数据不足发车要求, 这里假设写入128K 的文件, 它应该占据三个 packet, 但是只有前两个 packet会入队发车, 最后一个在末班车才发.
flowchart LR
A[writeChunk 构造 DFSPacket] --> B[dataQueue 入队]
B --> C[DataStreamer 发送]
C --> D[ackQueue 等待ACK]
D --> E{ACK 正常?}
E -- 是 --> F[从 ackQueue 移除]
E -- 否 --> G[触发错误恢复/重建 pipeline]
满足1个packet大小的数据会被封装好, 然后Client依次发给DN, 这里Packet只是数据包的载体, 就像HTTP请求发数据, 除了数据载体本身也需要有一个请求头 , 所以在发送Packet之前, 需要一个Sender 发送写请求, 得到了所有DN的确认后, 才会开始发数据
这里把每个Packet看做是一节载货车厢, 最后一节是空车厢 (空尾包), 它们整体结构就像一辆载货的火车 , 画了个简图方便大家理解:
注: “火车头 “Sender并非是跟着货物(Packets)一起发送, 而是先单独发送 , 车厢 (packet)再进入铁轨 (pipeline), 开始一个个传输(火车头的结构在DN篇 说)
B. 发包线程DataStreamer (核心) 核心的代码在DataStreamer这个后台线程类的run()方法中, 线程启动是在create() 调用最后, 也就是说还没开始write()的时候, 它就已经在后台运行了, 核心做两件事 :
这里我们主要先看第一个功能, 打开传输通道, 让火车能在铁轨 上跑起来, 为了方便阅读, 简化大量无关代码 (包括错误机制):
线程启动后就一直循环检测是否有需要发送的packet, 没有则等待一段时间
当有packet需要发送了, 取出来 (或者等待时间超时, 构造心跳packet)
给NN发请求要block的信息, 并初始化pipeline, 使之变为就绪态 (可以传数据了)
正式发送则把packet对象从dataQueue出队, 然后进入ackQueue (每个block的最后一个packet会单独延时等待)
再把packet实际写入pipeline中, 并刷新 (进入DN的操作)
更新发送信息, 然后跳至1发送下一个packet (如果是最后的packet, 则准备收尾操作)
stream完全关闭或客户端中断, 则进入最后的大收尾操作
如图 所示:
C. 源码分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 @Override public void run () { long lastPacket = Time.monotonicNow(); while (!streamerClosed && dfsClient.clientRunning) { DFSPacket one; try { synchronized (dataQueue) { long now = Time.monotonicNow(); while ((dataQueue.isEmpty() && (stage != DATA_STREAMING || now - lastPacket < 30 ))) { long timeout = 30 - (now-lastPacket); timeout = timeout <= 0 ? 1000 : timeout; timeout = (stage == DATA_STREAMING)? timeout : 1000 ; dataQueue.wait(timeout); now = Time.monotonicNow(); } if (dataQueue.isEmpty()) { one = createHeartbeatPacket(); } else { backOffIfNecessary(); one = dataQueue.getFirst(); } } if (stage == PIPELINE_SETUP_CREATE) { setPipeline(nextBlockOutputStream()); initDataStreaming(); } else if (stage == PIPELINE_SETUP_APPEND) { setupPipelineForAppendOrRecovery(); initDataStreaming(); } long lastByteOffsetInBlock = one.getLastByteOffsetBlock(); if (one.isLastPacketInBlock()) { synchronized (dataQueue) { while (ackQueue.size() != 0 ) dataQueue.wait(1000 ); } if (shouldStop()) continue ; stage = PIPELINE_CLOSE; } synchronized (dataQueue) { if (!one.isHeartbeatPacket()) { dataQueue.removeFirst(); ackQueue.addLast(one); dataQueue.notifyAll(); } } try { one.writeTo(blockStream); blockStream.flush(); } catch (IOException e) { errorState.markFirstNodeIfNotMarked(); throw e; } lastPacket = Time.monotonicNow(); long tmpBytesSent = one.getLastByteOffsetBlock(); if (bytesSent < tmpBytesSent) bytesSent = tmpBytesSent; if (one.isLastPacketInBlock()) { synchronized (dataQueue) { while (ackQueue.size() != 0 ) dataQueue.wait(1000 ); } endBlock(); } } catch (Throwable e) {...}} closeInternal(); }
上面7个步骤中中关键点在于第三步的初始化pipeline , 和第五步的写数据, 而初始化pipeline就像给载物火车旅程进行初始化, 我们得知道火车运输的货物信息(BlockInfo), 要开往的目的地信息(DataNodeList), 以及准备好运输的铁轨 (pipeline), 下面看看初始化的详细过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 protected LocatedBlock nextBlockOutputStream () { LocatedBlock lb; DatanodeInfo[] nodes; StorageType[] nextStorageTypes; String[] nextStorageIDs; int count = 3 ; boolean success; final ExtendedBlock oldBlock = block.getCurrentBlock(); do { DatanodeInfo[] excluded = getExcludedNodes(); lb = locateFollowingBlock(excluded.length > 0 ? excluded : null , oldBlock); block.setCurrentBlock(lb.getBlock()); block.setNumBytes(0 ); bytesSent = 0 ; accessToken = lb.getBlockToken(); nodes = lb.getLocations(); nextStorageTypes = lb.getStorageTypes(); nextStorageIDs = lb.getStorageIDs(); success = createBlockOutputStream(nodes, nextStorageTypes, nextStorageIDs, 0L ,false ); if (!success) { dfsClient.namenode.abandonBlock(...); block.setCurrentBlock(null ); final DatanodeInfo badNode = nodes[errorState.getBadNodeIndex()]; excludedNodes.put(badNode, badNode); } } while (!success && --count >= 0 ); if (!success) throw new IOException ("Unable to create new block." ); return lb; } static LocatedBlock addBlock (DatanodeInfo[] excludedNodes, DFSClient dfsClient, String src, ExtendedBlock prevBlock, long fileId, String[] favoredNodes, EnumSet<AddBlockFlag> allocFlags) { long sleeptime = 400 ; while (true ) { try { return dfsClient.namenode.addBlock(src, dfsClient.clientName, prevBlock, excludedNodes, fileId, favoredNodes, allocFlags); } catch (RemoteException e) { Thread.sleep(sleeptime); sleeptime *= 2 ; }} else {throw e;}}}} boolean createBlockOutputStream (DatanodeInfo[] nodes, StorageType[] nodeStorageTypes, String[] nodeStorageIDs,long newGS, boolean recoveryFlag) { String firstBadLink = "" ; boolean checkRestart = false ; while (true ) { boolean result = false ; DataOutputStream out = null ; try { s = createSocketForPipeline(nodes[0 ], nodes.length, dfsClient); long writeTimeout = 480 + 5 * nodes.length; long readTimeout = 60 + 5 * nodes.length; ... out = new DataOutputStream (new BufferedOutputStream (unbufOut, param))); blockReplyStream = new DataInputStream (unbufIn); new Sender (out).writeBlock(params....); BlockOpResponseProto resp = parseFrom(...blockReplyStream); Status pipelineStatus = resp.getStatus(); firstBadLink = resp.getFirstBadLink(); if (PipelineAck.isRestartOOBStatus(pipelineStatus)) { checkRestart = true ; throw new IOException ("A datanode is restarting." ); } blockStream = out; result = true ; } catch (IOException ie) {...} if (firstBadLink.length() != 0 ) { for (int i = 0 ; i < nodes.length; i++) { if (firstBadLink.equals(nodes[i].getXferAddr())) { errorState.setBadNodeIndex(i); break ; } } } else { errorState.setBadNodeIndex(0 ); } result = false ; } finally { closeSocketAndStreamWhenFail();} return result; }}
至此, 客户端核心的写入数据的过程差不多说了, 因为客户端是用户使用最多的组件, 所以它的代码细节需要仔细阅读, 有笔误可及时联系更正.
篇幅原因, Client剩下的 接收响应ACK 的response线程, 以及写入收尾关闭流 的过程就拆分到第二篇写笔记 中.
参考资料:
官方博客/Wiki (由于很多人引用图 没有注明出处, 暂不清楚原始出处)
HDFS3.1.2官方源码 Hadoop 2.X HDFS源码剖析