随着基础的铺垫,我们已经可以开始渐渐接触实际的整站环境去对web站点进行渗透了.
除了上一部分说的功能十分强大的Burpsuit. 这里还有专门的敏感文件探测工具.以及一些python的脚本运行的小自动化.
0x00. py相关环境
为什么安全跟py接触很多这里就不多解释了.依赖环境少,写的代码简洁很快.CTF线下赛不带U盘电脑也可以快速手写.之后这里补充简单py写的自动化提交脚本.(比如批量扫描+批量上传利用shell+批量获取flag)
0x01. 敏感文件探测实践
1.什么是敏感文件:

对web站点来说,数据库连接文件,配置文件,或者一些自动上传脚本都是敏感文件.常见的敏感文件类型:
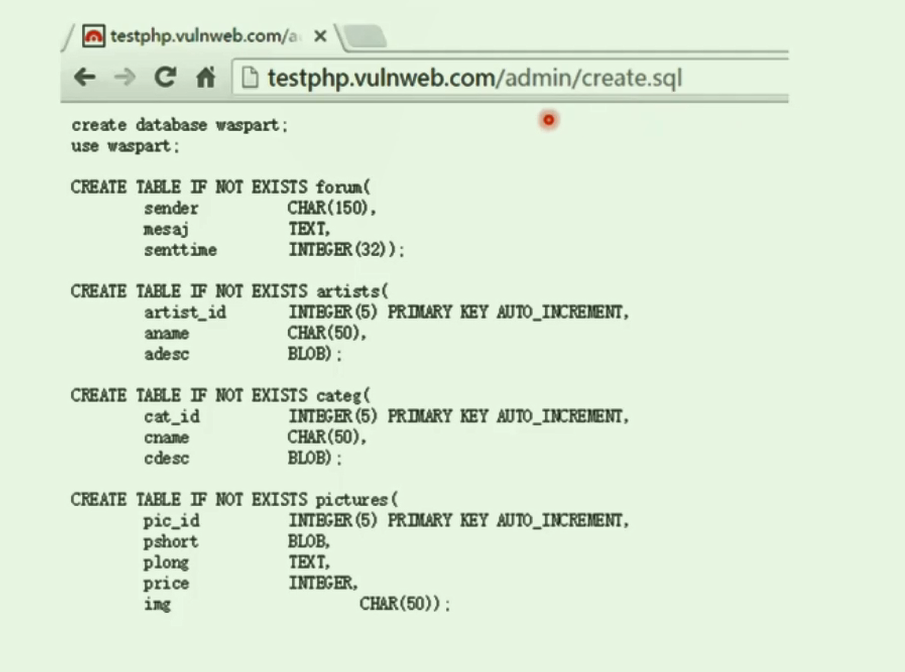
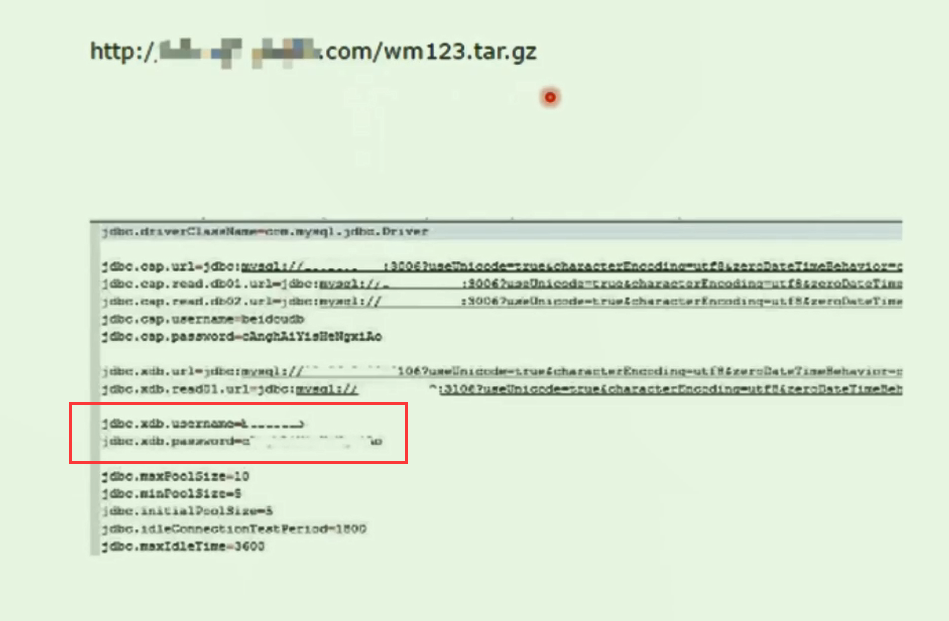
或者更常见的自动备份的文件. 爆出jdbc连接池配置. 泄露这种信息等于整体go die.
2.敏感文件探测原理
随便从一个测试安全的站点找一个登录或者注册页面(sql问题多). 然后发现url为login的时候是正常.那我们就开始尝试猜测login1,login2,admin这种
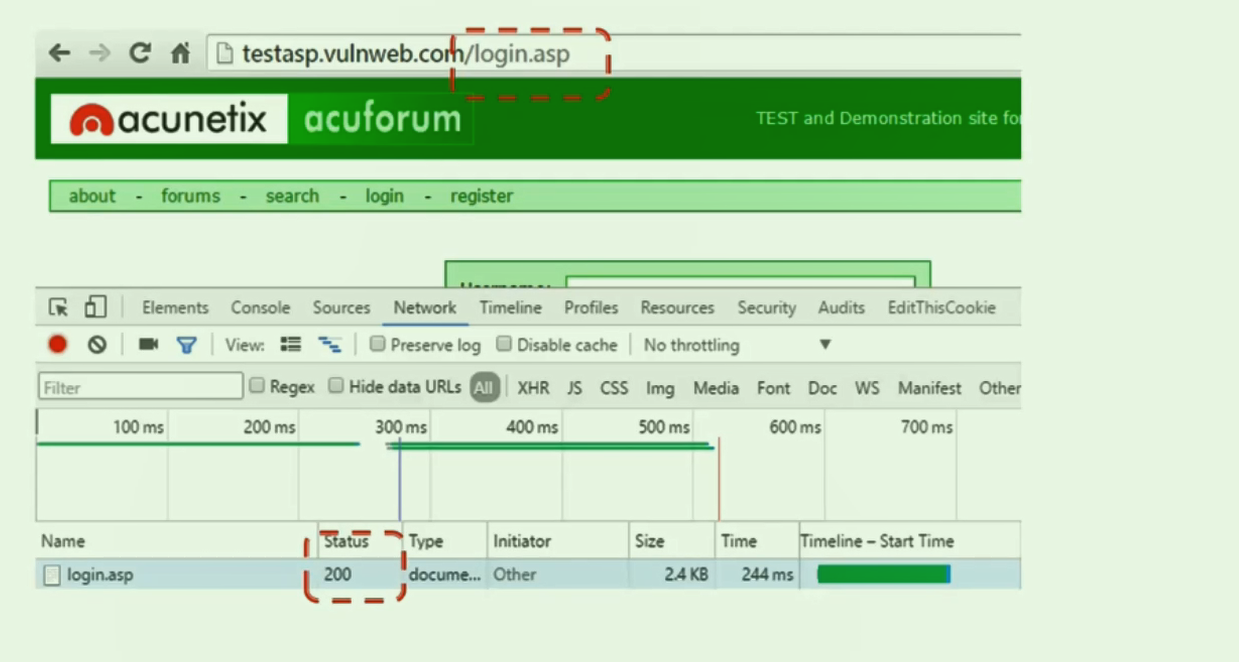
然后发现返回404.说明不存在. 有时候返回301/302的时候,说明有文件跳转,值得关注了.那么大家可能说这不是太傻了么,一个个去试文件名 or 路径名. 但是你要想常见的可能就那么多,批量工具扫描一下是很快就能搜到信息的.
3.御剑实战扫描
御剑工具是大名鼎鼎的win下敏感文件探测工具. 也不用安装.自带大量字典文件.对应不同类型网站(PHP,JSP.ASP)的常见目录. 随便列一些.
1 | /bbs/s8servu.php |
打开软件后进入批量扫描界面,然后很简单的可以上手,如果你实在判断不出网站类型可以把所有字典都丢进去.
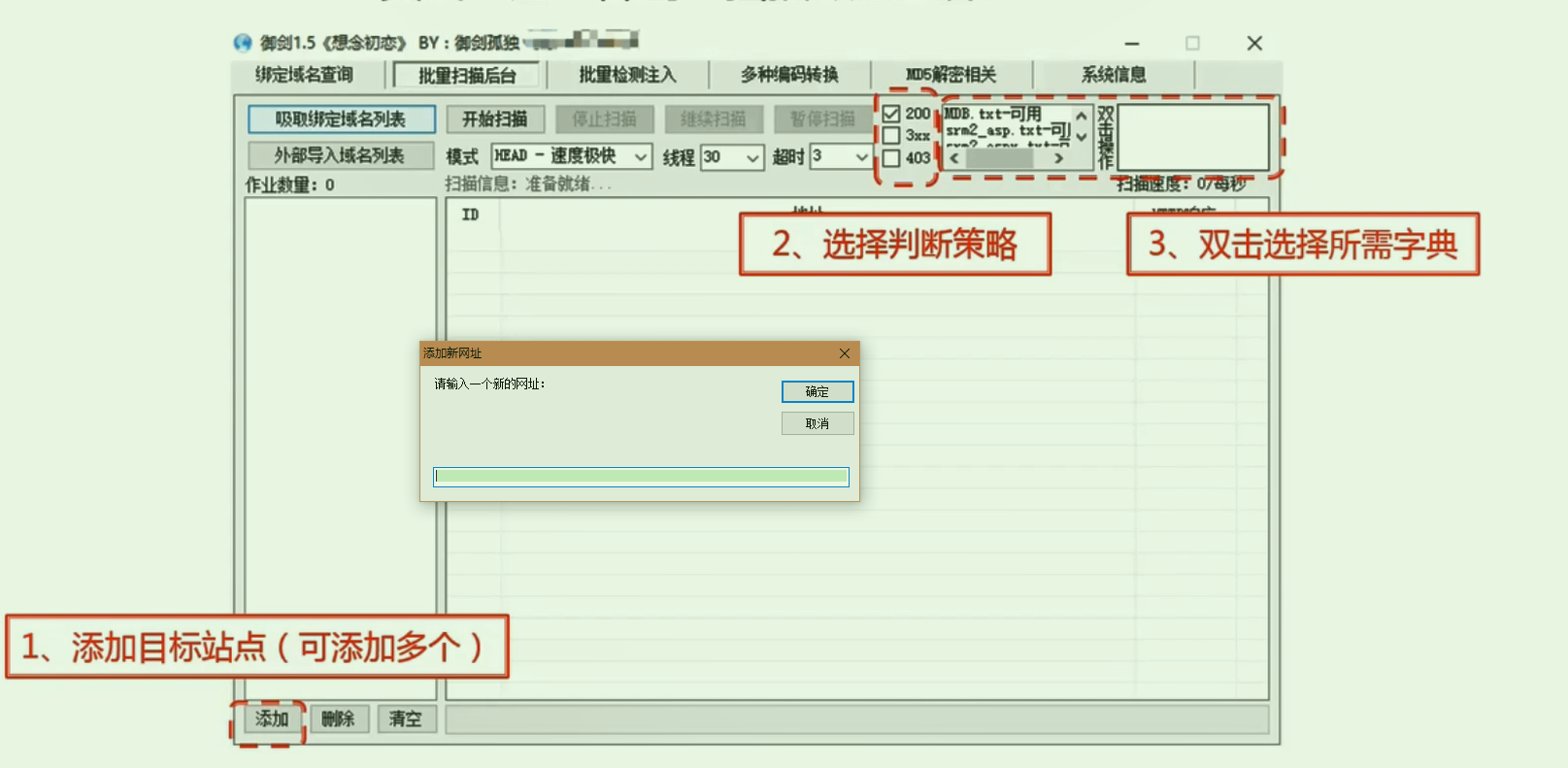
http://testjsp.vnlnweb.com , http://testphp.vnlnweb.com 以这两个为例. 参考推荐字典加入 : DIR.txt, MBD.txt,PHP.txt,JSP.txt 当然你如果确定了类型就可以少选一点. 注意模式选择尽量跑快一点,不然可能扫描时间会很长.
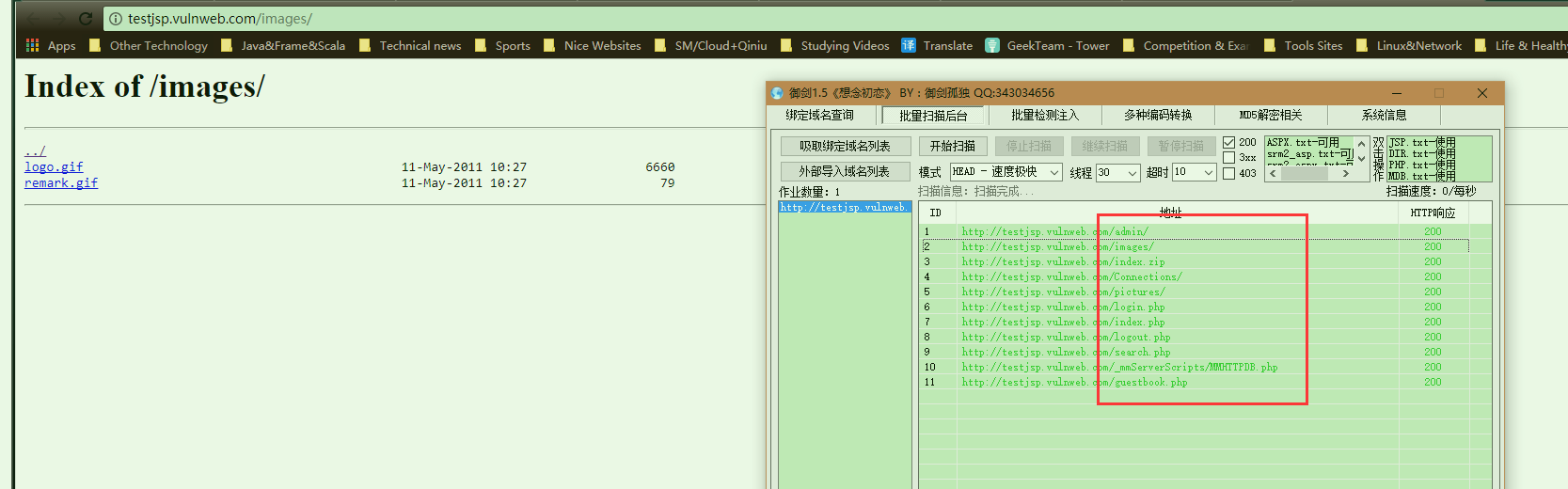
如图,扫出一堆铭感目录,然后访问之后很多可以直接访问目录下的文件,这都是非常危险的. 探测到后台就可以简单的进行爆破了 (然后我对内部项目进行了一波扫描,结果惊人….的糟糕,╮(╯▽╰)╭)
0x02. 思路探讨
上面我们给一个存在web漏洞的网址进行了简单的测试,那么我们就作为一个合格的安全人员,就应该跟script kid一样欢声笑语离开了么? 我们应该反思一下刚才的操作存在的改进之处.
字典文件过大过多时间很低.
扫描速度过快,会很快被阿里云/腾讯云等直接ban掉ip.或者记录下来. (降低速度,使用ip池)
先判断网站ip(是否阿里云/腾讯云,海内/外), php or jsp or python? 那么如何判断呢?
- 先去试试index.xxx (
比如 index.asp, index.jsp, index.php, index.aspx) ,看看是否存在. - 自己查一下还有什么很好的办法.(?–?)
- 先去试试index.xxx (
通用字典针对性太差. 如果我们扫描过程已经获取了一些信息,那么就可以进行相关字典优化了,比如大名鼎鼎的社会工程学字典. 除了软件构造,还有什么办法呢? (有的放矢,想想自己密码命名),这里用py写个小工具:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51#! /usr/bin/env python
#coding=utf-8
# 生成针对行的备份文件字典
# 搜集常见的备份文件后缀类型,以及固定的一些文件名
suffixList = ['.rar', '.zip', '.sql', '.gz', '.tar', '.bz2', '.tar.gz', '.tar.bz2', '.bak', '.dat']
keyList = ['install','INSTALL','index','INDEX','ezweb','EZWEB','flashfxp','FLASHFXP','%e6%96%b0%e5%bb%ba%e6%96%87%e4%bb%b6%e5%a4%b9','%e6%96%b0%e5%bb%ba%e6%96%87%e4%bb%b6%e5%a4%b91','New folder','backup','BACKUP','data','DATA','database','DATABASE','sql','SQL','wwwroot','WWWROOT','www','WWW','web','WEB','backup','BACKUP','HYTop','db','DB','1','2','3','4','5','6','7','8','9','10','11','12','123']
# 请输入目标URL
print "Please input the URL:"
url= raw_input()
if (url[:5] == 'http:'):
url = url[7:].strip() # get right URL
if (url[:6] == 'https:'):
url = url[8:].strip() # get right URL
numT = url.find('/')
if (numT != -1):
url = url[:numT]
# 根据URL,推测一些针对性的文件名
num1 = url.find('.')
num2 = url.find('.', num1 + 1)
keyList.append(url[num1 + 1:num2])
keyList.append(url[num1 + 1:num2].upper())
keyList.append(url) # 如www.hack.com
keyList.append(url.upper())
keyList.append(url.replace('.', '_')) # www_hack_com
keyList.append(url.replace('.', '_').upper())
keyList.append(url.replace('.', '')) # wwwhackcom
keyList.append(url.replace('.', '').upper())
keyList.append(url[num1 + 1:]) # hack.com
keyList.append(url[num1 + 1:].upper())
keyList.append(url[num1 + 1:].replace('.', '_')) # hack_com
keyList.append(url[num1 + 1:].replace('.', '_').upper())
# 生成字典列表,并写入文件"keyFiles.txt"
tempList = []
for key in keyList:
for suff in suffixList:
tempList.append(key + suff)
fobj = open("keyFiles.txt" , 'w')
for each in tempList:
each = '/'+each
fobj.write('%s%s' % (each,'\n'))
fobj.flush()
print 'OK!'