今天先来简单了解一下图数据库 JanusGraph(janus 读音类 J+nes,jay 而不是 je-nes),后续简写为 janus。
更新: 这篇写的比较早,很多地方不够细致,之后全局搞明白后再重写一次
0x00.What Is Graph-Database?
讲 janus 之前,先回答两个基础问题:什么是图数据库?它与传统关系型(mysql)db 的区别是什么?
简化来说:
- 关系型数据库更擅长结构化表模型、强事务和复杂聚合;
- 图数据库更擅长关系密集场景(多跳路径、邻居扩展、关系推理);
- JanusGraph 的定位不是替代关系型数据库,而是在图关系场景提供可扩展的图引擎能力。
根据官方文档,janus是一个分布式图数据库引擎,具有以下特性:
- 支持大规模顶点与边的存储和查询
- 本身不负责持久化存储,而是借助外部存储与索引后端
- 支持事务语义与并发图查询(具体一致性表现取决于后端与部署方式)
补充: 前身是Apache的开源项目Titan.
0x01.janus架构
了解图数据库,我打算从它的整体架构,数据结构,算法结构三个方面来学习. 首先看看它的整体架构,大致分为三部分:
- 图计算框架(TinkerPop)
- 数据存储(Cassandra,HBase,BerkeleyDB)
- 索引存储(Elasticsearch,Solr,Lucene)
可以看出,janus的设计是比较模块化的,可以自行采用它支持的多种存储组合方式,以满足业务的最佳适应性.引用官方文档的图: (先需要知道OLAP,OLTP,Gremlin)

为了便于快速回忆,再补一张“逻辑分层”示意图:
flowchart TD
A["应用层: Gremlin/客户端"] --> B["JanusGraph Core"]
B --> C["查询与事务执行层"]
C --> D["存储后端: Cassandra/HBase/BerkeleyDB 等"]
C --> E["索引后端: Elasticsearch/Solr/Lucene"]
这里关于OLAP和OLTP以及Gremlin的图计算&大数据平台这不太清楚可以先跳过,后面等到学习Tinkerpop后就会了解多很多.
Gremlin
首先,大家都了解传统的sql语言,用于关系型db的各种操作.e.g (select * from stu where 1=1 or stu.name='hacker' )
再看看TinkerPop: 它制定了专用于图数据库的Gremlin语言,并定义了图中的顶点/边/属性的数据模型,并提供了以下几个重要的接口:
- 路径分析
- 点族群发现
- 子图识别
并且它支持通过 Gremlin Server 协议访问图服务,客户端可以提交 traversal 并获得结果。建议优先按 Apache TinkerPop 文档来理解 Gremlin 语义,再映射回 janus 的执行链路。
数据存储
传统关系型 db(e.g : mysql,oracle)存储和查询层一般更紧耦合,而 janus 走的是“图引擎 + 外部存储后端”模式。常见后端包括 Cassandra、HBase、BerkeleyDB JE。这个设计的核心价值是:按规模和成本灵活替换后端,而不是被单一存储绑定。
索引存储
传统我们了解的数据库引擎,比如mysql的innodb,myisam 等.基本使用的都是B+树的数据结构.对查询速度而言,从传统的桶排序,到hash表,到db中的index,本质都是索引的体现.
janus 的索引同样独立到外部 index system。实践里最常见是 Elasticsearch/Solr/Lucene:图遍历负责关系路径,索引后端负责属性检索和全文能力,二者组合更适合复杂图查询。
0x02.janus数据结构(待迁移至Schema篇)
看完了整体结构,再来看看janus本身作为图计算引擎的核心数据结构,包括传统图的vertex(点),edge(边)以及点边拥有的属性(支持多类型). 一般点作为一个对象,边作为一个关系.
从ds的角度来看,janus是一个邻接表方式存储的图,表中保存某个顶点的所有入射边.优点是遍历快(边和属性存储紧凑),缺点是邻接表的特点需要浪费一倍的存储.janus可与支持big table数据模型的存储后端,如图所示是bigtable(bt)数据模型:
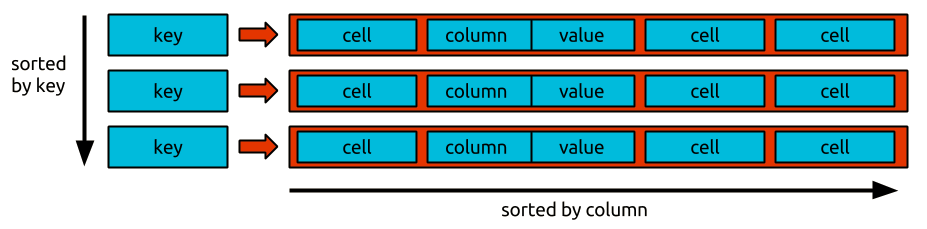
由图可知,在bt下表就是很多行的集合, 并且每行都有唯一标识的key,然后每行有很多单元(cell),每个单元又由列&值组成.cell的数量可以非常大.
这里janus对bt结构有个特别要求 : cell必须通过列(column)排序,且由列执行的cell子集必须可以高效查询. (补充: 行的按key排序没强制要求,但是如果也实现了,janus遍历速度会更快)
janus实际存储则是以下图为例,key对应是vertexID,每个cell变成了这里独立的属性&边,以便更高效的插入&删除. 每行能保存的最大单元数也就 = 顶点的边数
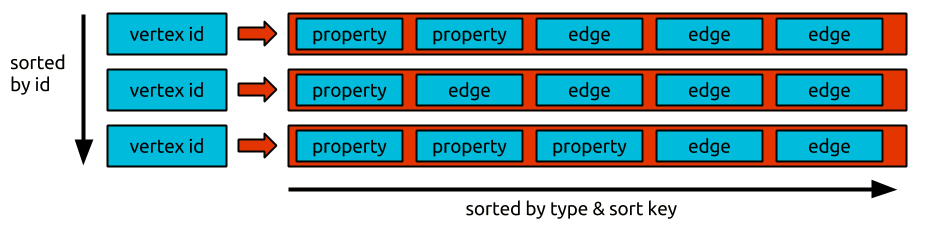
那么按照这样存储的话,之前列对应的value去哪了呢? 答案是再进一层,如图所示:

图中三种颜色方块各自代表:
- 初音蓝: 表示对schema编码压缩后的ID,以减少存储使用
- 红色: 代表一个或多个属性值,这个值也会被压缩并关联到属性key上
- 灰色: 未压缩的属性值(比如序列化后的对象)
如果是边,那么它的列实际上是由一系列属性组成的(标签ID+方向,sort key,边ID,相邻顶点ID),那么它的值是signature key+其他属性组成. (什么是签名秘钥?). 注意,从图上可知,janus并没有直接保存顶点ID ,而是保存相对邻接表的位置偏移(更省空间)
如果是属性,那么简单不少: 列是keyID,值是属性ID+属性值(这里keyID是什么?? 类似身份证号跟主键号么). 注意: 如果属性被设置为LIST,那么属性ID也会存在列中
总结:
janus的数据结构本质是来自bigtable,也就是邻接表的存储结构.由于边至少由两个顶点定义,所以肯定会被重复在邻接表中保存,存储效率会降低,但查找速率会提高.
具体的代码数据结构待补充..(java实现)
1 |
0x03.janus基本操作
1 | //因为没有单独gremlin的语法高亮,先用java代替 |
可以看出,以g 对象为一张图的核心,含有核心方法V(),inE(),outE() ,has(para1,para2), hasLable(para1) ,最后根据具体查询是往里深入还是往外发散选in(),out()方法
0x04.schema
首先如果对传统db的shcema的理解就不太清楚,参考zhihu. schema和索引&视图&标的区别理解之后再看图db的. 我简单理解就是比database低一级,是表跟各种关系的集合.
这里,每个janus都会有一个核心的概念schema .不同于传统一个数据库可以有多个schema,janus中每个janus实体只有与其对应的一个schema .这个结构由下表的几种构成(不知道我能不能把它想成是索引,表,存储过程之类的?..)(以下都建立在图实例唯一):
| schema name | definition | supported type | extension |
|---|---|---|---|
| PropertyKey | 顶点和边的属性.(类型需确定) | String,Integer,Data,UUID, |
List,Set,Single(这是什么?) |
| VertexLabel | 顶点类型 | String | |
| EdgeLabel | 边类型 | String |
schema 可以显式或隐式创建(推荐显式)。显式 schema 在团队协作、上线变更和性能调优上都更可控,尤其在图模型长期演进时价值更高。
支持的索引类型有:
等值索引(CompositeIndex): 应该是类似 1=1 and 1=2 这样的? 需指定是否唯一
混合索引(MixedIndex): 常用于全文检索、范围过滤等复杂查询,通常依赖外部索引后端能力。
然后以上四个scheama属性构成了SchemaVertex ,然后存储为edgestore??
后续更新 :单独谈Schema的本质与源码解读
0x05.存储结构
上面说的是janus自身的相关结构,再看看与它配对的存储和索引的结构(cassandra和elasticsearch,下面简称cd和es)
cd: 使用等值索引,其它结构不太明白
es: 使用混合索引,其它结构不太明白
图数据如何读写?
这也是关键的存储问题,图之后再补.
图写入:
- 生成janus对象
- 创建新的事务
- 添加点 & 边(可并行)
- 添加点/边
- 获取点标签/点内外?(getInVertex & getOutVertex)
- 事务中添加点/点外添加边?(outVertex.addEdge())
- 点/边添加属性
- 提交事务
- 遍历新增关系(addRelations) ,删除关系(deleteRelations)
- 封装mutator(突变?) & 下标更新(IndexUpdate)
- 对mutator对象操作边/下标
- 突变边?
- 突变下标?
- 事务下标新增
图读取:
- 生成janus对象
- 创新新的事务
- 获取某个点是否拥有标签/属性(
getVertex.has("name","hacker")) ,根据查询.类型以及是否有索引- 有索引
- 精准查询: 先根据cd的图下标获取边ID,然后查cd的edgeStore获取完整数据
- 模糊查询: 先根据ES的获取边ID,然后查cd的edgeStore获取完整数据
- 无索引 : 需要全遍历,查询cd的edgeStore获取完整数据
- 有索引
0x06.可视化效果
现在不管是爬虫/数据分析还是社交网络,一般单纯说技术或者json数据是没人愿意看的.所以一般会根据数据提供一个可视化的图表,那么图数据库也有类似的可视化效果,图之后补充.
0x0n.更新补充
- 本文“JanusGraph 是图数据库引擎、依赖外部存储和索引后端”的结论已按官方文档核验。
- Gremlin 语言和 traversal 模型建议以 Apache TinkerPop 官方文档为准,避免引用二手资料造成语义偏差。
- 事务一致性与索引行为会受到存储后端与部署方式影响,生产环境应做压测和一致性验证。